V5__基本实现Elasticsearch搜索功能
Showing
images/Docker.png
0 → 100644
{kind=link}
534.9 KB
images/Elasticsearch.png
0 → 100644
{kind=link}
1.5 MB
images/V1/V1.png
已删除
100644 → 0
{kind=link}
986.1 KB
images/V1/spotbugs.png
已删除
100644 → 0
{kind=link}
652.2 KB
images/flowChart.png
已删除
100644 → 0
{kind=link}
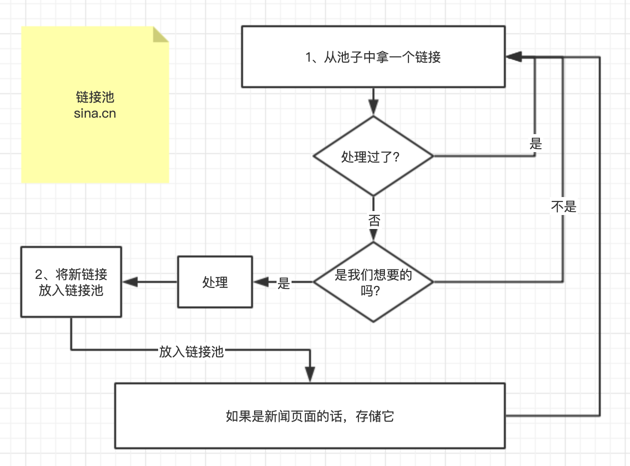
55.6 KB
images/news_database.png
0 → 100644
{kind=link}
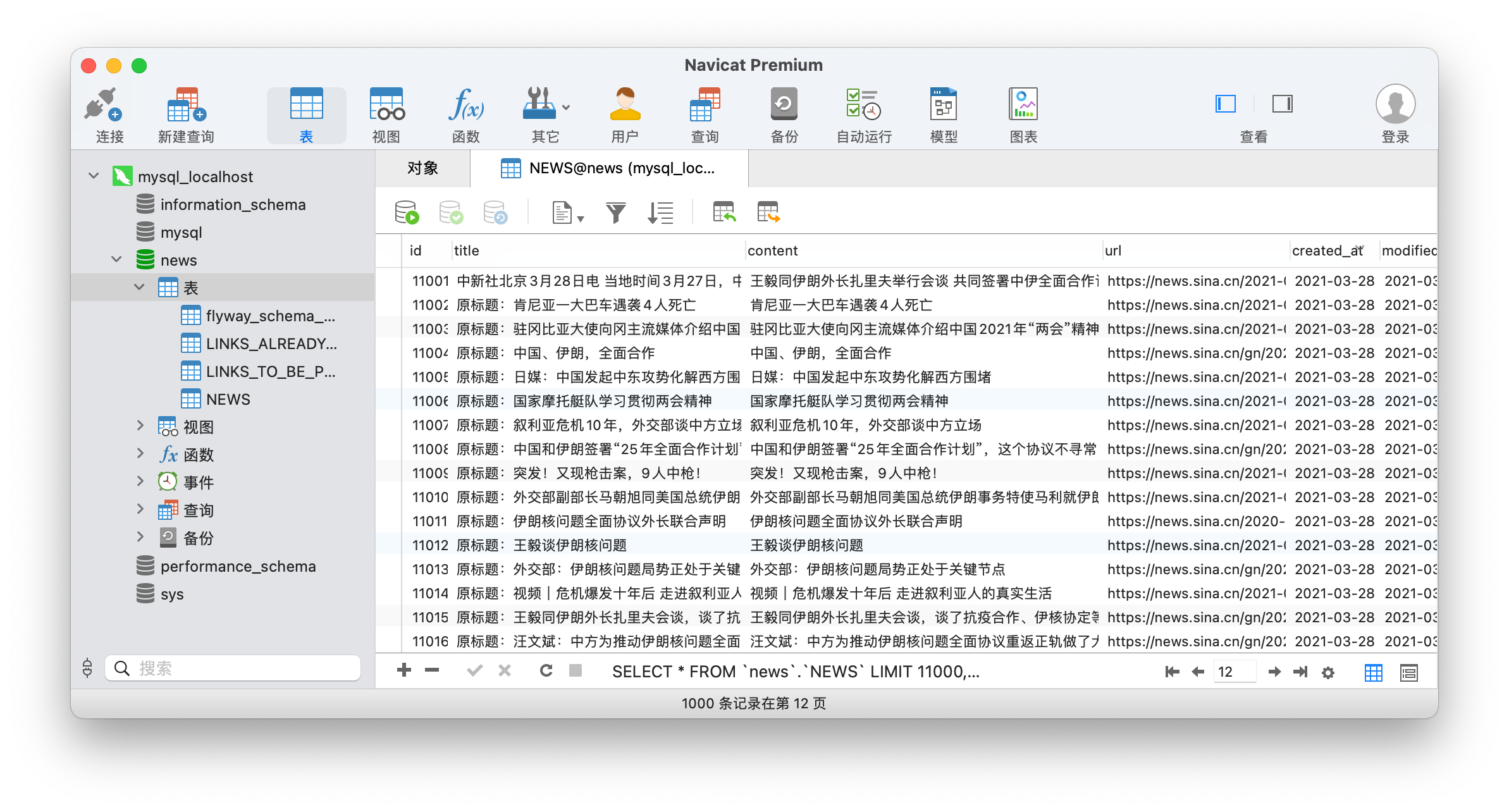
792.8 KB
images/search_code.png
0 → 100644
{kind=link}
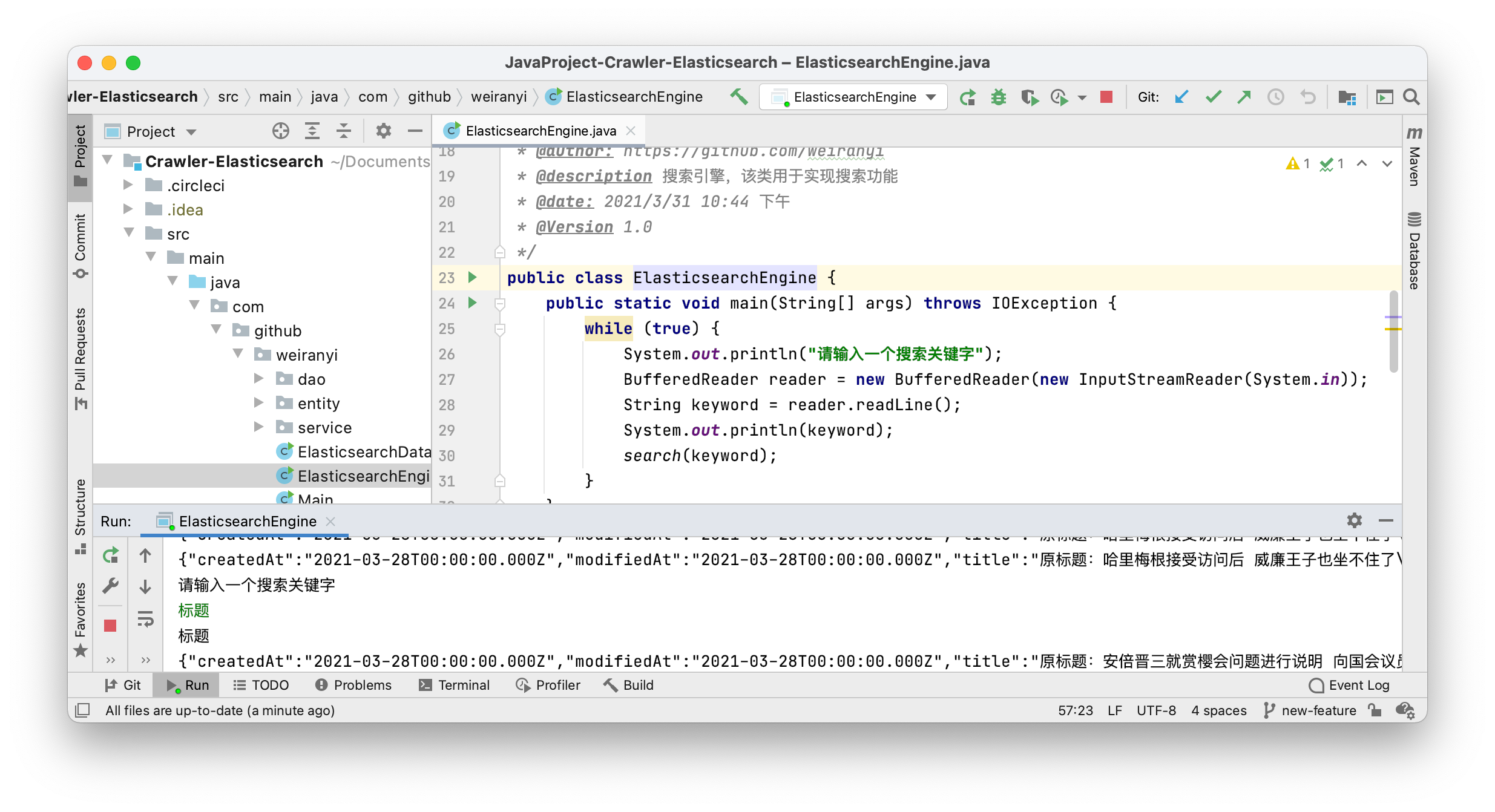
687.8 KB