



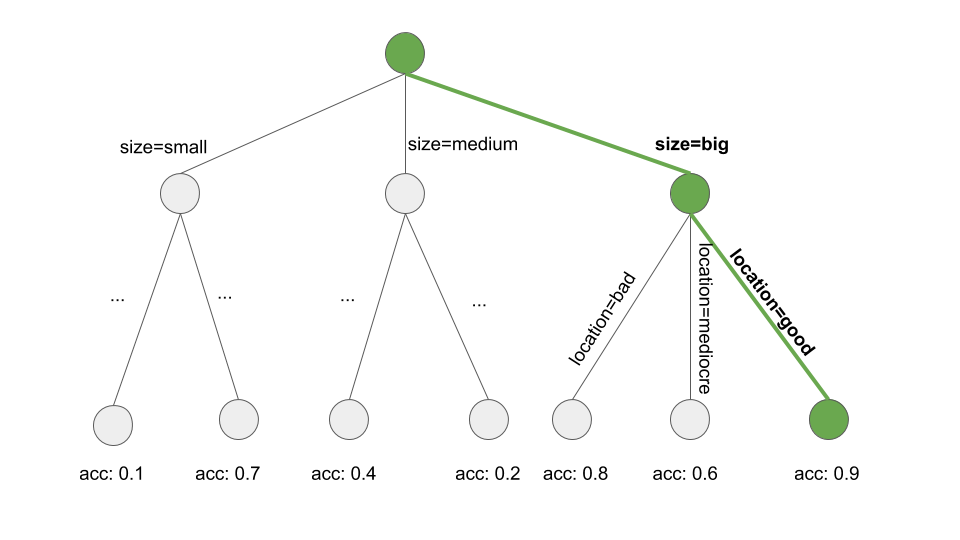
但是子集是从哪里来的呢?这很简单:Cart 采用一个特征,并确定回归任务的哪个临界点将 y 的方差最小化,或者分类任务的 y 类分布的基尼指数最小化。方差告诉我们节点中的 y 值围绕其平均值分布的程度。基尼指数告诉我们一个节点是如何“不纯”的,例如,如果所有的类都有相同的频率,那么这个节点就是不纯的,如果只有一个类存在,那么它就是最大的纯的。当节点中的数据点具有非常相似的 y 值时,方差和基尼指数最小化。因此,最佳截止点使两个结果子集在目标结果方面尽可能不同。对于分类特征,该算法尝试通过尝试不同类别分组来创建子集。在确定每个特征的最佳截止值后,算法选择将导致方差或基尼指数最佳分割的特征,并将此分割添加到树中。该算法继续此搜索并在两个新节点中递归拆分,直到达到停止条件。可能的条件是:拆分前必须在节点中的最小实例数,或必须在终端节点中的最小实例数。
但是子集是从哪里来的呢?这很简单:CART采用一个特征,并确定回归任务的哪个临界点将 y 的方差最小化,或者分类任务的 y 类分布的基尼指数最小化。方差告诉我们节点中的 y 值围绕其平均值分布的程度。基尼指数告诉我们一个节点是如何“不纯”的,例如,如果所有的类都有相同的频率,那么这个节点就是不纯的,如果只有一个类存在,那么它就是最大的纯的。当节点中的数据点具有非常相似的 y 值时,方差和基尼指数最小化。因此,最佳截止点使两个结果子集在目标结果方面尽可能不同。对于分类特征,该算法尝试通过尝试不同类别分组来创建子集。在确定每个特征的最佳截止值后,算法选择将导致方差或基尼指数最佳分割的特征,并将此分割添加到树中。该算法继续此搜索并在两个新节点中递归拆分,直到达到停止条件。可能的条件是:拆分前必须在节点中的最小实例数,或必须在终端节点中的最小实例数。


决策规则遵循一个一般的结构:如果条件满足,那么做一个特定的预测。决策规则可能是最容易解释的预测模型。它们的 if-then 结构在语义上类似于自然语言和我们的思维方式,前提是条件是由可理解的特征构建的,条件的长度很短(少数特征=与 and 组合的值对),并且没有太多规则。在编程中,编写 if-then 规则是很自然的。机器学习中的新特征是通过算法学习决策规则。
决策规则遵循一个一般的结构:如果条件满足,那么做一个特定的预测。决策规则可能是最容易解释的预测模型。它们的 IF-THEN 结构在语义上类似于自然语言和我们的思维方式,前提是条件是由可理解的特征构建的,条件的长度很短(少数`feature=与 and 组合的value对`),并且没有太多规则。在编程中,编写IF-THEN规则是很自然的。机器学习中的新特征是通过算法学习决策规则。

19. Cohen, William W.”快速有效的规则归纳。“Machine Learning Proceedings (1995). 115-123.[↩](https://christophm.github.io/interpretable-ml-book/rules.html#fnref19)
开放源代码数据挖掘国际研讨会频繁模式挖掘
20. Letham, Benjamin, et al.”使用规则和贝叶斯分析的可解释的分类器: 创建一个更好的中风预测模型。"The Annals of Applied Statistics 9.3 (2015): 1350-1371.[↩](https://christophm.github.io/interpretable-ml-book/rules.html#fnref20)
实施-OSDM'05,1–5.(2005 年)。
21. Borgelt, C. "一个FP增长算法的实现。"Proceedings of the 1st International Workshop on Open Source Data Mining Frequent Pattern Mining Implementations - OSDM ’05, 1–5. http://doi.org/10.1145/1133905.1133907 (2005).[↩](https://christophm.github.io/interpretable-ml-book/rules.html#fnref21)
22. Yang, Hongyu, Cynthia Rudin, and Margo Seltzer.“可扩展的贝叶斯规则列表。”Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.[↩](https://christophm.github.io/interpretable-ml-book/rules.html#fnref22)

这些特征是二进制的,可以表示原始特征的非常复杂的交互。选择规则最大化预测任务。规则是从协变量矩阵 X 自动生成的。您可以简单地将规则视为基于原始特征的新特征。
**第二步:稀疏线性模型**
在步骤 1 中有很多规则。由于第一步只能被视为特征转换,因此您仍然没有完成模型的拟合。此外,您还希望减少规则的数量。除了规则之外,原始数据集中的所有“原始”特征也将用于稀疏线性模型。每一条规则和每一个原始特征都成为线性模型中的一个特征,并得到一个权重估计。添加原始特征是因为树在表示 y 和 x 之间的简单线性关系时失败。在训练稀疏线性模型之前,我们先对原始特征进行 Winsorize,以便它们对异常值更为强大:\[l_j^*(x_j)=min(\delta_j^+,max(\delta_j^-,x_j))\]
\[L_j(x_j)=0.4\cdot l ^*_j(x_j)/std(l ^*_j(x_j))\]
在步骤 1 中有很多规则。由于第一步只能被视为特征转换,因此您仍然没有完成模型的拟合。此外,您还希望减少规则的数量。除了规则之外,原始数据集中的所有“原始”特征也将用于稀疏线性模型。每一条规则和每一个原始特征都成为线性模型中的一个特征,并得到一个权重估计。添加原始特征是因为树在表示 y 和 x 之间的简单线性关系时失败。在训练稀疏线性模型之前,我们先对原始特征进行缩尾调整,以便它们对异常值更为强大:
Rulefit 算法由 Fokkema 和 Christoffersen(2017)在 R 中实现,您可以找到
RuleFit 算法由 Fokkema 和 Christoffersen(2017)在 R 中实现,您可以找到[Python version on Github](https://github.com/christophM/rulefit)。
一个非常相似的框架是一个 python 模块,它也从集合中提取规则。它在学习最终规则的方式上有所不同:首先,skope 规则根据回忆和精度阈值删除性能低下的规则。然后,根据逻辑项(变量+大/小运算符)的多样性和规则的性能(F1 分数)执行选择,删除重复的和类似的规则。最后一步并不依赖于使用 lasso,而是只考虑现成的 f1 分数和构成规则的逻辑术语。
一个非常相似的框架是[skope-rules](https://github.com/scikit-learn-contrib/skope-rules),一个 也可以从集合中提取规则python 模块。它在学习最终规则的方式上有所不同:首先,skope 规则根据回忆和精度阈值删除性能低下的规则。然后,根据逻辑项(变量+大/小运算符)的多样性和规则的性能(F1 分数)执行选择,删除重复的和类似的规则。最后一步并不依赖于使用 Lasso,而是只考虑现成的 F1 分数和构成规则的逻辑术语。
-----
\1. Friedman、Jerome H 和 Bogdan E Popescu。“通过规则集合进行预测性学习。”应用统计学的名称。Jstor,916–54。(2008 年)。
\2. Fokkema、Marjolein 和 Benjamin Christoffersen。“预:预测规则集合”。(2017 年)。
24. Friedman、Jerome H 和 Bogdan E Popescu。“通过规则集合进行预测性学习。”应用统计学的名称。JSTOR,916–54。(2008 年)。[↩](https://christophm.github.io/interpretable-ml-book/rulefit.html#fnref24)
4.7 其他可解释模型
25. Fokkema、Marjolein 和 Benjamin Christoffersen。“预:预测规则集合”。[https://CRAN.R-project.org/package=pre](https://cran.r-project.org/package=pre)(2017 年)。[↩](https://christophm.github.io/interpretable-ml-book/rulefit.html#fnref25)
此外,由于模型本身是局部的,没有显式学习的全局权重或结构,因此缺乏全局模型的可解释性。也许在地方一级可以解释?要解释预测,您总是可以检索用于预测的 k 个邻居。模型是否可解释完全取决于您能否“解释”数据集中的单个实例。如果一个实例包含成百上千个特征,那么它就不可解释了,我会争辩。但是,如果您没有一些特征或将实例简化为最重要的特征的方法,那么展示 K 最近的邻居可以为您提供很好的解释。
\ No newline at end of file
此外,由于模型本身是局部的,没有显式学习的全局权重或结构,因此缺乏全局模型的可解释性。也许在地方一级可以解释?要解释预测,您总是可以检索用于预测的 k 个邻居。模型是否可解释完全取决于您能否“解释”数据集中的单个实例。如果一个实例包含成百上千个特征,那么它就不可解释了,我会争辩。但是,如果您没有一些特征或将实例简化为最重要的特征的方法,那么展示 K近邻可以为您提供很好的解释。