
简介
一个用于提取简体中文字符串中省,市和区并能够进行映射,检验和简单绘图的python模块。
举个例子:
["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区"]
↓ 转换
|省 |市 |区 |地址 |
|上海市|上海市|徐汇区|虹漕路461号58号楼5楼 |
|福建省|泉州市|洛江区|万安塘西工业区 |注:“地址”列代表去除了省市区之后的具体地址
安装说明
代码目前仅仅支持python3
pip install cpca
注:cpca是chinese province city area的缩写
常见安装错误:
有的朋友在我的博客中反映他们在使用的时候会报如下错误:
ModuleNotFoundError: No module named 'jieba'可能是因为某种原因,依赖未能成功的安装上去,这个时候则需要手动使用pip install jieba命令进行安装。
如果觉得本模块对你有用的话,施舍个star,谢谢。
中国三级行政区划分(爬取自中华人民共和国民政局全国行政区划查询平台)
数据文件在为cpca/resources/pca.csv,数据为2019年2月20日在官网上爬取的最新权威数据
Get Started
分词模式:
本模块中最主要的方法是cpca.transform,该方法可以输入任意的可迭代类型(如list,pandas的Series类型等),然后将其转换为一个DataFrame,下面演示一个最为简单的使用方法:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str)
df输出的结果为:
省 市 区 地址
0 上海市 上海市 徐汇区 虹漕路461号58号楼5楼
1 福建省 泉州市 洛江区 万安塘西工业区
2 北京市 北京市 朝阳区 北苑华贸城注:程序输出的df是一个Pandas的DataFrame类型变量,DataFrame可以非常轻易地转化为csv或者excel文件,如果你对DataFrame不熟悉的话,可以参考Pandas的官方文档:http://pandas.pydata.org/pandas-docs/version/0.20/dsintro.html#dataframe
,或者往下翻到"示例与测试用例"大标题,那里我也展示了DataFrame的拼接与转换成csv文件的操作。
如果你想获知程序是从字符串的那个位置提取出省市区名的,可以添加一个pos_sensitive=True参数:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str, pos_sensitive=True)
df输出如下:
省 市 区 地址 省_pos 市_pos 区_pos
0 上海市 上海市 徐汇区 虹漕路461号58号楼5楼 -1 -1 0
1 福建省 泉州市 洛江区 万安塘西工业区 -1 0 3
2 北京市 北京市 朝阳区 北苑华贸城 -1 -1 0其中省_pos,市_pos和区_pos三列大于-1的部分就代表提取的位置。-1则表明这个字段是靠程序推断出来的,抑或没能提取出来。
默认情况下transform方法的cut参数为True,即采用分词匹配的方式,这种方式速度比较快,但是准确率可能会比较低,如果追求准确率而不追求速度的话,建议将cut设为False(全文模式),具体见下一小节。
尝试着对代码稍加修改(其实就是将transform方法的umap参数置为空字典):
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str, umap={})
df会发现输出变为:
省 市 区 地址
0 上海市 上海市 徐汇区 虹漕路461号58号楼5楼
1 福建省 泉州市 洛江区 万安塘西工业区
2 朝阳区 北苑华贸城发现这种情况的原因是中国其实不止一个“朝阳区”,除了北京市有一个“朝阳区”外,长春市也有一个“朝阳区”,这样的话,程序就不知道该把“朝阳区”映射到哪个市。之所以前一段程序能够成功地将“朝阳区”映射成“北京市”,是因为当你不传umap参数的时候,会默认传一个笔者推荐的字典,其内容如下(在cpca.py中):
myumap = {'南关区': '长春市',
'南山区': '深圳市',
'宝山区': '上海市',
'市辖区': '东莞市',
'普陀区': '上海市',
'朝阳区': '北京市',
'河东区': '天津市',
'白云区': '广州市',
'西湖区': '杭州市',
'铁西区': '沈阳市'}你会发现,其中指定了将"朝阳区"映射到北京市,因为笔者在测试数据中发现, 数据中的"朝阳区"基本上都是指北京市那个"朝阳区" (原因可能是北京市的"朝阳区"的经济以及知名度要远比长春市的那个"朝阳区"发达)。 当然,默认的这个umap并没有囊括中国所有的重名区,必要的时候需要自己定义。
看看下面一个例子:
location_str = ["江苏省鼓楼区软件大道89号"]
import cpca
df = cpca.transform(location_str)
df输出结果为:
省 市 区 地址
0 江苏省 鼓楼区 软件大道89号可以看到,市没有被成功提取出来,并且还会产生一个警告信息:
WARNING:root:鼓楼区 无法映射, 建议添加进umap中如果想要关闭这个警告信息,可以在调用transform函数时将open_warning置位False
当程序发现重名区并且不知道将其映射到哪一个市时,会将其加入警告信息, 提示用户最好根据数据给它指定一个市进行映射。
这里无法提取的原因是江苏省南京市有一个鼓楼区,江苏省徐州市也有一个鼓楼区, 程序无法知道这个鼓楼区是南京市的还是徐州市的。
通过数据接口你可以发现这个事实:
import cpca
cpca.province_area_map.get_relational_addrs(('江苏省', '鼓楼区'))输出:
[('江苏省', '南京市', '鼓楼区'), ('江苏省', '徐州市', '鼓楼区')]如果你想要让“鼓楼区”只映射到南京市的话,在transform方法中加入umap参数指定
映射即可:
location_str = ["江苏省鼓楼区软件大道89号"]
import cpca
df = cpca.transform(location_str, umap={"鼓楼区":"南京市"})
df输出结果:
省 市 区 地址
0 江苏省 南京市 鼓楼区 软件大道89号`再看下面一个例子:
location_str = ["福建省鼓楼区软件大道89号"]
import cpca
df = cpca.transform(location_str)
df输出结果为:
省 市 区 地址
0 福建省 福州市 鼓楼区 软件大道89号这里就可以成功将“福州市”识别出来,因为在福建省,只有福州市有鼓楼区。
好在中国只有在三级行政区存在重名问题,二级与一级行政区的名称都是唯一的。
有的时候为了方便concat,想要自定义输出表的index,可以选择使用transform函数的index参数(这个参数只要保证长度和data相同即可,可以是list或者pandas中相关的类型),示例如下:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str, index=["2018年","2017年","2016年"])
df输出结果:
省 市 区 地址
2018年 上海市 上海市 徐汇区 虹漕路461号58号楼5楼
2017年 福建省 泉州市 洛江区 万安塘西工业区
2016年 北京市 北京市 朝阳区 北苑华贸城全文模式:
这个模式的出现是为解决issue #11 所提到的问题。
jieba分词并不能百分之百保证分词的正确性,在分词错误的情况下会造成奇怪的结果,比如下面:
location_str = ["浙江省杭州市下城区青云街40号3楼"]
import cpca
df = cpca.transform(location_str)
df输出的结果为:
省 市 区 地址
0 浙江省 杭州市 城区 下城区青云街40号3楼这种诡异的结果是因为jieba本身就将词给分错了,所以我们引入了全文模式,不进行分词,直接全文匹配,使用方法如下:
location_str = ["浙江省杭州市下城区青云街40号3楼"]
import cpca
df = cpca.transform(location_str, cut=False)
df结果如下:
省 市 区 地址
0 浙江省 杭州市 下城区 青云街40号3楼这下就完全正确了,不过全文匹配模式会造成匹配效率低下, 我默认会向前看8个字符(对应transform中的lookahead参数默认值为8), 这个是比较保守的,因为有的地名会比较长(比如“新疆维吾尔族自治区”),如果你的地址库中都是些短小的省市区名的话, 可以选择将lookahead设置得小一点,比如:
location_str = ["浙江省杭州市下城区青云街40号3楼"]
import cpca
df = cpca.transform(location_str, cut=False, lookahead=3)
df输出结果和上面是一样的。
再举一个例子,这个例子经测试只有使用全文匹配才能匹配出地名,:
import cpca
cpca.transform(["11月15日早上9点到11月18日下班前王大猫。在观山湖区"], cut=False, pos_sensitive=True)输出为:
省 市 区 地址 省_pos 市_pos 区_pos
0 贵州省 贵阳市 观山湖区 11月15日早上9点到11月18日下班前王大猫。在观山湖区 -1 -1 25绘图:
模块中还自带一些简单绘图工具,可以在地图上将上面输出的数据以热力图的形式画出来.
这个工具依赖folium,为了减小本模块的体积,所以并不会预装这个依赖,在使用之前请使用pip install folium .
代码如下:
from cpca import drawer
#df为上一段代码输出的df
drawer.draw_locations(df, "df.html")这一段代码运行结束后会在运行代码的当前目录下生成一个df.html文件,用浏览器打开即可看到 绘制好的地图(如果某条数据'省','市'或'区'字段有缺,则会忽略该条数据不进行绘制),速度会比较慢,需要耐心等待,绘制的图像如下:

还有更多的绘图工具请参考文档的大标题为“示例与测试用例”的部分。
到这里就你就已经知道了本模块的基本使用了,接下来我会阐明更多细节。
数据接口
爬取的原始数据位于cpca/resources/pca.csv ,模块会在启动时读取该文件并将其中的 数据转换为需要的数据结构。
通过以下方法可以访问本模块内部的数据结构:
## 查询经纬度信息
from cpca import latlng
latlng[('北京市','北京市','朝阳区')] #输出('39.95895316640668', '116.52169489108084')
## 查询含有"鼓楼区"的全部地址
from cpca import area_map
area_map.get_relational_addrs('鼓楼区') #[('江苏省', '南京市', '鼓楼区'), ('江苏省', '徐州市', '鼓楼区'), ('福建省', '福州市', '鼓楼区'), ('河南省', '开封市', '鼓楼区')]
#### 注: city_map可以用来查询含有某个市的全部地址, province_map可以用来查询含有某个省的全部地址
## 查询含有"江苏省", "鼓楼区"的全部地址
from cpca import province_area_map
province_area_map.get_relational_addrs(('江苏省', '鼓楼区')) # [('江苏省', '南京市', '鼓楼区'), ('江苏省', '徐州市', '鼓楼区')]关于匹配与映射的细节
为了保证匹配与映射的正确性,我做了很多细节上的处理,如果在使用本模块的过程中遇到困惑可以参考这里。
- 能够匹配到省或者市的缩写,比如将"北京市"缩写为"北京","江苏省"缩写为"江苏",依旧能够匹配到并且能够自动补全为全称,示例代码如下:
#测试数据
location_strs = ["江苏省南京市鼓楼区256号", "江苏南京鼓楼区256号"]
import cpca
df = cpca.transform(location_strs)
df输出的结果为:
区 市 省 地址
0 鼓楼区 南京市 江苏省 256号
1 鼓楼区 南京市 江苏省 256号我不仅做了这些缩写情况处理,还处理了诸如"新疆维吾尔族自治区"缩写为"新疆","西藏藏族自治区"缩写为"西藏"等情况,如下:
import cpca
location_str = ["新疆","广西","宁夏","西藏"]
df = cpca.transform(location_str)
df输出:
省 市 区 地址
0 新疆维吾尔自治区
1 广西壮族自治区
2 宁夏回族自治区
3 西藏自治区 具体的这些缩写的处理位于代码的cpca/__init__.py的78行到第96行
- 以先出现的地名为准
#测试数据
location_strs = ["江苏省南京市徐州市鼓楼区256号"]
import cpca
df = cpca.transform(location_strs)
df后出现的徐州市并没有被提取。
- 最后一列的地址字段,本质上是原字符串去除了开头的地名之后的字符串,如果字符串中间出现地名的话是不会被摘去的
再看之前的一个例子:
import cpca
cpca.transform(["11月15日早上9点到11月18日下班前王大猫。在观山湖区"], cut=False, pos_sensitive=True)输出为:
省 市 区 地址 省_pos 市_pos 区_pos
0 贵州省 贵阳市 观山湖区 11月15日早上9点到11月18日下班前王大猫。在观山湖区 -1 -1 25可以看到整个省市区三级地址都是从"观山湖区"这几个字符提取出来,但是因为它在句尾,在"地址"列中 并没有将其摘去,如果在句中的话也同样不会摘去的。
- 本模块的映射功能仅限:如果区对应的市是唯一的话,能够由区映射到市;能够由市映射到省级;已知省和区,如果该区在省内是唯一的话,能够映射出市
示例与测试用例
本仓库放了一份大约一万多条地址描述信息tests/addr.csv ,用于测试模块,测试代码如下:
测试基本功能:
#读取数据
import pandas as pd
origin = pd.read_csv("tests/addr.csv")
#转换
import cpca
addr_df = cpca.transform(origin["原始地址"])
#输出
processed = pd.concat([origin, addr_df], axis=1)
processed.to_csv("processed.csv", index=False, encoding="utf-8")注意以上代码运行结束后会打印一句warnning,这些warnning是因为程序无法确定某个区县属于哪个市(因为这些区县存在重名问题而且在umap中又没有指定它属于哪一个市).
测试绘图函数1(绘制热力图):
模块中绘制热力图的函数是基于folium编写的,为了减小模块体积,在安装模块时没有安装这些绘图库的依赖,如果需要使用这个函数的话,需要先使用pip install folium 安装folium
from cpca import drawer
#processed为上一段代码的processed
drawer.draw_locations(processed, "processed.html")用浏览器打开"processed.html"文件,发现绘制的局部图像如下(在国内folium的地图显示速度比较慢,所以需要耐心等待地图显示):
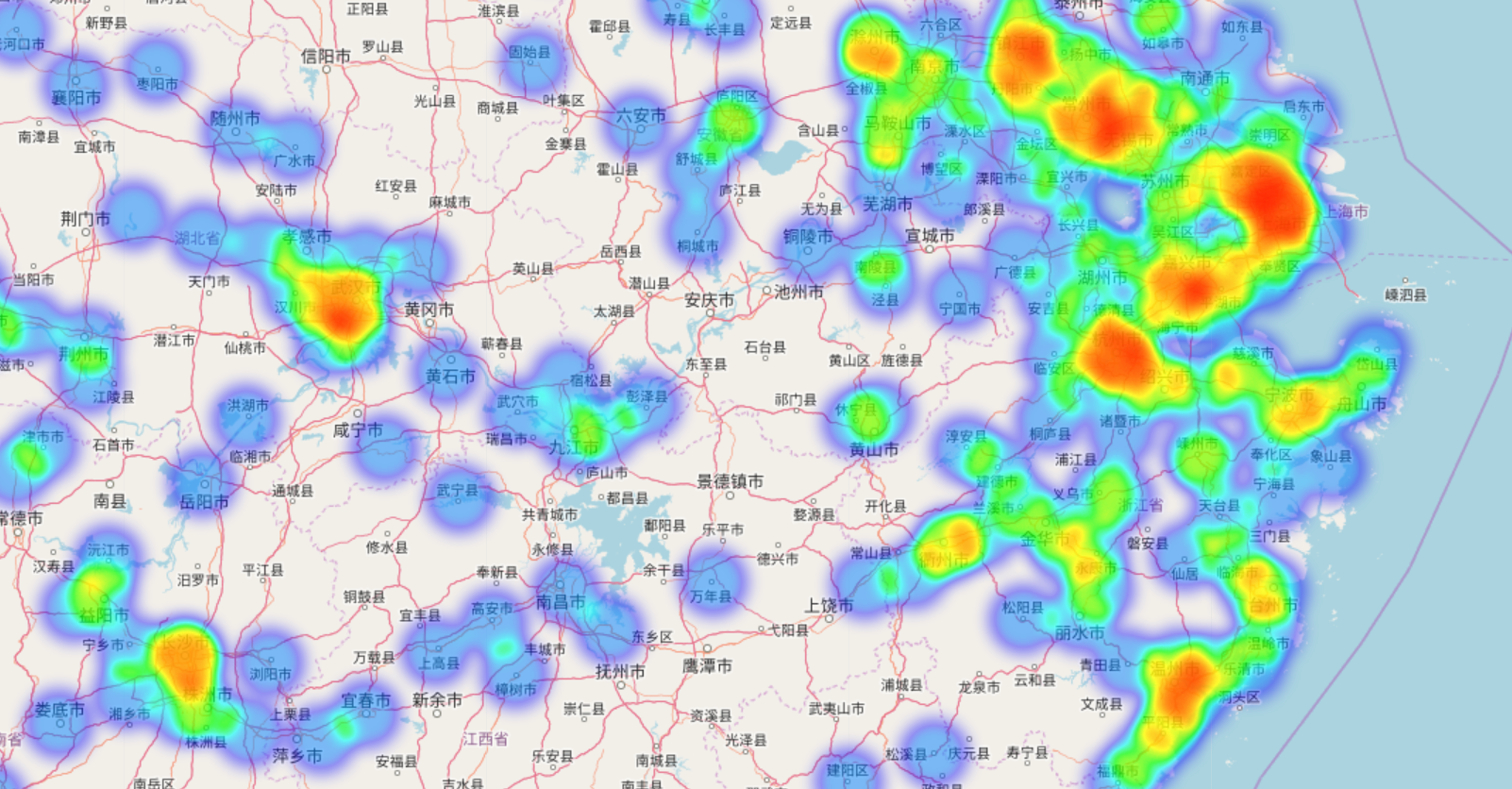
(注意:本模块在绘图时,只绘制那些可以精确地匹配到省市区的地址,对于省市区有一个或多个字段缺失的则会直接忽略)
测试绘图函数2(绘制echarts热力图):
因为在国内folium的地图显示速度太慢了,所以添加了echarts的热力图绘图函数.
在使用本函数之前需要先用如下命令安装它的依赖(为了减少本模块的体积,所以这些依赖不会被自动安装):
pip install pyecharts
pip install echarts-countries-pypkg
pip install pyecharts-snapshot示例代码如下,仍然使用之前的测试数据生成的processed变量:
from cpca import drawer
drawer.echarts_draw(processed, "echarts.html")该接口的更多参数及其含义如下:
def echarts_draw(locations, file_path, title="地域分布图"
, subtitle="location distribute"):
"""
生成地域分布的echarts热力图的html文件.
:param locations: 样本的省市区, pandas的dataframe类型.
:param file_path: 生成的html文件路径.
:param title: 图表的标题
:param subtitle: 图表的子标题
"""然后会在当前目录下生成一个echarts.html文件,用浏览器打开后即可看到图像:

测试绘图函数3(绘制分类信息图):
在使用本函数之前需要安装的依赖同上一个绘图函数,如果你是跳过了前面的直接读到这里的话,务必向上翻看一下。
样本分类绘制函数,通过额外传入一个样本的分类信息,能够在地图上以不同的颜色画出属于不同分类的样本散点图,以下代码以“省”作为类别信息绘制分类散点图(可以看到,属于不同省的样本被以不同的颜色标记了出来,这里以“省”作为分类标准只是举个例子,实际应用中可以选取更加有实际意义的分类指标):
from cpca import drawer
drawer.echarts_cate_draw(processed, processed["省"], "echarts_cate.html")然后会在当前目录下生成一个echarts_cate.html文件,用浏览器打开后即可看到图像:

该接口更多的参数及其含义如下:
def echarts_cate_draw(locations, labels, file_path, title="地域分布图", subtitle="location distribute",
point_size=7):
"""
依据分类生成地域分布的echarts散点图的html文件.
:param locations: 样本的省市区, pandas的dataframe类型.
:param labels: 长度必须和locations相等, 代表每个样本所属的分类.
:param file_path: 生成的html文件路径.
:param title: 图表的标题
:param subtitle: 图表的子标题
:param point_size: 每个散点的大小
"""How to Contribute
项目代码还很粗糙,如果大家对代码有所改进,欢迎提交回本项目 ,在提交之前,注意以下两点:
- 在
tests添加相应的单元测试 - 使用
python setup.py test来运行所有单元测试,确保所有单测都是通过的
之后即可提交PR
END
如果大家在使用过程中发现一些匹配错误的地址,欢迎提issue来帮助我收集这些错误用例和改善算法,毕竟笔者手头数据有限,难以考虑到所有边界情况
下一步开发规划
- 解决路名被误识别为省市名的问题
- 增加定期从民政局官网爬取最新省市区划分的功能