Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
cs61b-textbook-zh
提交
12243b1d
C
cs61b-textbook-zh
项目概览
OpenDocCN
/
cs61b-textbook-zh
通知
3
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
cs61b-textbook-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
12243b1d
编写于
5月 12, 2019
作者:
A
Abel-Huang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
初稿
上级
99a3a86a
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
36 addition
and
133 deletion
+36
-133
.gitignore
.gitignore
+3
-0
zh/7.md
zh/7.md
+33
-133
zh/img/figure_7_1.jpg
zh/img/figure_7_1.jpg
+0
-0
zh/img/figure_7_2_1.jpg
zh/img/figure_7_2_1.jpg
+0
-0
zh/img/figure_7_2_2.jpg
zh/img/figure_7_2_2.jpg
+0
-0
未找到文件。
.gitignore
浏览文件 @
12243b1d
...
...
@@ -113,3 +113,6 @@ Thumbs.db
# word
~$*.docx
~$*.doc
# .idea
.idea/
zh/7.md
浏览文件 @
12243b1d
...
...
@@ -2,21 +2,21 @@
> 译者:[Abel-Huang](https://github.com/Abel-Huang)
有序数组和二叉搜索树能更快的
查找是否存在更大(或更小)的元素这样的问题。堆适用于查找最大元素问题。
然而有时候我们只对集合中是否存在某个特定元素感兴趣 —— 或者说,查找集合中是否存在与该元素相等的元素。
有序数组和二叉搜索树能更快的
解决集合中是否存在更大(或更小)的元素这样的问题;堆适用于查找集合中最大元素问题。
然而有时候我们只对集合中是否存在某个特定元素感兴趣 —— 或者说,查找集合中是否存在与该元素相等的元素。
再次思考1.3.1节中的程序
`isIn`
-- 在一个有序数组中进行线性查找。这个算法非常耗时,时间复杂度近似为N,每个元素的数量会被存储在搜索数组中。如果我们能够降低这个N,就可以加速算法。降低N的一种方式我们可以将被搜索的元素集合分成一些数字M,将他们划分成不相交的子集,并且找到方法快速的找到正确的子集。通过在键的子集之间进行或多或少的均匀划分,我们可以减小搜索所需的时间,平均值为N/M。二分查找的递归实现(1.3.1节
`isInB`
程序)就是M=2的场景。如果我们更进一步考虑,为任意情况下的N选择一个合适的M,那么查找一个元素所花费的时间会近似为
一个常数。
再次思考1.3.1节中的程序
`isIn`
-- 在一个有序数组中进行线性查找,查找某个元素是否存在于这个集合中。这个算法非常耗时,时间复杂度近似为N,这个N是存储在搜索数组中待搜索元素的数量。如果我们能够降低这个N,就可以加速这个算法。其中一种方式我们可以将被搜索的元素集合划分成M个不相交的子集,找到一种快速的方法定位到被查找元素所在的子集。通常情况下查找的元素不仅仅是一个整数,更常见的情况会是一个对象,查找一般会以对象的某个部分(一般为对象的某个属性)进行,这部分就是关键字(key)。通过将元素的集合或多或少的均匀划分为键的子集,我们可以有效的减少搜索所需的时间,平均值一般为N/M,在实际使用中,我们通常把这个子集称之为桶(bucket),整个哈希表就是由一系列这样的桶组成。二分查找的递归实现(1.3.1节
`isInB`
程序)就是在M=2的场景。如果我们进一步考虑,对于任意规模下的N选择一个合适的M值,那么查找一个元素所花费的时间会近似于
一个常数。
困难就在于找到一种尽可能快的方法来搜索到我们需要的键集合的子集。这种方法必须保证一致性,因为无论何时去调用搜索时必须得到最初选择的子集。也就是说,必须存在一种被称为哈希函数(hashing function)的函数,将所有将要被搜索的键集合映射到值为0到M-1的范围内
。
现在问题就在于找到一种尽可能快的方法定位键所在的桶。这种方法必须保证一致性,无论何时去调用这个方法必须得到最初选择的桶。也就是说,必须存在一种将所有将要被搜索的键集合映射到值为0到M-1的范围内桶的函数,这种函数称为哈希函数(hashing function)
。
## 7.1 链地址法
一旦我们
拥有一个哈希函数,我们必须还要用一种方式来表示一个子集合。或许最简单的表达形式就是使用链表,在哈希表文献中已知的做法就是链地址法(chaining)。Java标准库中的
`HashSet`
就是使用这种方法,参见图7.1的说明。更常见的是,哈希表显示为映射,例如标准库中
`java.util.Map`
接口的实现。子集中不仅包含有这些关键字,并且应该通过索引这些关键字以表达方式同样的支持更多的额外信息。图7.2展示了JDK中类
`java.util.HashMap`
的部分可能实现形式,这个类自身
是
`Map`
接口的一个具体实现。
一旦我们
找到这样的哈希函数,我们必须还要用一种方式来表示一个桶的集合。或许最简单的表达形式就是使用链表,在哈希表相关的资料中这种方法被称为
*链地址法(chaining)*
。Java标准库中的
`HashSet`
的实现就是采用这种方法,参见图7.1的说明。更常见的情况是,哈希表以映射的方式出现,例如标准库中
`java.util.Map`
接口的实现。哈希表中桶不仅包含有这些关键字,并且应该通过索引这些关键字同样的表达方式支持更多的额外信息,通常称为值(value),这也就是键值对的由来,。图7.2展示了JDK中类
`java.util.HashMap`
的部分实现,这个类
是
`Map`
接口的一个具体实现。
图7.2中的
`HashMap`
类使用了JDK中
`java.lang.Object`
定义的
`hashCode`
方法来为任意一个关键字
key选择一个子集数字,在Java中任何类都是
`Object`
的子类。如果这个哈希函数设计的非常好,那么每个子集的数量大致会对应上元素的数量
(在7.3节中查看更多讨论)。
图7.2中的
`HashMap`
类使用了JDK中
`java.lang.Object`
定义的
`hashCode`
方法来为任意一个关键字
生成一个桶对应的序号,在Java中任何类都是
`Object`
的子类。如果这个哈希函数设计的非常好,那么桶的数量大致会和键的数量对应
(在7.3节中查看更多讨论)。
我们可以
定义一个每个集合中元素平均数量的先验限制,当超过这个限制时进行表的扩容。这就是构造函数参数和类属性中
`loaderFactor`
的目的。我们可以很自然的想到是否可以使用"更快"的数据结构(比如二叉搜索树)来存储这个集合。然而,我们真的为树的大小选择一个合理的值,因此每一个集合
只能容纳少量的元素,这将得不偿失。当集合数组的长度达到我们设定的限制时,我们可以使用4.1节中
`ArrayList`
类似的策略增长。为了达到很好的渐进时间性能,通常会在需要扩容时,扩展为原来的两倍。除此之外,我们还需要记住,大多数元素的数量都会发生改变,因此我们必须进行移动。
我们可以
预先定义一个每个集合中关键字平均数量的限制,当超过这个限制时进行表的扩容。这就是构造函数参数和类属性中
`loaderFactor`
的目的。我们很自然的想到是否可以使用"更快"的数据结构(比如二叉搜索树)来存储这个集合。然而,我们真的选择一个合理大小的树用于存储集合,那么
只能容纳少量的元素,这将得不偿失。当集合数组的长度达到我们设定的限制时,我们可以使用4.1节中
`ArrayList`
类似的策略增长。为了达到很好的渐进时间性能,通常会在需要扩容时,扩展为原来的两倍。除此之外,我们还需要记住,大多数元素的数量都会发生改变,因此我们必须进行移动。
## 7.2 开放地址法
开放地址法直接将元素存储在桶中。如果某个桶已经存放了元素,后续相同哈希值的元素需要放到根据
系统规则定义好的未使用的桶中。图7.2中的
`put`
操作就像这样:
## 7.2 开放地址法
*开放地址法(open-address)*
直接将元素存储在桶中。如果某个桶已经存放了元素,后续相同哈希值的元素需要放到
系统规则定义好的未使用的桶中。图7.2中的
`put`
操作就像这样:
```
java
public
Val
put
(
Key
key
,
Val
value
)
{
int
h
=
hash
(
key
);
...
...
@@ -34,12 +34,22 @@
```
而且
`get`
操作也需要进行类似的修改。
如果出现了一个位置h已经被占用(一种称为碰撞的情况),
`nextProbe`
方法提供了另外一个桶的索引的值。
如果出现了一个桶h已经被占用(这种情况称为碰撞),使用
`nextProbe`
进行额外的寻址,这个方法提供了另外一个可用桶的索引值。
最简单的
`nextProbe(L)`
实现被称为线性探测,其直接返回
`(h+1) % bins.size()`
。通常情况下,我们使用线性探测的值加上一个正整数的常数值,这个常数值必须哈希和表长度
`bins.size()`
的互质
\[
为什么需要互质?
\]
。
最简单的
`nextProbe(L)`
实现被称为线性探测,其直接返回
`(h+1) % bins.size()`
。通常情况下,我们通常使用线性探测的值加上一个正整数的常数值,这个常数值必须哈希和表长度
`bins.size()`
的互质
\[
为什么需要互质?
\]
。如果我们取出图7.1中的17个关键字:

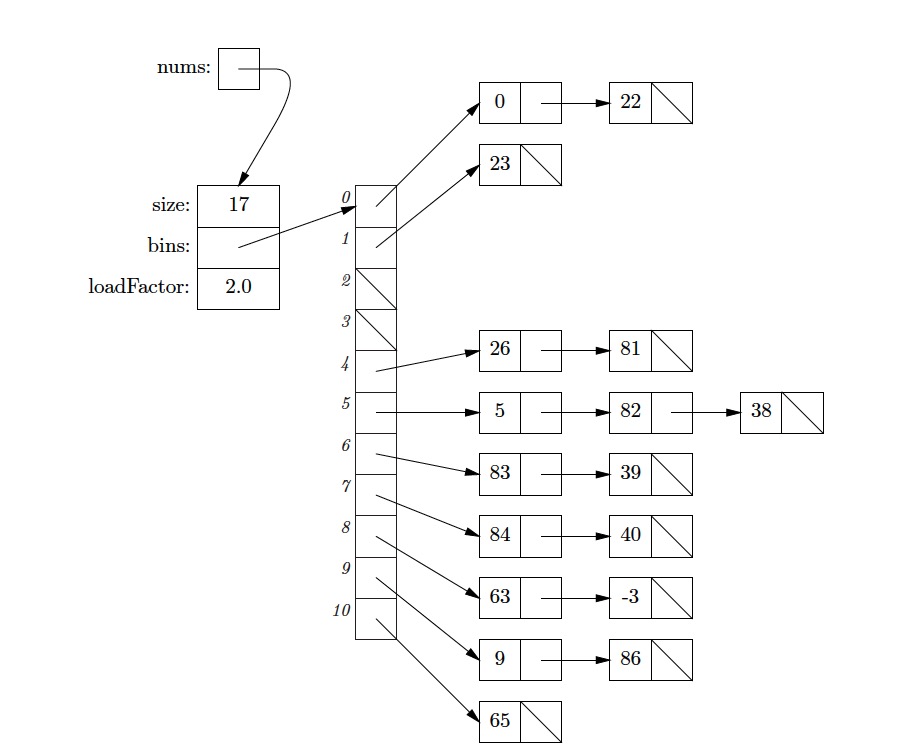
图7.1: 一个简单的链地址法实现的哈希表,使用变量
`nums`
表示。这个哈希表包含11个桶,每个桶都存储了一个指向链表的指针(如果对应的元素存在)。这个哈希表表示一个特定的集合:
**{81, 22, 38, 26, 86, 82, 0, 23, 39, 65, 83, 40, 9, -3, 84, 63, 5},**
这个哈希函数是简单的针对整数键,
`h(x) = x mod 11`
。(
`a mod b`
的数学操作定义为$a-b
\l
floor
\a\b\r
floor$ 当
`b != 0`
。因此永远为非负数)。这个哈希当前的负载因子(load factor)为$17
\1
1
\a
ppro1.5$,最大最多为2.0(
`loadFactor`
属性),如你所见,桶的大小从0到3。

图7.2:
`java.util.HashMap`
类的部分代码,实现了
`java.util.Map interface`
接口

图7.2续:
`HashMap`
类的私有方法
如果我们取出图7.1中的17个关键字:
{81, 22, 38, 26, 86, 82, 0, 23, 39, 65, 83, 40, 9, -3, 84, 63, 5},
使用线性探测法,其中增长量为1并且
`x mod 23`
作为哈希函数,将所有的关键字按顺序存放到容量为23的数组中,这个数组中包含的值如下:
使用线性探测法,其中增长量为1并且
`x mod 23`
作为哈希函数,将所有的关键字按序存放到容量为23的数组中,这个数组中包含的值如下:
| 0| 1| 2| 3| 4| 5| 6| 7| 8| 9|10|11|12|13|14|15|16|17|18|19|20|21|22|
|-----|----|----|----|----|----|----|----|----|----|----|-----|----|----|----|----|----|----|----|----|----|----|----|
...
...
@@ -47,127 +57,17 @@
正如你所见,有几个键并没有放在其本来的位置。例如,
**84 mod 23 == 15**
和
**63 mod 23 == 17**
。
线性探测存在一个聚类现象,参考链地址法很容易发现这个问题。如果在搜索某个键时
检查的条目序列是b0,b1,...,bn,如果任何其他键应该散列到其中一个bi,那么在搜索它时检查的条目序列将是同一序列的一部分,bi,bi+1,...,bn,甚至这两个keys
的哈希值不相同。
线性探测存在一个聚类现象,参考链地址法很容易发现这个问题。如果在搜索某个键时
的条目序列是$b_0$,$b_1$,...,$bn_$,如果任何其他键应该散列到其中一个$b_i$,那么在搜索它时检查的条目序列将是同一序列的一部分,$b_i$,$b_{i+1}$,...,$b_n$,甚至这两个键
的哈希值不相同。
实际上,链接地址法下的两个不同列表将被合并,在线性探测下,这些键的有效平均大小将会加倍。我们整数集的最长链(见图7.1)长度只有3。在上面的开放地址示例中,最长链是有9个元素(见63),即使只有一个与其他键(40)的散列值相同。
让
`nextProbe`
以不同的量递增值,增量取决于原始keys,我们通过这种被称为双重散列的技术,可以有效改善这种效果。
从开放地址哈希表删除一个元素并不简单。简单地将条目标记为“未占用”可以打破碰撞条目链,并从表中删除多条所需要的项目
\[
为什么?
\]
。如果需要进行删除操作,我们不得不谨慎处理。有兴趣的读者可以参考高德纳的
**计算机程序设计的艺术**
第三卷了解更多相关信息。
一般来说,开放地址法的问题在于链地址法下位于不同容器中的keys可以相互竞争。在使用链地址法时,如果所有的槽都已经被占用,我们要确认搜索的关键字key并不在表中,最多只需要找与被搜索值具有相同哈希值的元素数量的次数。使用开放地址法,可能需要搜索N次才能确定被搜索的值是否在表中。根据我的经验,链地址法所需要的额外存储空间成本相对并不重要,对于大多数场景下,我更建议使用链地址法而不是开放地址法。
```
java
package
java.util
;
public
class
HashMap
<
Key
,
Val
>
extends
AbstractMap
<
Key
,
Val
>
{
/** A new, empty mapping using a hash table that initially has
* INITIALBINS bins, and maintains a load factor <= LOADFACTOR. */
public
HashMap
(
int
initialBins
,
float
loadFactor
)
{
if
(
initialBuckets
<
1
||
loadFactor
<=
0.0
)
throw
new
IllegalArgumentException
();
bins
=
new
ArrayList
<
Entry
<
Key
,
Val
>>(
initialBins
);
bins
.
addAll
(
Collections
.
ncopies
(
initialBins
,
null
));
size
=
0
;
this
.
loadFactor
=
loadFactor
;
}
/** An empty map with INITIALBINS initial bins and load factor 0.75. */
public
HashMap
(
int
initialBins
)
{
this
(
initialBins
,
0.75
);
}
/** An empty map with default initial bins and load factor 0.75. */
public
HashMap
()
{
this
(
127
,
0.75
);
}
/** A mapping that is a copy of M. */
public
HashMap
(
Map
<
Key
,
Val
>
M
)
{
this
(
M
.
size
(),
0.75
);
putAll
(
M
);
}
public
T
get
(
Object
key
)
{
Entry
e
=
find
(
key
,
bins
.
get
(
hash
(
key
)));
return
(
e
==
null
)
?
null
:
e
.
value
;
}
/** Cause get(KEY) == VALUE. Returns the previous get(KEY). */
public
Val
put
(
Key
key
,
Val
value
)
{
int
h
=
hash
(
key
);
Entry
<
Key
,
Val
>
e
=
find
(
key
,
bins
.
get
(
h
));
if
(
e
==
null
)
{
bins
.
set
(
h
,
new
Entry
<
Key
,
Val
>
(
key
,
value
,
bins
.
get
(
h
)));
size
+=
1
;
if
(
size
>
bins
.
size
()
*
loadFactor
)
grow
();
return
null
;
}
else
return
e
.
setValue
(
value
);
}
...
```
从开放地址哈希表删除一个元素并不简单。简单地将条目标记为“未占用”可以打破碰撞条目链,并从表中删除多条所需要的元素
\[
为什么?
\]
。如果需要进行删除操作,我们不得不谨慎处理。有兴趣的读者可以参考高德纳的
**计算机程序设计的艺术**
第三卷了解更多相关信息。
```
java
private
static
class
Entry
<
K
,
V
>
implements
Map
.
Entry
<
K
,
V
>
{
K
key
;
V
value
;
Entry
<
K
,
V
>
next
;
Entry
(
K
key
,
V
value
,
Entry
<
K
,
V
>
next
){
this
.
key
=
key
;
this
.
value
=
value
;
this
.
next
=
next
;
}
public
K
getKey
()
{
return
key
;
}
public
V
getValue
()
{
return
value
;
}
public
V
setValue
(
V
x
){
V
old
=
value
;
value
=
x
;
return
old
;
}
public
int
hashCode
()
{
see
Figure
2.14
}
public
boolean
equals
()
{
see
Figure
2.14
}
}
private
ArrayList
<
Entry
<
Key
,
Val
>>
bins
;
private
int
size
;
/** Number of items currently stored */
private
float
loadFactor
;
/** Increase number of bins. */
private
void
grow
()
{
HashMap
<
Key
,
Val
>
newMap
=
new
HashMap
(
primeAbove
(
bins
.
size
()*
2
),
loadFactor
);
newMap
.
putAll
(
this
);
copyFrom
(
newMap
);
}
/** Return a value in the range 0 .. bins.size ()-1, based on
* the hash code of KEY. */
private
int
hash
(
Object
key
)
{
return
(
key
==
null
)
?
0
:
(
0x7fffffff
&
key
.
hashCode
())
%
bins
.
size
();
}
/** Set THIS to the contents of S, destroying the previous
* contents of THIS, and invalidating S. */
private
void
copyFrom
(
HashMap
<
Key
,
Val
>
S
){
size
=
S
.
size
;
bins
=
S
.
bins
;
loadFactor
=
S
.
loadFactor
;
}
/** The Entry in the list BIN whose key is KEY, or null if none. */
private
Entry
<
Key
,
Val
>
find
(
Object
key
,
Entry
<
Key
,
Val
>
bin
)
{
for
(
Entry
<
Key
,
Val
>
e
=
bin
;
e
!=
null
;
e
=
e
.
next
)
if
(
key
==
null
&&
e
.
key
==
null
||
key
.
equals
(
e
.
key
))
return
e
;
return
null
;
}
private
int
primeAbove
(
int
N
)
{
return
a
prime
number
≥
N
;
}
}
```
一般来说,开放地址法的问题在于链地址法下位于不同桶中的键可以相互竞争。在使用链地址法时,如果所有的桶都已经被占用,我们要确认搜索的关键字并不在表中,最多只需要找与被搜索值具有相同哈希值的元素数量的次数。使用开放地址法,可能需要搜索N次才能确定被搜索的值是否在表中。根据我的经验,链地址法所需要的额外空间成本相对并不重要,对于大多数场景下,我更建议使用链地址法而不是开放地址法。
## 7.3 哈希函数
此前遗留了一个问题:如何选择哈希函数用于存放键
的桶
。为了使我们实现的映射或集合能够正常工作,首先我们的散列函数满足下面两个很重要的约束:
此前遗留了一个问题:如何选择哈希函数用于存放键。为了使我们实现的映射或集合能够正常工作,首先我们的散列函数满足下面两个很重要的约束:
1.
在执行程序期间,对于任何键值K,
`hash(K)`
的值必须保持不变,而K在表中(或者如果hash(K)改变则必须重建哈希表)。
2.
如果两个键相等(根据
`equals`
方法,或者任何哈希表使用的相等测试),则他们两个的哈希值必须相等。
...
...
@@ -200,16 +100,16 @@ public class HashMap<Key,Val> extends AbstractMap<Key,Val> {
return
h
;
}
```
Java字符串类型有不同的
`hashCode`
函数实现,使用模运算来计算得到一个
-231到231-1范围内的结果。
```
java
gongshi
```
这里,
ci
表示clsString中的第i个字符。
Java字符串类型有不同的
`hashCode`
函数实现,使用模运算来计算得到一个
$-2^31$到$2^31-1$范围内的结果。
$$
\s
um_{i=0}^n
\c
_i
\3
1^{n - i - 1}$$
这里,
$c_i$
表示clsString中的第i个字符。
## 7.4 性能
假设密钥均匀分布,无论在哈希表中是否包含待查找的元素,都可以常数时间内完成检索。正如我们在4.1节中关于ArrayList
`规模增长的分析,哈希表插入也具有常数的摊分时间复杂度(即所有插入的平均复杂度)。当然,如果键分布不均匀,我们可以看成
O(N)
的时间复杂度。
假设密钥均匀分布,无论在哈希表中是否包含待查找的元素,都可以常数时间内完成检索。正如我们在4.1节中关于ArrayList
`规模增长的分析,哈希表插入也具有常数的摊分时间复杂度(即所有插入的平均复杂度)。当然,如果键分布不均匀,我们可以看成
$\Theta(N)$
的时间复杂度。
如果一个哈希函数有时可能会出现错误的聚类问题,我们可以使用一种被称为通用散列的技术帮助解决。可以从一些精心挑选的集合中随机挑选一个哈希函数,在平均情况下,在程序的运行过程中哈希函数将会有良好的表现。
## 练习
**7.1** 通过7.1节中
给出的`
HashMap
`表示的`
iterator
`方法的实现,并且`
Iterator
`类也是必要的。因为
我们已经选择简单的链表实现,你必须谨慎使用正确的`
remove
`
操作。
**7.1** 通过7.1节中
, 给出的`
HashMap
`表示的`
iterator
`方法的具体实现,并且`
Iterator
`类也是必要的。
我们已经选择简单的链表实现,你必须谨慎使用正确的`
remove
`
操作。
zh/img/figure_7_1.jpg
0 → 100644
浏览文件 @
12243b1d
63.7 KB
zh/img/figure_7_2_1.jpg
0 → 100644
浏览文件 @
12243b1d
105.8 KB
zh/img/figure_7_2_2.jpg
0 → 100644
浏览文件 @
12243b1d
114.6 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}

{kind=link}
