Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
hands-on-ml-zh
提交
b99474f4
H
hands-on-ml-zh
项目概览
OpenDocCN
/
hands-on-ml-zh
通知
13
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
H
hands-on-ml-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
未验证
提交
b99474f4
编写于
2月 03, 2019
作者:
飞
飞龙
提交者:
GitHub
2月 03, 2019
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #128 from AnEscapist/dev
Fig 3-3 missing in chapter 3
上级
6b01783d
d0ed854e
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
1 addition
and
1 deletion
+1
-1
docs/3.分类.md
docs/3.分类.md
+1
-1
images/chapter_3/chapter3.3-3.jpeg
images/chapter_3/chapter3.3-3.jpeg
+0
-0
未找到文件。
docs/3.分类.md
浏览文件 @
b99474f4
...
...
@@ -269,7 +269,7 @@ F1 支持那些有着相近准确率和召回率的分类器。这不会总是
为了弄懂这个折衷,我们看一下
`SGDClassifier`
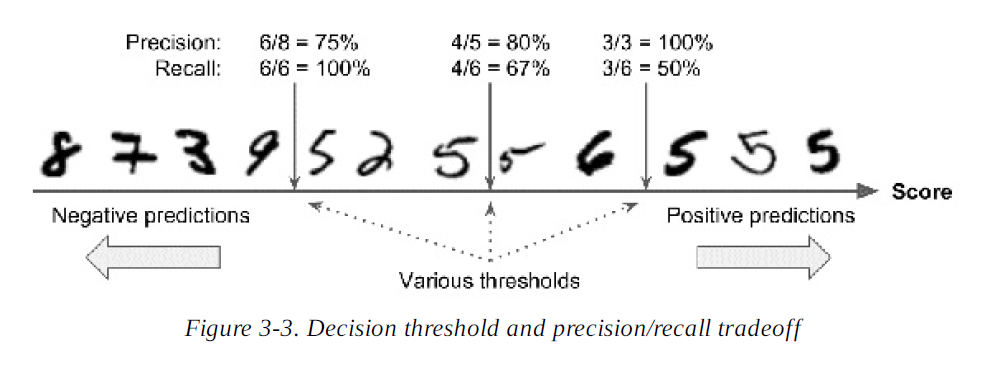
是如何做分类决策的。对于每个样例,它根据决策函数计算分数,如果这个分数大于一个阈值,它会将样例分配给正例,否则它将分配给反例。图 3-3 显示了几个数字从左边的最低分数排到右边的最高分。假设决策阈值位于中间的箭头(介于两个 5 之间):您将发现4个真正例(数字 5)和一个假正例(数字 6)在该阈值的右侧。因此,使用该阈值,准确率为 80%(4/5)。但实际有 6 个数字 5,分类器只检测 4 个, 所以召回是 67% (4/6)。现在,如果你
提高阈值(移动到右侧的箭头),假正例(数字 6)成为一个真反例,从而提高准确率(在这种情况下高达 100%),但一个真正例 变成假反例,召回率降低到 50%。相反,降低阈值可提高召回率、降低准确率。
![
图3-3 决策阈值与准确度/召回率折衷
]
[
../images/chapter_3/chapter3.3.jpeg
]
![
图3-3 决策阈值与准确度/召回率折衷
]
(
../images/chapter_3/chapter3.3-3.jpeg
)
Scikit-Learn 不让你直接设置阈值,但是它给你提供了设置决策分数的方法,这个决策分数可以用来产生预测。它不是调用分类器的
`predict()`
方法,而是调用
`decision_function()`
方法。这个方法返回每一个样例的分数值,然后基于这个分数值,使用你想要的任何阈值做出预测。
...
...
images/chapter_3/chapter3.3-3.jpeg
0 → 100644
浏览文件 @
b99474f4
108.3 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}