Merge branch 'master' of https://github.com/apachecn/stanford-cs224n-notes-zh
Showing
docs/1.md
已删除
100644 → 0
{kind=link}

68.3 KB
{kind=link}
61.3 KB
{kind=link}
79.3 KB
{kind=link}

40.2 KB
{kind=link}
125.8 KB
{kind=link}

151.4 KB
{kind=link}
85.4 KB
{kind=link}
61.6 KB
{kind=link}

237.9 KB
{kind=link}

74.2 KB
{kind=link}
85.5 KB
{kind=link}
80.9 KB
{kind=link}
130.7 KB
{kind=link}

80.0 KB
{kind=link}

125.1 KB
{kind=link}
74.4 KB
{kind=link}
103.7 KB
{kind=link}
66.6 KB
{kind=link}
75.4 KB
{kind=link}
85.0 KB
{kind=link}

127.7 KB
{kind=link}
77.7 KB
{kind=link}

99.2 KB
{kind=link}
74.2 KB
{kind=link}
135.3 KB
{kind=link}

95.5 KB
{kind=link}

75.3 KB
{kind=link}
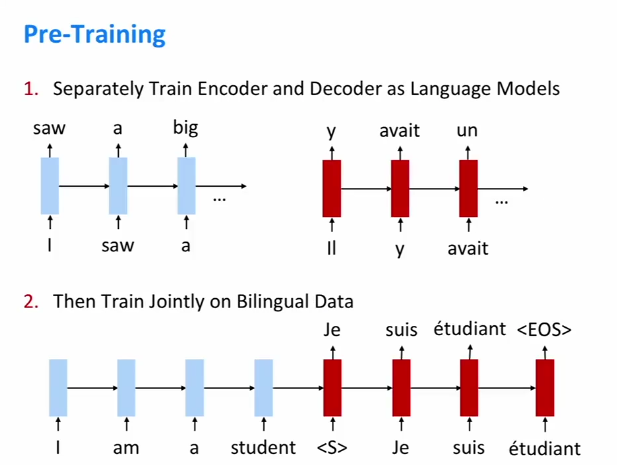
71.9 KB
{kind=link}

105.5 KB
{kind=link}

91.2 KB
{kind=link}

64.4 KB
{kind=link}

112.2 KB
{kind=link}

70.1 KB
{kind=link}

50.5 KB
{kind=link}
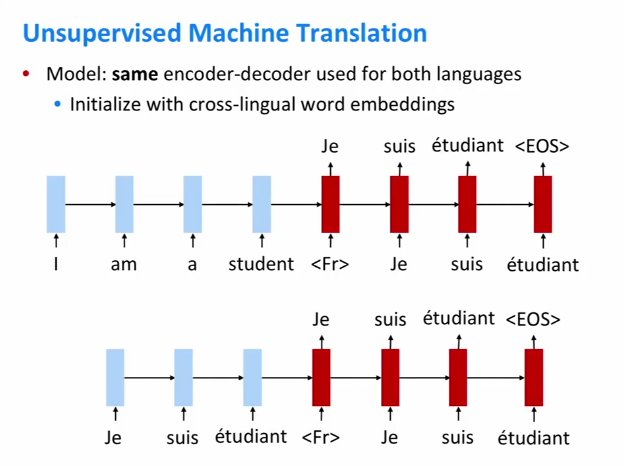
89.1 KB
{kind=link}

152.6 KB
{kind=link}
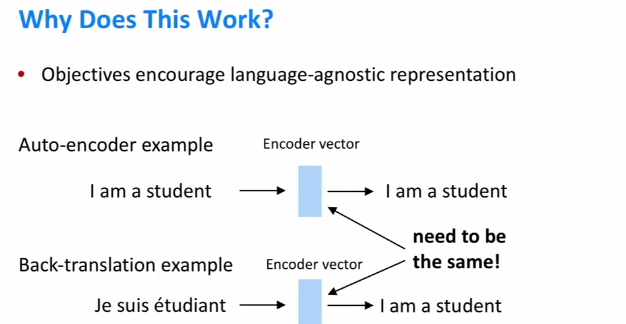
61.2 KB
{kind=link}

125.2 KB
docs/lecture 20/note.md
已删除
100644 → 0