Merge pull request #11 from ZSIRS/master
Lecture 4+6
Showing
docs/Lecture4/Lecture 4.md
0 → 100644
文件已添加
docs/Lecture4/media/1.png
0 → 100644
{kind=link}
65.8 KB
docs/Lecture4/media/10.png
0 → 100644
{kind=link}

11.1 KB
docs/Lecture4/media/11.png
0 → 100644
{kind=link}
20.9 KB
docs/Lecture4/media/12.png
0 → 100644
{kind=link}
7.3 KB
docs/Lecture4/media/13.png
0 → 100644
{kind=link}
9.8 KB
docs/Lecture4/media/14.png
0 → 100644
{kind=link}

2.1 KB
docs/Lecture4/media/15.png
0 → 100644
{kind=link}

1.3 KB
docs/Lecture4/media/16.png
0 → 100644
{kind=link}
949 字节
docs/Lecture4/media/17.png
0 → 100644
{kind=link}
1007 字节
docs/Lecture4/media/18.png
0 → 100644
{kind=link}
1.2 KB
docs/Lecture4/media/19.png
0 → 100644
{kind=link}
3.2 KB
docs/Lecture4/media/2.png
0 → 100644
{kind=link}
994 字节
docs/Lecture4/media/20.png
0 → 100644
{kind=link}
1.2 KB
docs/Lecture4/media/21.png
0 → 100644
{kind=link}
913 字节
docs/Lecture4/media/22.png
0 → 100644
{kind=link}
2.5 KB
docs/Lecture4/media/23.png
0 → 100644
{kind=link}
989 字节
docs/Lecture4/media/24.png
0 → 100644
{kind=link}
32.6 KB
docs/Lecture4/media/25.png
0 → 100644
{kind=link}
46.4 KB
docs/Lecture4/media/26.png
0 → 100644
{kind=link}
1.6 KB
docs/Lecture4/media/27.png
0 → 100644
{kind=link}
1.2 KB
docs/Lecture4/media/28.png
0 → 100644
{kind=link}
2.2 KB
docs/Lecture4/media/29.png
0 → 100644
{kind=link}

4.2 KB
docs/Lecture4/media/3.png
0 → 100644
{kind=link}
1.2 KB
docs/Lecture4/media/30.png
0 → 100644
{kind=link}
3.0 KB
docs/Lecture4/media/31.png
0 → 100644
{kind=link}
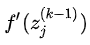
2.0 KB
docs/Lecture4/media/32.png
0 → 100644
{kind=link}
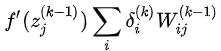
4.4 KB
docs/Lecture4/media/33.png
0 → 100644
{kind=link}
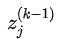
1.1 KB
docs/Lecture4/media/4.png
0 → 100644
{kind=link}
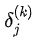
1.1 KB
docs/Lecture4/media/5.png
0 → 100644
{kind=link}
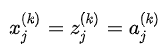
2.7 KB
docs/Lecture4/media/6.png
0 → 100644
{kind=link}
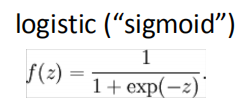
9.3 KB
docs/Lecture4/media/7.png
0 → 100644
{kind=link}
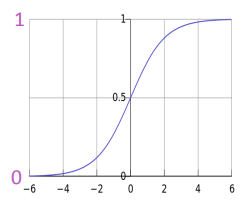
7.5 KB
docs/Lecture4/media/8.png
0 → 100644
{kind=link}

6.8 KB
docs/Lecture4/media/9.png
0 → 100644
{kind=link}
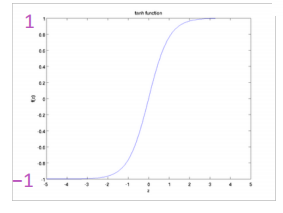
10.6 KB
docs/Lecture6/Lecture 6.md
0 → 100644
文件已添加
docs/Lecture6/media/1.png
0 → 100644
{kind=link}
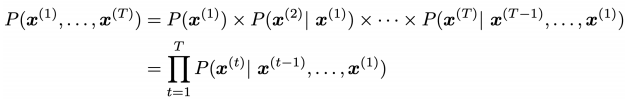
14.2 KB
docs/Lecture6/media/10.png
0 → 100644
{kind=link}
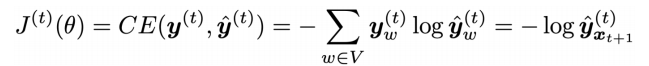
16.7 KB
docs/Lecture6/media/11.png
0 → 100644
{kind=link}
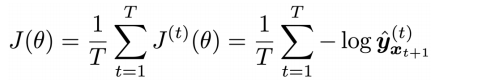
14.2 KB
docs/Lecture6/media/12.png
0 → 100644
{kind=link}
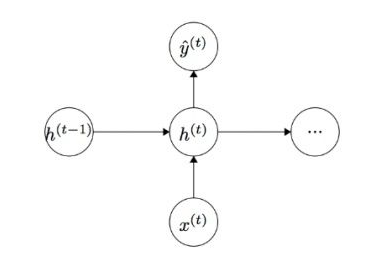
23.3 KB
docs/Lecture6/media/13.png
0 → 100644
{kind=link}
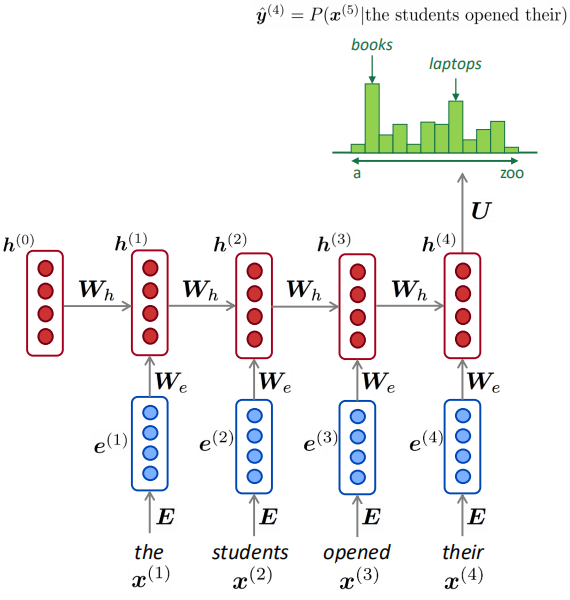
73.2 KB
docs/Lecture6/media/14.png
0 → 100644
{kind=link}

70.1 KB
docs/Lecture6/media/2.png
0 → 100644
{kind=link}

23.9 KB
docs/Lecture6/media/3.png
0 → 100644
{kind=link}
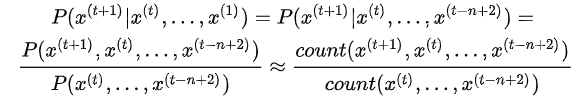
18.9 KB
docs/Lecture6/media/4.png
0 → 100644
{kind=link}
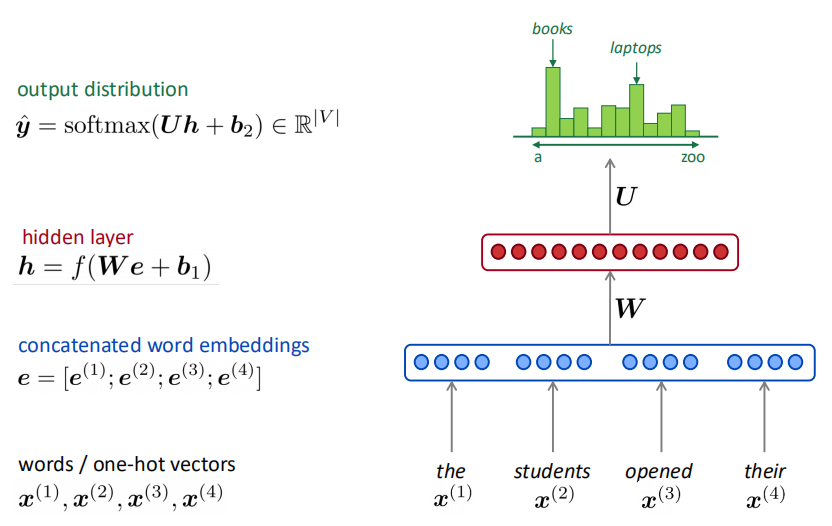
71.1 KB
docs/Lecture6/media/5.png
0 → 100644
{kind=link}
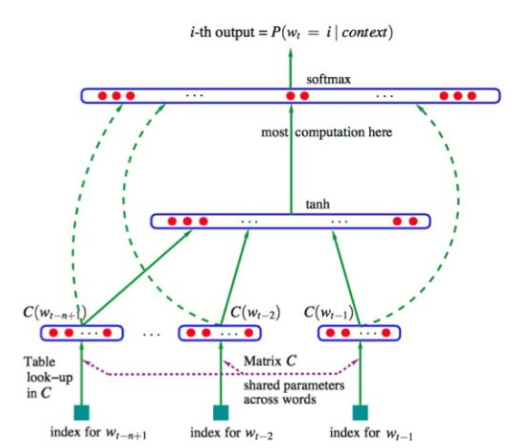
145.9 KB
docs/Lecture6/media/6.png
0 → 100644
{kind=link}
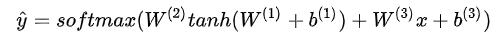
7.4 KB
docs/Lecture6/media/7.png
0 → 100644
{kind=link}
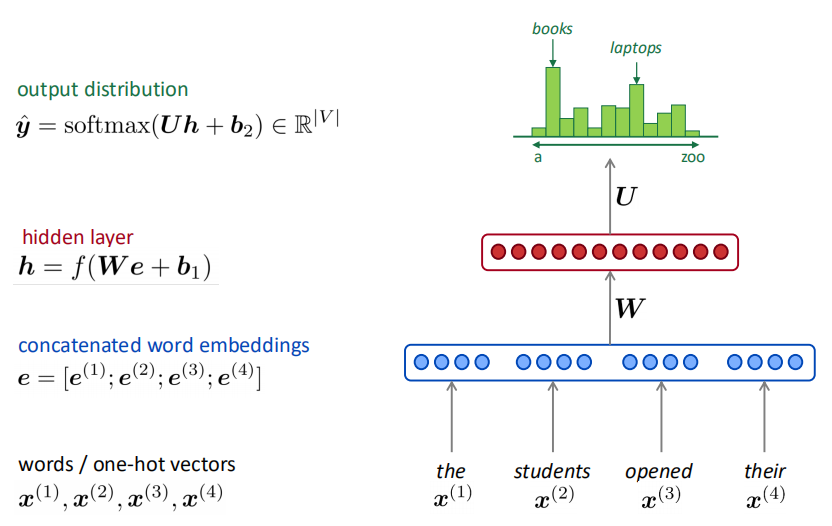
71.1 KB
docs/Lecture6/media/8.png
0 → 100644
{kind=link}
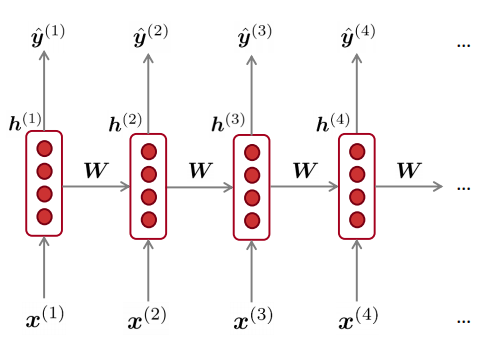
31.8 KB
docs/Lecture6/media/9.png
0 → 100644
{kind=link}
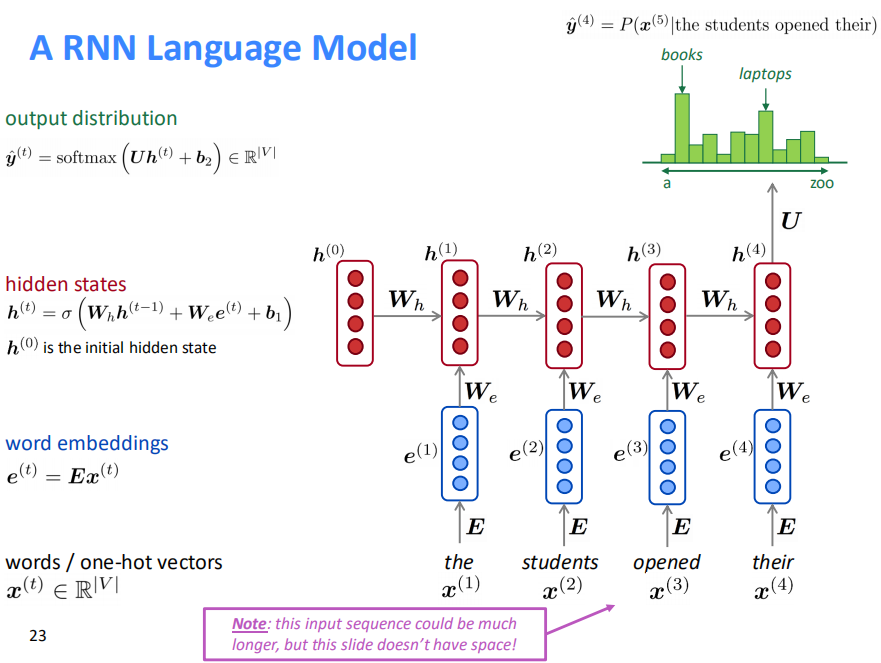
121.4 KB