Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
think-dast-zh
提交
cd2ee2cc
T
think-dast-zh
项目概览
OpenDocCN
/
think-dast-zh
8 个月 前同步成功
通知
0
Star
26
Fork
13
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
think-dast-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
cd2ee2cc
编写于
9月 26, 2017
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
ch17
上级
ea0e51f6
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
116 addition
and
0 deletion
+116
-0
17.md
17.md
+116
-0
img/17-1.jpg
img/17-1.jpg
+0
-0
img/17-2.jpg
img/17-2.jpg
+0
-0
img/17-3.jpg
img/17-3.jpg
+0
-0
未找到文件。
17.md
浏览文件 @
cd2ee2cc
# 第十七章 排序
> 原文:[Chapter 17 Sorting](http://greenteapress.com/thinkdast/html/thinkdast018.html)
> 译者:[飞龙](https://github.com/wizardforcel)
> 协议:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
> 自豪地采用[谷歌翻译](https://translate.google.cn/)
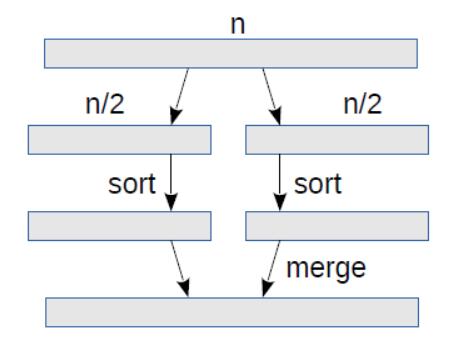
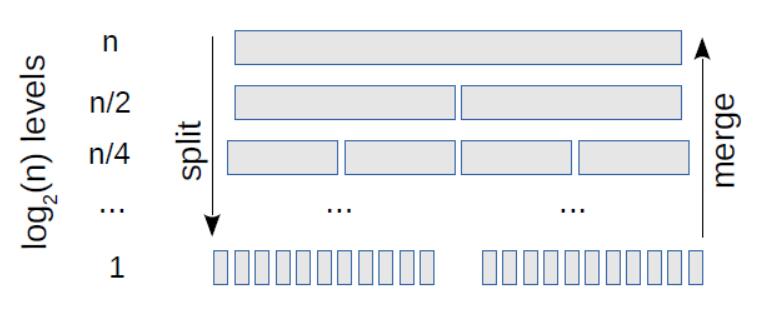
计算机科学领域过度痴迷于排序算法。根据 CS 学生在这个主题上花费的时间,你会认为排序算法的选择是现代软件工程的基石。当然,现实是,软件开发人员可以在很多年中,或者整个职业生涯中,不必考虑排序如何工作。对于几乎所有的应用程序,它们都使用它们使用的语言或库提供的通用算法。通常这样就行了。
所以如果你跳过这一章,不了解排序算法,你仍然是一个优秀的开发人员。但是有一些原因你可能想要这样:
...
...
@@ -173,3 +181,111 @@ h = log2(n)
事实证明,
`O(nlogn)`
是通过元素比较的排序算法的理论下限。这意味着没有任何“比较排序”的增长级别比
`n log n`
好。请参见
<http://thinkdast.com/compsort>
。
但是我们将在下一节中看到,存在线性时间的非比较排序!
## 基数排序
在 2008 年美国总统竞选期间,候选人巴拉克·奥巴马在访问 Google 时,被要求进行即兴算法分析。首席执行长埃里克·施密特开玩笑地问他,“排序一百万个 32 位整数的最有效的方法”。显然有人暗中告诉了奥巴马,因为他很快就回答说:“我认为泡沫的排序是错误的。”你可以在
<http://thinkdast.com/obama>
观看视频。
奥巴马是对的:泡沫排序在概念上是简单的,但其运行时间是二次的; 即使在二次排序算法中,其性能也不是很好。见
<http://thinkdast.com/bubble>
。
施密特想要的答案可能是“基数排序”,这是一种非比较排序算法,如果元素的大小是有界的,例如 32 位整数或 20 个字符的字符串,它就可以工作。
为了看看它是如何工作的,想象你有一堆索引卡,每张卡片包含三个字母的单词。以下是一个方法,可以对卡进行排序:
+
根据第一个字母,将卡片放入桶中。所以以
`a`
开头的单词应该在一个桶中,其次是以
`b`
开头的单词,以此类推
+
根据第二个字母再次将卡片放入每个桶。所以以
`aa`
开头的应该在一起,其次是以
`ab`
开头的,以此类推当然,并不是所有的桶都是满的,但是没关系。
+
根据第三个字母再次将卡片放入每个桶。
此时,每个桶包含一个元素,桶按升序排列。图 17.3 展示了三个字母的例子。

图 17.3:三个字母的基数排序的例子
最上面那行显示未排序的单词。第二行显示第一次遍历后的桶的样子。每个桶中的单词都以相同的字母开头。
第二遍之后,每个桶中的单词以相同的两个字母开头。在第三遍之后,每个桶中只能有一个单词,并且桶是有序的。
在每次遍历期间,我们遍历元素并将它们添加到桶中。只要桶允许在恒定时间内添加元素,每次遍历是线性的。
遍历数量,我会称之为
`w`
,取决于单词的“宽度”,但不取决于单词的数量,
`n`
。所以增长级别是
`O(wn)`
,对于
`n`
是线性的。
基数排序有许多变体,并有许多方法来实现每一个。你可以在
<http://thinkdast.com/radix>
上阅读他们的更多信息。作为一个可选的练习,请考虑编写基数排序的一个版本。
## 17.5 堆排序
基数排序适用于大小有界的东西,除了他之外,还有一种你可能遇到的其它专用排序算法:有界堆排序。如果你在处理非常大的数据集,你想要得到前 10 个或者前
`k`
个元素,其中
`k`
远小于
`n`
,它是很有用的。
例如,假设你正在监视一 个Web 服务,它每天处理十亿次事务。在每一天结束时,你要汇报最大的
`k`
个事务(或最慢的,或者其它最 xx 的)。一个选项是存储所有事务,在一天结束时对它们进行排序,然后选择最大的
`k`
个。需要的时间与
`nlogn`
成正比,这非常慢,因为我们可能无法将十亿次交易记录在单个程序的内存中。我们必须使用“外部”排序算法。你可以在
<http://thinkdast.com/extsort>
上了解外部排序。
使用有界堆,我们可以做得更好!以下是我们的实现方式:
+
我会解释(无界)堆排序。
+
你会实现它
+
我将解释有界堆排序并进行分析。
要了解堆排序,你必须了解堆,这是一个类似于二叉搜索树(BST)的数据结构。有一些区别:
+
在 BST 中,每个节点
`x`
都有“BST 特性”:
`x`
左子树中的所有节点都小于
`x`
,右子树中的所有节点都大于
`x`
。
+
在堆中,每个节点
`x`
都有“堆特性”:两个子树中的所有节点都大于
`x`
。
+
堆就像平衡的 BST;当你添加或删除元素时,他们会做一些额外的工作来重新使树平衡。因此,可以使用元素的数组来有效地实现它们。
> 译者注:这里先讨论最小堆。如果子树中所有节点都小于`x`,那么就是最大堆。
堆中最小的元素总是在根节点,所以我们可以在常数时间内找到它。在堆中添加和删除元素需要的时间与树的高度
`h`
成正比。而且由于堆总是平衡的,所以
`h`
与
`log n`
成正比。你可以在
<http://thinkdast.com/heap>
上阅读更多堆的信息。
Java
`PriorityQueue`
使用堆实现。
`PriorityQueue`
提供
`Queue`
接口中指定的方法,包括
`offer`
和
`poll`
:
+
`offer`
:将一个元素添加到队列中,更新堆,使每个节点都具有“堆特性”。需要
`logn`
的时间。
+
`poll`
:从根节点中删除队列中的最小元素,并更新堆。需要
`logn`
的时间。
给定一个
`PriorityQueue`
,你可以像这样轻松地排序的
`n`
个元素的集合 :
+
使用
`offer`
,将集合的所有元素添加到
`PriorityQueue`
。
+
使用
`poll`
从队列中删除元素并将其添加到
`List`
。
因为
`poll`
返回队列中剩余的最小元素,所以元素按升序添加到
`List`
。这种排序方式称为堆排序 (请参阅
<http://thinkdast.com/heapsort>
)。
向队列中添加
`n`
个元素需要
`nlogn`
的时间。删除
`n`
个元素也是如此。所以堆排序的运行时间是
`O(n logn)`
。
在本书的仓库中,你可以在
`ListSorter.java`
中找到
`heapSort`
方法的大纲。填充它,然后运行
`ant ListSorterTest`
来确认它可以工作。
## 17.6 有界堆排序
有界堆是一个限制为最多包含
`k`
个元素的堆。如果你有
`n`
个元素,你可以跟踪这个最大的
`k`
个元素:
最初堆是空的。对于每个元素
`x`
:
+
分支 1:如果堆不满,请添加
`x`
到堆中。
+
分支 2:如果堆满了,请与堆中
`x`
的最小元素进行比较。如果
`x`
较小,它不能是最大的
`k`
个元素之一,所以你可以丢弃它。
+
分支 3:如果堆满了,并且
`x`
大于堆中的最小元素,请从堆中删除最小的元素并添加
`x`
。
使用顶部为最小元素的堆,我们可以跟踪最大的
`k`
个元素。我们来分析这个算法的性能。对于每个元素,我们执行以下操作之一:
+
分支 1:将元素添加到堆是
`O(log k)`
。
+
分支 2:找到堆中最小的元素是
`O(1)`
。
+
分支 3:删除最小元素是
`O(log k)`
。添加
`x`
也是
`O(log k)`
。
在最坏的情况下,如果元素按升序出现,我们总是执行分支 3。在这种情况下,处理
`n`
个元素的总时间是
`O(n log k)`
,对于
`n`
是线性的。
在
`ListSorter.java`
中,你会发现一个叫做
`topK`
的方法的大纲,它接受一个
`List`
、
`Comparator`
和一个整数
`k`
。它应该按升序返回
`List`
的
`k`
个最大的元素 。填充它,然后运行
`ant ListSorterTest`
来确认它可以工作。
## 17.7 空间复杂性
到目前为止,我们已经谈到了很多运行时间的分析,但是对于许多算法,我们也关心空间。例如,归并排序的一个缺点是它会复制数据。在我们的实现中,它分配的空间总量是
`O(n log n)`
。通过更机智的实现,你可以将空间要求降至
`O(n)`
。
相比之下,插入排序不会复制数据,因为它会原地排序元素。它使用临时变量来一次性比较两个元素,并使用一些其它局部变量。但它的空间使用不取决于
`n`
。
我们的堆排序实现创建了新
`PriorityQueue`
,来存储元素,所以空间是
`O(n)`
; 但是如果你能够原地对列表排序,则可以使用
`O(1)`
的空间执行堆排序 。
刚刚实现的有界堆栈算法的一个好处是,它只需要与
`k`
成正比的空间(我们要保留的元素的数量),而
`k`
通常比
`n`
小得多 。
软件开发人员往往比空间更加注重运行时间,对于许多应用程序来说,这是适当的。但是对于大型数据集,空间可能同等或更加重要。例如:
+
如果一个数据集不能放入一个程序的内存,那么运行时间通常会大大增加,或者根本不能运行。如果你选择一个需要较少空间的算法,并且这样可以将计算放入内存中,则可能会运行得更快。同样,使用较少空间的程序,可能会更好地利用 CPU 缓存并运行速度更快(请参阅
<http://thinkdast.com/cache>
)。
+
在同时运行多个程序的服务器上,如果可以减少每个程序所需的空间,则可以在同一台服务器上运行更多程序,从而降低硬件和能源成本。
所以这些是一些原因,你应该至少了解一些算法的空间需求。
img/17-1.jpg
0 → 100644
浏览文件 @
cd2ee2cc
11.7 KB
img/17-2.jpg
0 → 100644
浏览文件 @
cd2ee2cc
18.5 KB
img/17-3.jpg
0 → 100644
浏览文件 @
cd2ee2cc
31.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
