Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
晶之木
advanced-java
提交
89158977
A
advanced-java
项目概览
晶之木
/
advanced-java
与 Fork 源项目一致
从无法访问的项目Fork
通知
3
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
A
advanced-java
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
89158977
编写于
12月 04, 2018
作者:
Y
yanglbme
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
docs(es): add es-introduction.md
es介绍与核心概念说明
上级
2988af85
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
62 addition
and
1 deletion
+62
-1
README.md
README.md
+3
-1
docs/high-concurrency/es-introduction.md
docs/high-concurrency/es-introduction.md
+59
-0
img/es-cluster-0.png
img/es-cluster-0.png
+0
-0
未找到文件。
README.md
浏览文件 @
89158977
...
...
@@ -6,6 +6,8 @@
本系列知识出自中华石杉,我对这部分知识做了一个系统的整理,方便学习查阅。
一点小建议:学习本系列知识之前,如果你完全没接触过
`MQ`
、
`ES`
、
`Redis`
、
`Dubbo`
、
`Hystrix`
等,那么我建议你可以先在网上搜一下每一块知识的快速入门,玩一下入门 Demo,然后再开始每一块知识的学习。这样效果更好噢~
## 高并发架构
### [消息队列](/docs/high-concurrency/mq-interview.md)
...
...
@@ -17,7 +19,7 @@
-
[
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
](
/docs/high-concurrency/mq-time-delay-and-expired-failure.md
)
-
[
如果让你写一个消息队列,该如何进行架构设计啊?说一下你的思路。
](
/docs/high-concurrency/mq-design.md
)
###
搜索引擎
###
[搜索引擎](/docs/high-concurrency/es-introduction.md)
-
[
es 的分布式架构原理能说一下么(es 是如何实现分布式的啊)?
](
/docs/high-concurrency/es-architecture.md
)
-
[
es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗?
](
/docs/high-concurrency/es-write-query-search.md
)
-
[
es 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
](
/docs/high-concurrency/es-optimizing-query-performance.md
)
...
...
docs/high-concurrency/es-introduction.md
0 → 100644
浏览文件 @
89158977
## lucene 和 es 的前世今生
lucene 是最先进、功能最强大的搜索库。如果直接基于 lucene 开发,非常复杂,即便写一些简单的功能,也要写大量的 Java 代码,需要深入理解原理。
elasticsearch 基于lucene,隐藏了 lucene 的复杂性,提供了简单易用的 restful api / Java api接口(另外还有其他语言的 api接口)。
-
分布式的文档存储引擎
-
分布式的搜索引擎和分析引擎
-
分布式,支持 PB 级数据
## es 的核心概念
### Near Realtime
近实时,有两层意思:
-
从写入数据到数据可以被搜索到有一个小延迟(大概是 1s)
-
基于 es 执行搜索和分析可以达到秒级
### Cluster 集群
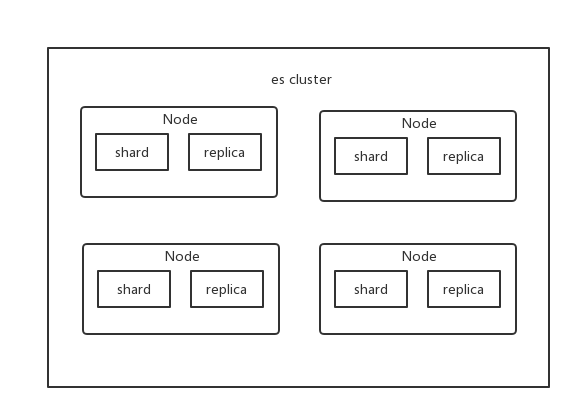
集群包含多个节点,每个节点属于哪个集群都是通过一个配置来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常。
### Node 节点
Node 是集群中的一个节点,节点也有一个名称,默认是随机分配的。默认节点会去加入一个名称为
`elasticsearch`
的集群。如果直接启动一堆节点,那么它们会自动组成一个 elasticsearch 集群,当然一个节点也可以组成 elasticsearch 集群。
### Document & field
文档是 es 中最小的数据单元,一个 document 可以是一条客户数据、一条商品分类数据、一条订单数据,通常用 json 数据结构来表示。每个 index 下的 type,都可以存储多条 document。一个 document 里面有多个 field,每个 field 就是一个数据字段。
```
json
{
"product_id"
:
"1"
,
"product_name"
:
"iPhone X"
,
"product_desc"
:
"苹果手机"
,
"category_id"
:
"2"
,
"category_name"
:
"电子产品"
}
```
### Index
索引包含了一堆有相似结构的文档数据,比如商品索引。一个索引包含很多 document,一个索引就代表了一类相似或者相同的 ducument。
### Type
类型,每个索引里可以有一个或者多个 type,type 是 index 的一个逻辑分类,比如商品 index 下有多个 type:日化商品 type、电器商品 type、生鲜商品 type。每个 type 下的 document 的 field 可能不太一样。
### shard
单台机器无法存储大量数据,es 可以将一个索引中的数据切分为多个 shard,分布在多台服务器上存储。有了 shard 就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个 shard 都是一个lucene index。
### replica
任何一个服务器随时可能故障或宕机,此时 shard 可能就会丢失,因此可以为每个 shard 创建多个 replica 副本。replica 可以在 shard 故障时提供备用服务,保证数据不丢失,多个 replica 还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认 5 个),replica shard(随时修改数量,默认 1 个),默认每个索引 10 个 shard,5 个 primary shard,5个 replica shard,最小的高可用配置,是 2 台服务器。
这么说吧,shard 分为 primary shard 和 replica shard。而 primary shard 一般简称为 shard,而 replica shard 一般简称为 replica。

## es 核心概念 vs. db 核心概念
| es | db |
|---|---|
| index | 数据库 |
| type | 数据表 |
| docuemnt | 一行数据 |
以上是一个简单的类比。
\ No newline at end of file
img/es-cluster-0.png
0 → 100644
浏览文件 @
89158977
8.4 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}