All
Showing
{kind=link}
73.6 KB
{kind=link}
155.0 KB
{kind=link}
120.8 KB
{kind=link}
237.7 KB
{kind=link}
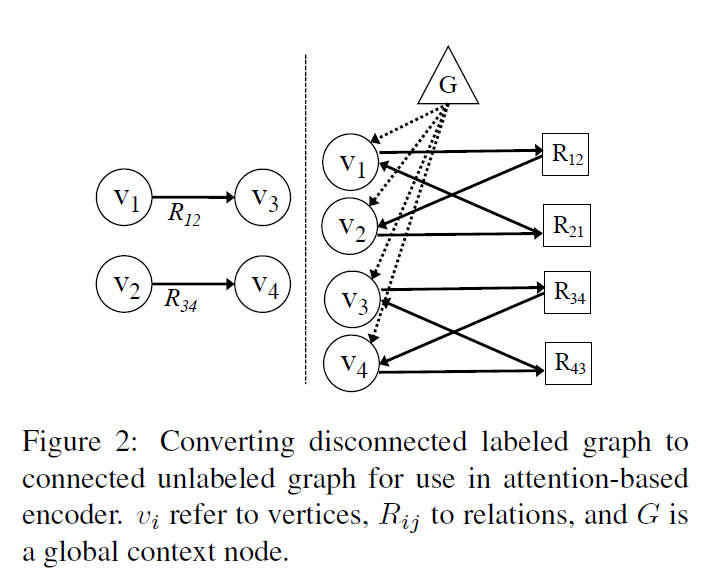
53.8 KB
{kind=link}
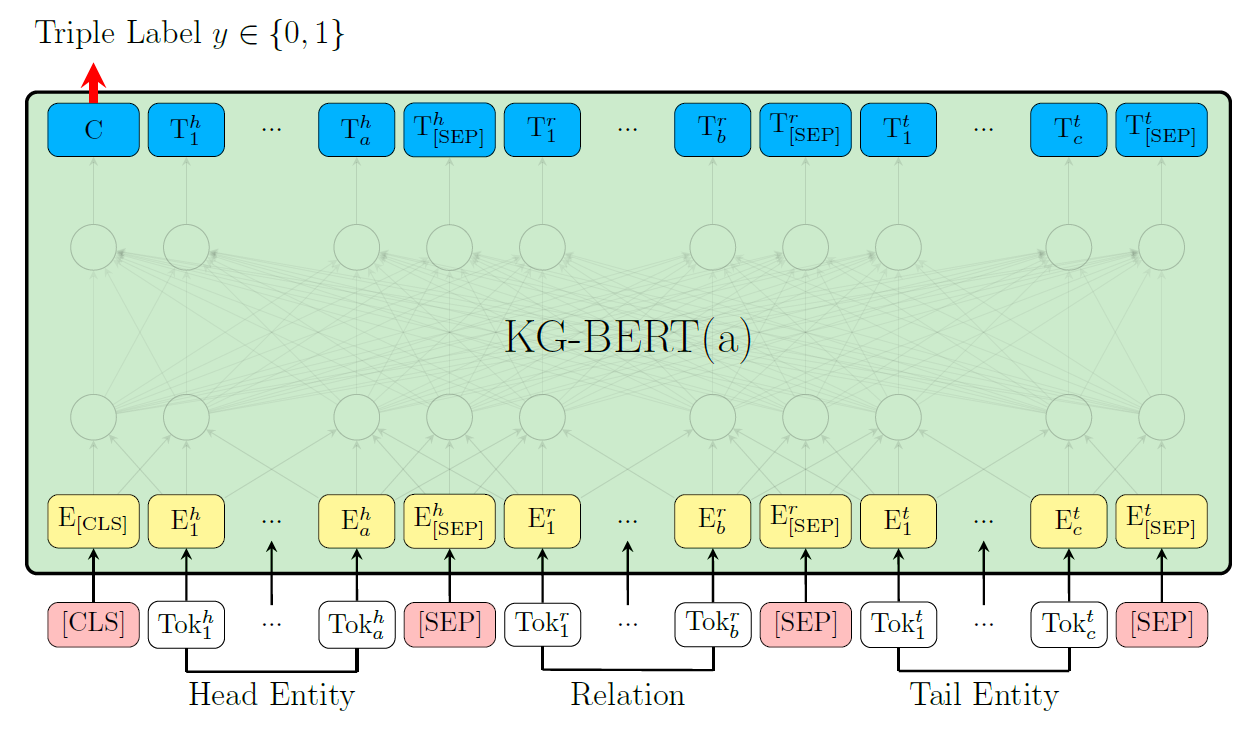
172.7 KB
{kind=link}
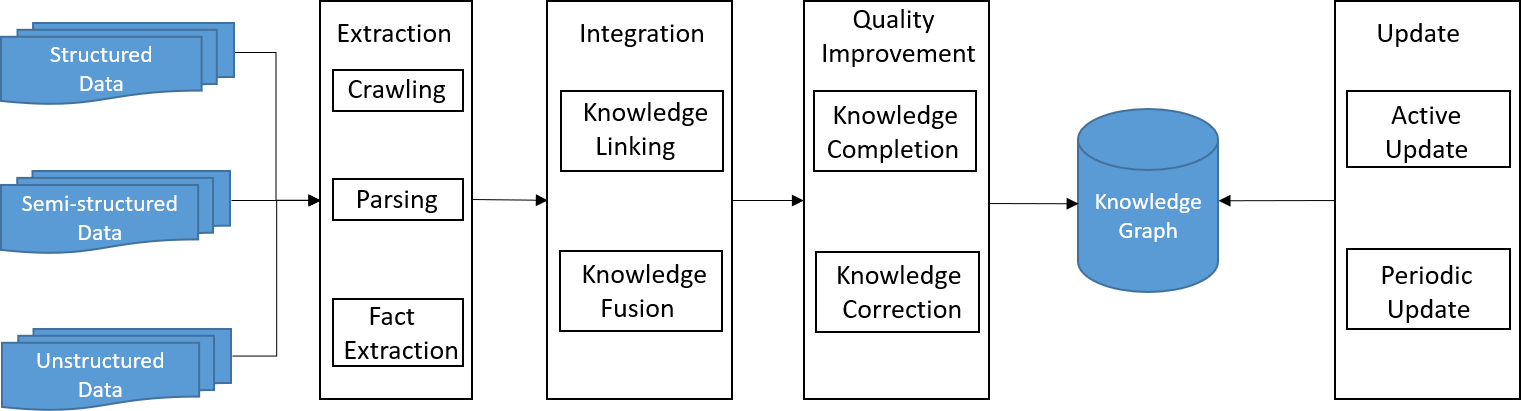
53.4 KB
{kind=link}

1004.3 KB
{kind=link}
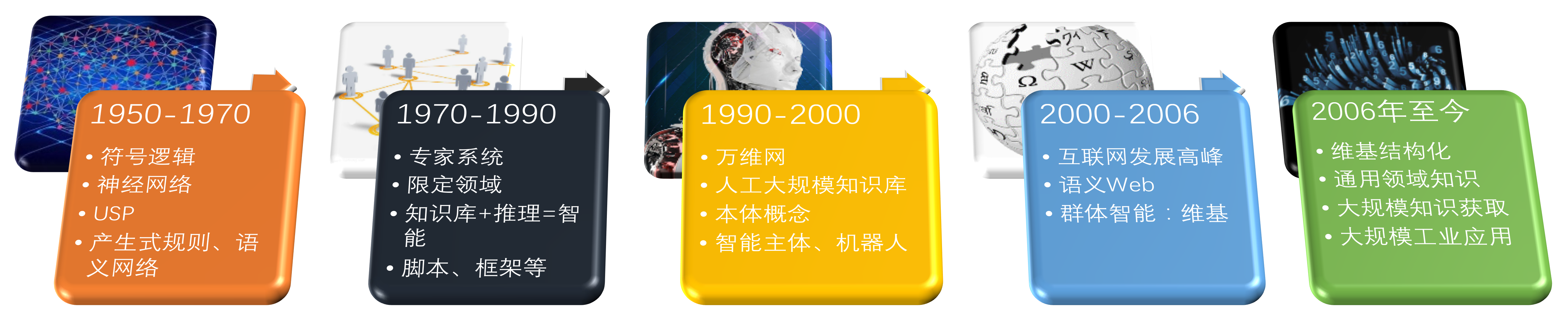
2.8 MB
{kind=link}

61.9 KB
{kind=link}
218.0 KB
AI/Knowledge Graph/survey.md
0 → 100644
AI/Knowledge Graph/讨论报告.md
0 → 100644
Algorithm/试卷/19_new.txt
0 → 100644
{kind=link}

82.8 KB
{kind=link}

71.9 KB
{kind=link}

70.9 KB
{kind=link}

69.3 KB
{kind=link}

88.0 KB
{kind=link}
1.7 MB
{kind=link}

2.1 MB
{kind=link}

2.1 MB
{kind=link}

1.8 MB
{kind=link}

1.5 MB
{kind=link}

1.8 MB
{kind=link}

1.9 MB
{kind=link}

2.1 MB
{kind=link}

55.2 KB
{kind=link}

61.7 KB
Algorithm/试卷/very_old/1.jpg
0 → 100644
{kind=link}

24.9 KB
Algorithm/试卷/very_old/2.jpg
0 → 100644
{kind=link}

20.0 KB
Algorithm/试卷/very_old/3.jpg
0 → 100644
{kind=link}

39.3 KB
Algorithm/试卷/very_old/4.jpg
0 → 100644
{kind=link}
47.7 KB
Algorithm/试卷/very_old/5.jpg
0 → 100644
{kind=link}

22.5 KB
Algorithm/试卷/very_old/6.jpg
0 → 100644
{kind=link}
30.8 KB
Algorithm/试卷/very_old/7.jpg
0 → 100644
{kind=link}

33.4 KB
文件已添加
English/Translation final.pptx
0 → 100644
文件已添加
文件已添加
文件已添加
{kind=link}

74.1 KB
文件已添加
{kind=link}

79.6 KB
{kind=link}

79.8 KB
文件已添加
{kind=link}

73.1 KB
English/英语考试翻译预测.docx
0 → 100644
文件已添加
FormatTemplate/深圳大学学报理工版模板.docx
0 → 100644
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
此差异已折叠。
此差异已折叠。
{kind=link}

37.2 KB
{kind=link}
8.2 KB
{kind=link}

1.6 MB
{kind=link}

12.0 KB
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
{kind=link}

66.6 KB
{kind=link}

28.0 KB
{kind=link}

55.3 KB
{kind=link}

42.0 KB
{kind=link}

28.8 KB
文件已添加
ThesisWritingGuide/example.png
0 → 100644
{kind=link}

2.7 MB
ThesisWritingGuide/note.md
0 → 100644
ThesisWritingGuide/要点.png
0 → 100644
{kind=link}

2.3 MB