Add Automata
Showing
Automata/Question3.py
0 → 100644
Automata/Question4.py
0 → 100644
Automata/example.py
0 → 100644
Automata/imgs/Q1.vsdx
0 → 100644
文件已添加
Automata/imgs/Q1_5.jpg
0 → 100644
{kind=link}
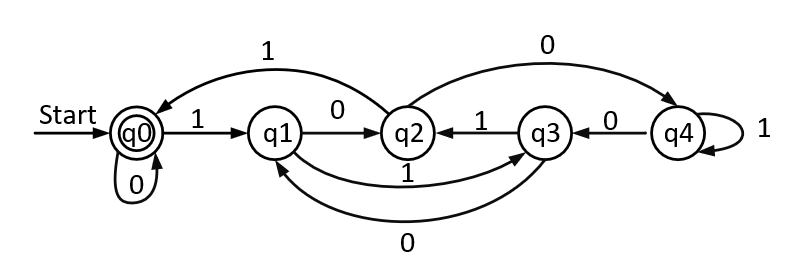
21.7 KB
Automata/imgs/Q1_5逆.jpg
0 → 100644
{kind=link}
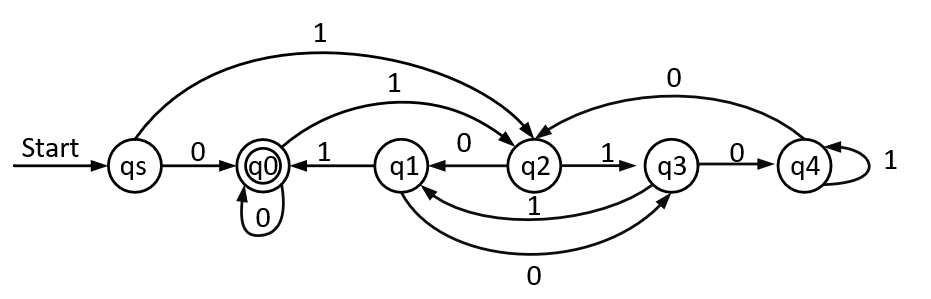
27.6 KB
Automata/imgs/Q1状态转移图.jpg
0 → 100644
{kind=link}
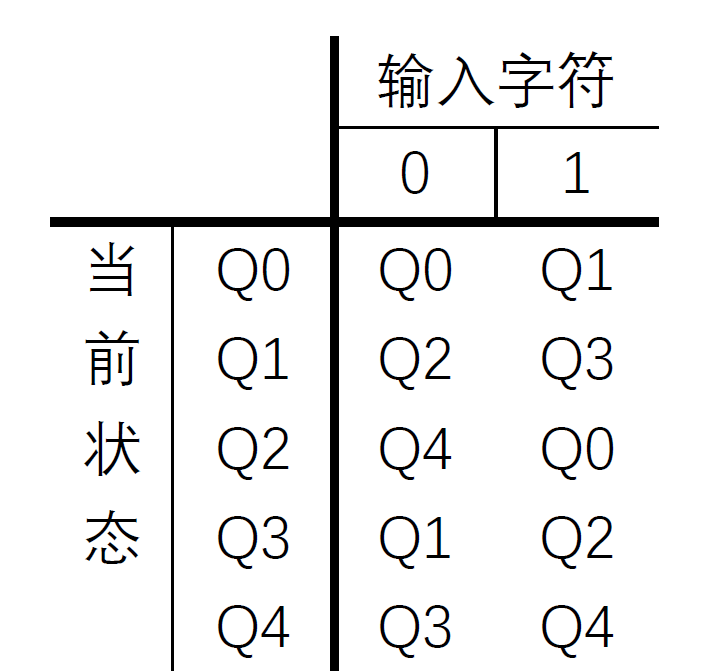
27.5 KB
Automata/imgs/Q1状态转移图.pdf
0 → 100644
文件已添加
Automata/input.txt
0 → 100644
Automata/myre.py
0 → 100644
Automata/nfa/__init__.py
0 → 100644
Automata/nfa/builder.py
0 → 100644
Automata/nfa/cell.py
0 → 100644
Automata/nfa/lexer.py
0 → 100644
Automata/nfa/run.py
0 → 100644
Automata/solution.md
0 → 100644
Automata/test.py
0 → 100644