Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Hypo
candock
提交
9c04cece
C
candock
项目概览
Hypo
/
candock
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
candock
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
9c04cece
编写于
4月 25, 2019
作者:
H
hypox64
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add simple_test.py
上级
44c1ecd5
变更
12
隐藏空白更改
内联
并排
Showing
12 changed file
with
286 addition
and
113 deletion
+286
-113
README.md
README.md
+12
-2
dataloader.py
dataloader.py
+20
-12
datasets/simple_test_data.npy
datasets/simple_test_data.npy
+0
-0
how_to_run.md
how_to_run.md
+39
-0
image/confusion_mat
image/confusion_mat
+23
-2
image/multi_scale_resnet_1d_network.png
image/multi_scale_resnet_1d_network.png
+0
-0
models/multi_scale_resnet_1d.py
models/multi_scale_resnet_1d.py
+4
-2
options.py
options.py
+8
-1
simple_test.py
simple_test.py
+55
-0
statistics.py
statistics.py
+43
-22
train.py
train.py
+40
-34
transformer.py
transformer.py
+42
-38
未找到文件。
README.md
浏览文件 @
9c04cece
# candock
这是一个用于记录毕业设计的日志仓库,其目的是尝试多种不同的深度神经网络结构(如LSTM,RESNET,DFCNN等)对单通道EEG进行自动化睡眠阶段分期.我们相信这些代码同时可以用于其他生理信号(如ECG,EMG等)的分类.希望这将有助于您的研究.
<br>
## 如何运行
如果你需要运行这些代码(训练自己的模型或者使用预训练模型进行测试)请进入以下页面
<br>
[
How to run codes
](
https://github.com/HypoX64/candock/blob/master/how_to_run.md
)
<br>
## 数据集
使用了三个睡眠数据集进行测试,分别是:
[
[CinC Challenge 2018]
](
https://physionet.org/physiobank/database/challenge/2018/#files
)
[
[sleep-edf
]
](https://www.physionet.org/physiobank/database/sleep-edf/)
[
[sleep-edfx]
](
https://www.physionet.org/physiobank/database/sleep-edfx/
)
<br>
对于CinC Challenge 2018数据集,使用其C4-M1通道
<br>
对于sleep-edfx与sleep-edf数据集,使用Fpz-Cz通道
<br>
...
...
@@ -25,6 +28,11 @@
!
[
image
](
https://github.com/HypoX64/candock/blob/master/image/spectrum_Stage3.png
)
!
[
image
](
https://github.com/HypoX64/candock/blob/master/image/spectrum_REM.png
)
<br>
*
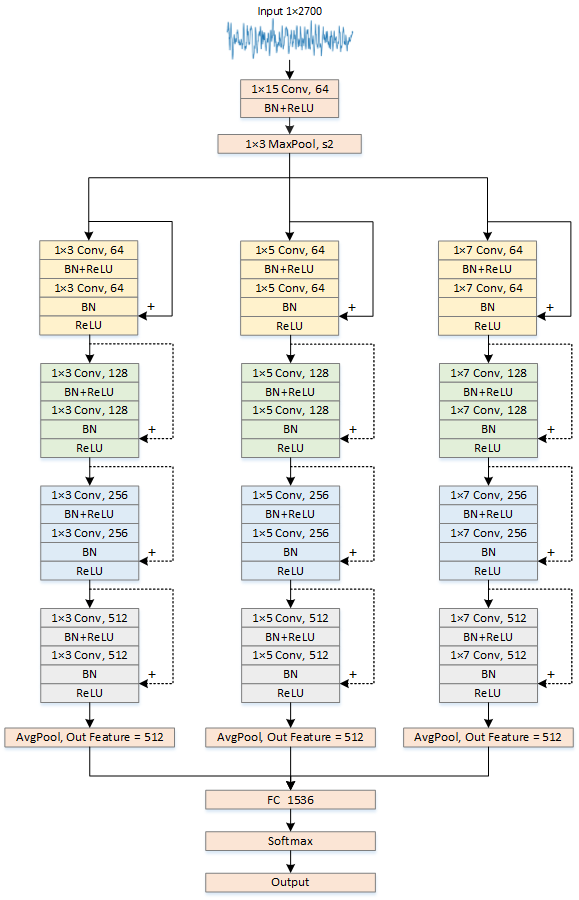
multi_scale_resnet_1d 网络结构
<br>
该网络参考
[
geekfeiw / Multi-Scale-1D-ResNet
](
https://github.com/geekfeiw/Multi-Scale-1D-ResNet
)
<br>
修改后的网络结构如图:
<br>
!
[
image
](
https://github.com/HypoX64/candock/blob/master/image/multi_scale_resnet_1d_network.png
)
<br>
*
关于交叉验证
<br>
为了便于与其他文献中的方法便于比较,使用了两种交叉验证方法
<br>
1.
对于同一数据集,采用5倍K-fold交叉验证
<br>
...
...
@@ -48,9 +56,10 @@
| Network | Label average recall | Label average accuracy | error rate |
| :----------------------- | :------------------- | ---------------------- | ---------- |
| lstm | | | |
| resnet18_1d |
| |
|
| resnet18_1d |
0.8263 | 0.9601 | 0.0997
|
| DFCNN+resnet18 | 0.8261 | 0.9594 | 0.1016 |
| DFCNN+multi_scale_resnet | 0.8196 | 0.9631 | 0.0922 |
| multi_scale_resnet_1d | 0.8400 | 0.9595 | 0.1013 |
*
sleep-edfx(only sleep time)
<br>
...
...
@@ -69,7 +78,7 @@
| resnet18_1d | | | |
| DFCNN+resnet18 | 0.7823 | 0.909 | 0.2276 |
| DFCNN+resnet50 | | | |
#### Subject Cross-Validation Results
## 心路历程
...
...
@@ -78,3 +87,4 @@
*
2019/04/04 需要增加k-fold+受试者交叉验证才够严谨...
*
2019/04/05 清明节…看文献,还是按照大部分人的做法来做吧,使用5倍K-fold和数据集间的交叉验证,这样方便与其他人的方法做横向比较. 不行,这里要吐槽一下,别人做k-fold完全是因为数据集太小了…这上百Gb的数据做K-fold…真的是多此一举,结果根本不会有什么差别…完全是浪费计算资源…
*
2019/04/09 回老家了,啊!!!!我的毕业论文啊。。。。写不完了!
*
2019/04/13 回学校撸论文了,回去的几天莫名奇妙多了两个star...额,这也行
\ No newline at end of file
dataloader.py
浏览文件 @
9c04cece
...
...
@@ -6,6 +6,7 @@ import time
import
torch
import
random
import
dsp
import
transformer
# import pyedflib
import
mne
...
...
@@ -41,7 +42,7 @@ def trimdata(data,num):
def
reducesample
(
data
,
mult
):
return
data
[::
mult
]
def
loaddata
(
dirpath
,
signal_name
,
BID
=
'median'
,
filter
=
True
):
def
loaddata
(
dirpath
,
signal_name
,
BID
,
filter
=
True
):
#load
signals
=
loadsignals
(
dirpath
,
signal_name
)
if
filter
:
...
...
@@ -52,9 +53,11 @@ def loaddata(dirpath,signal_name,BID = 'median',filter = True):
stages
=
reducesample
(
stages
,
2
)
#Balance individualized differences
if
BID
==
'median'
:
signals
=
(
signals
*
8
/
(
np
.
median
(
abs
(
signals
)))).
astype
(
np
.
int16
)
elif
BID
==
'std'
:
signals
=
(
signals
*
55
/
(
np
.
std
(
signals
))).
astype
(
np
.
int16
)
signals
=
(
signals
*
10
/
(
np
.
median
(
abs
(
signals
))))
elif
BID
==
'5_95_th'
:
tmp
=
np
.
sort
(
signals
.
reshape
(
-
1
))
th_5
=
tmp
[
int
(
0.05
*
len
(
tmp
))]
signals
=
transformer
.
Normalize
(
signals
,
1000
,
0
,
th_5
)
#trim
signals
=
trimdata
(
signals
,
3000
)
stages
=
trimdata
(
stages
,
3000
)
...
...
@@ -70,9 +73,9 @@ def loaddata(dirpath,signal_name,BID = 'median',filter = True):
stages
=
np
.
delete
(
stages
,
i
-
cnt
,
axis
=
0
)
cnt
+=
1
# print(stages.shape,signals.shape)
return
signals
,
stages
return
signals
.
astype
(
np
.
float16
),
stages
.
astype
(
np
.
int16
)
def
loaddata_sleep_edf
(
opt
,
filedir
,
filenum
,
signal_name
,
BID
=
'median'
,
filter
=
True
):
def
loaddata_sleep_edf
(
opt
,
filedir
,
filenum
,
signal_name
,
BID
):
filenames
=
os
.
listdir
(
filedir
)
for
filename
in
filenames
:
if
str
(
filenum
)
in
filename
and
'Hypnogram'
in
filename
:
...
...
@@ -105,8 +108,6 @@ def loaddata_sleep_edf(opt,filedir,filenum,signal_name,BID = 'median',filter = T
signals
.
append
(
eeg
[
events
[
i
][
0
]:
events
[
i
][
0
]
+
3000
])
stages
=
np
.
array
(
stages
)
signals
=
np
.
array
(
signals
)
if
BID
==
'median'
:
signals
=
signals
*
13
/
np
.
median
(
np
.
abs
(
signals
))
# #select sleep time
if
opt
.
select_sleep_time
:
...
...
@@ -123,10 +124,17 @@ def loaddata_sleep_edf(opt,filedir,filenum,signal_name,BID = 'median',filter = T
cnt
+=
1
print
(
'shape:'
,
signals
.
shape
,
stages
.
shape
)
return
signals
.
astype
(
np
.
int16
),
stages
.
astype
(
np
.
int16
)
if
BID
==
'median'
:
signals
=
signals
*
10
/
np
.
median
(
np
.
abs
(
signals
))
elif
BID
==
'5_95_th'
:
tmp
=
np
.
sort
(
signals
.
reshape
(
-
1
))
th_5
=
tmp
[
int
(
0.05
*
len
(
tmp
))]
signals
=
transformer
.
Normalize
(
signals
,
1000
,
0
,
th_5
)
return
signals
.
astype
(
np
.
float16
),
stages
.
astype
(
np
.
int16
)
def
loaddataset
(
opt
,
filedir
,
dataset_name
=
'CinC_Challenge_2018'
,
signal_name
=
'C4-M1'
,
num
=
100
,
BID
=
'median'
,
shuffle
=
True
):
def
loaddataset
(
opt
,
filedir
,
dataset_name
=
'CinC_Challenge_2018'
,
signal_name
=
'C4-M1'
,
num
=
100
,
BID
=
'median'
,
shuffle
=
True
):
print
(
'load dataset, please wait...'
)
filenames
=
os
.
listdir
(
filedir
)
...
...
@@ -140,7 +148,7 @@ def loaddataset(opt,filedir,dataset_name = 'CinC_Challenge_2018',signal_name = '
for
i
,
filename
in
enumerate
(
filenames
[:
num
],
0
):
try
:
signal
,
stage
=
loaddata
(
os
.
path
.
join
(
filedir
,
filename
),
signal_name
,
BID
=
None
)
signal
,
stage
=
loaddata
(
os
.
path
.
join
(
filedir
,
filename
),
signal_name
,
BID
=
BID
)
if
i
==
0
:
signals
=
signal
.
copy
()
stages
=
stage
.
copy
()
...
...
@@ -159,7 +167,7 @@ def loaddataset(opt,filedir,dataset_name = 'CinC_Challenge_2018',signal_name = '
cnt
=
0
for
filename
in
filenames
:
if
'PSG'
in
filename
:
signal
,
stage
=
loaddata_sleep_edf
(
opt
,
filedir
,
filename
[
2
:
6
],
signal_name
=
signal_name
)
signal
,
stage
=
loaddata_sleep_edf
(
opt
,
filedir
,
filename
[
2
:
6
],
signal_name
,
BID
)
if
cnt
==
0
:
signals
=
signal
.
copy
()
stages
=
stage
.
copy
()
...
...
datasets/simple_test_data.npy
0 → 100644
浏览文件 @
9c04cece
文件已添加
how_to_run.md
0 → 100644
浏览文件 @
9c04cece
## Prerequisites
-
Linux, Windows,mac
-
CPU or NVIDIA GPU + CUDA CuDNN
-
Python 3.5+
-
Pytroch 1.0+
## Dependencies
This code depends on torchvision, numpy, scipy, h5py, matplotlib, mne = 18.0, opencv-python, requests, hashlib, memory_profiler, available via pip install.
<br>
For example:
<br>
```
bash
pip3
install
matplotlib
```
But for mne, you may run:
<br>
```
bash
pip3
install
-U
https://api.github.com/repos/mne-tools/mne-python/zipball/master
```
## Getting Started
### Clone this repo:
```
bash
git clone https://github.com/HypoX64/candock
cd
candock
```
### Train
*
download datasets
```
bash
python3 download_dataset.py
```
*
choose your options and run
```
bash
python3 train.py
--dataset_dir
'./datasets/sleep-edfx/'
--dataset_name
sleep-edf
--signal_name
'EEG Fpz-Cz'
--sample_num
8
--model_name
lstm
--batchsize
64
--network_save_freq
5
--epochs
50
--lr
0.0005
--select_sleep_time
```
*
Notes
<br>
If want to use cpu to train, please use --no_cuda
### Simple Test
```
bash
python3 simple_test.py
--pretrained
--no_cuda
```
\ No newline at end of file
image/confusion_mat
浏览文件 @
9c04cece
...
...
@@ -2,9 +2,9 @@ Confusion matrix:
Pred
S
1 S2 S3
REM WAKE
S
3 S2 S1
REM WAKE
S2
True S
3
True S
1
REM
WAKE
...
...
@@ -12,6 +12,17 @@ True S3
5-Fold Cross-Validation Results
-------------------sleep-edf-------------------
resnet18_1d
final: test avg_recall:0.8263 avg_acc:0.9601 error:0.0997
confusion_mat:
[[1133 148 7 3 0]
[ 296 2968 120 195 3]
[ 3 60 368 149 18]
[ 3 99 135 1342 18]
[ 9 7 190 37 7729]]
statistics of dataset [S3 S2 S1 R W]:
[1291 3582 598 1597 7972]
DFCNN+resnet18
final: test avg_recall:0.8261 avg_acc:0.9594 error:0.1016
confusion_mat:
...
...
@@ -23,6 +34,16 @@ confusion_mat:
statistics of dataset [S3 S2 S1 R W]:
[ 268 725 106 314 1611]
multi_scale_resnet_1d
confusion_mat:
final: test avg_recall:0.84 avg_acc:0.9595 error:0.1013
[[1159 114 10 3 1]
[ 335 2961 153 143 5]
[ 4 45 436 102 13]
[ 0 100 241 1244 9]
[ 2 2 214 27 7717]]
statistics of dataset [S3 S2 S1 R W]:
[1287 3597 600 1594 7962]
-------------------sleep-edfx(only sleep time)-------------------
...
...
image/multi_scale_resnet_1d_network.png
0 → 100644
浏览文件 @
9c04cece
46.3 KB
models/multi_scale_resnet_1d.py
浏览文件 @
9c04cece
...
...
@@ -32,12 +32,14 @@ class Route(nn.Module):
self
.
block1
=
ResidualBlock
(
64
,
64
,
kernel_size
,
stride
=
1
)
self
.
block2
=
ResidualBlock
(
64
,
128
,
kernel_size
)
self
.
block3
=
ResidualBlock
(
128
,
256
,
kernel_size
)
self
.
block4
=
ResidualBlock
(
256
,
512
,
kernel_size
)
self
.
avgpool
=
nn
.
AdaptiveAvgPool1d
(
1
)
def
forward
(
self
,
x
):
x
=
self
.
block1
(
x
)
x
=
self
.
block2
(
x
)
x
=
self
.
block3
(
x
)
x
=
self
.
block4
(
x
)
x
=
self
.
avgpool
(
x
)
return
x
...
...
@@ -45,7 +47,7 @@ class Multi_Scale_ResNet(nn.Module):
def
__init__
(
self
,
inchannel
,
num_classes
):
super
(
Multi_Scale_ResNet
,
self
).
__init__
()
self
.
pre_conv
=
nn
.
Sequential
(
nn
.
Conv1d
(
inchannel
,
64
,
kernel_size
=
7
,
stride
=
2
,
padding
=
3
,
bias
=
False
),
nn
.
Conv1d
(
inchannel
,
64
,
kernel_size
=
15
,
stride
=
2
,
padding
=
7
,
bias
=
False
),
nn
.
BatchNorm1d
(
64
),
nn
.
ReLU
(
inplace
=
True
),
nn
.
MaxPool1d
(
kernel_size
=
3
,
stride
=
2
,
padding
=
1
)
...
...
@@ -53,7 +55,7 @@ class Multi_Scale_ResNet(nn.Module):
self
.
Route1
=
Route
(
3
)
self
.
Route2
=
Route
(
5
)
self
.
Route3
=
Route
(
7
)
self
.
fc
=
nn
.
Linear
(
256
*
3
,
num_classes
)
self
.
fc
=
nn
.
Linear
(
512
*
3
,
num_classes
)
def
forward
(
self
,
x
):
x
=
self
.
pre_conv
(
x
)
...
...
options.py
浏览文件 @
9c04cece
...
...
@@ -2,6 +2,7 @@ import argparse
import
os
import
numpy
as
np
import
torch
#python3 train.py --dataset_dir './datasets/sleep-edfx/' --dataset_name sleep-edf --signal_name 'EEG Fpz-Cz' --sample_num 8 --model_name multi_scale_resnet_1d --batchsize 32 --network_save_freq 100 --epochs 40 --lr 0.0005
#python3 train.py --dataset_dir '/media/hypo/Hypo/physionet_org_train' --dataset_name CinC_Challenge_2018 --signal_name C4-M1 --sample_num 200 --model_name resnet18 --batchsize 32 --epochs 10 --fold_num 5 --pretrained
#python3 train_new.py --dataset_dir '/media/hypo/Hypo/physionet_org_train' --dataset_name CinC_Challenge_2018 --signal_name C4-M1 --sample_num 10 --model_name LSTM --batchsize 32 --network_save_freq 100 --epochs 10
#python3 train.py --dataset_dir '/media/hypo/Hypo/physionet_org_train' --dataset_name CinC_Challenge_2018 --signal_name C4-M1 --sample_num 10 --model_name resnet18 --batchsize 32
...
...
@@ -19,6 +20,8 @@ class Options():
self
.
parser
.
add_argument
(
'--no_cudnn'
,
action
=
'store_true'
,
help
=
'if input, do not use cudnn'
)
self
.
parser
.
add_argument
(
'--pretrained'
,
action
=
'store_true'
,
help
=
'if input, use pretrained models'
)
self
.
parser
.
add_argument
(
'--lr'
,
type
=
float
,
default
=
0.001
,
help
=
'learning rate'
)
self
.
parser
.
add_argument
(
'--Cross_Validation'
,
type
=
str
,
default
=
'k_fold'
,
help
=
'k-fold | subject'
)
self
.
parser
.
add_argument
(
'--BID'
,
type
=
str
,
default
=
'None'
,
help
=
'Balance individualized differences 5_95_th | median |None'
)
self
.
parser
.
add_argument
(
'--fold_num'
,
type
=
int
,
default
=
5
,
help
=
'k-fold'
)
self
.
parser
.
add_argument
(
'--batchsize'
,
type
=
int
,
default
=
16
,
help
=
'batchsize'
)
self
.
parser
.
add_argument
(
'--dataset_dir'
,
type
=
str
,
default
=
'./datasets/sleep-edfx/'
,
...
...
@@ -27,7 +30,7 @@ class Options():
self
.
parser
.
add_argument
(
'--select_sleep_time'
,
action
=
'store_true'
,
help
=
'if input, for sleep-cassette only use sleep time to train'
)
self
.
parser
.
add_argument
(
'--signal_name'
,
type
=
str
,
default
=
'EEG Fpz-Cz'
,
help
=
'Choose the EEG channel C4-M1|EEG Fpz-Cz'
)
self
.
parser
.
add_argument
(
'--sample_num'
,
type
=
int
,
default
=
20
,
help
=
'the amount you want to load'
)
self
.
parser
.
add_argument
(
'--model_name'
,
type
=
str
,
default
=
'
resnet18
'
,
help
=
'Choose model'
)
self
.
parser
.
add_argument
(
'--model_name'
,
type
=
str
,
default
=
'
lstm
'
,
help
=
'Choose model'
)
self
.
parser
.
add_argument
(
'--epochs'
,
type
=
int
,
default
=
50
,
help
=
'end epoch'
)
self
.
parser
.
add_argument
(
'--weight_mod'
,
type
=
str
,
default
=
'avg_best'
,
help
=
'Choose weight mode: avg_best|normal'
)
self
.
parser
.
add_argument
(
'--network_save_freq'
,
type
=
int
,
default
=
5
,
help
=
'the freq to save network'
)
...
...
@@ -43,6 +46,10 @@ class Options():
if
self
.
opt
.
dataset_name
==
'sleep-edf'
:
self
.
opt
.
sample_num
=
8
if
self
.
opt
.
no_cuda
:
self
.
opt
.
no_cudnn
=
True
if
self
.
opt
.
fold_num
==
0
:
self
.
opt
.
fold_num
=
1
# if self.opt.weight_mod == 'normal':
...
...
simple_test.py
0 → 100644
浏览文件 @
9c04cece
import
os
import
numpy
as
np
import
torch
import
matplotlib.pyplot
as
plt
import
util
import
transformer
import
dataloader
from
options
import
Options
from
creatnet
import
CreatNet
'''
@hypox64
19/04/13
'''
opt
=
Options
().
getparse
()
net
=
CreatNet
(
opt
.
model_name
)
if
not
opt
.
no_cuda
:
net
.
cuda
()
if
not
opt
.
no_cudnn
:
import
torch.backends.cudnn
as
cudnn
cudnn
.
benchmark
=
True
if
opt
.
pretrained
:
net
.
load_state_dict
(
torch
.
load
(
'./checkpoints/pretrained/'
+
opt
.
model_name
+
'.pth'
))
# N3(S4+S3)->0 N2->1 N1->2 REM->3 W->4
stage_map
=
{
0
:
'stage3'
,
1
:
'stage2'
,
2
:
'stage3'
,
3
:
'REM'
,
4
:
'Wake'
}
def
runmodel
(
eegdata
):
eegdata
=
eegdata
.
reshape
(
1
,
-
1
)
eegdata
=
transformer
.
ToInputShape
(
eegdata
,
opt
.
model_name
,
test_flag
=
True
)
eegdata
=
transformer
.
ToTensor
(
eegdata
,
no_cuda
=
opt
.
no_cuda
)
with
torch
.
no_grad
():
out
=
net
(
eegdata
)
pred
=
torch
.
max
(
out
,
1
)[
1
]
pred_stage
=
pred
.
data
.
cpu
().
numpy
()
return
pred_stage
[
0
]
'''
you can change your input data here.
but the data needs meet the following conditions:
1.record for 1 epoch(30s)
2.fs = 100Hz
3.uv
'''
eegdata
=
np
.
load
(
'./datasets/simple_test_data.npy'
)
print
(
'the shape of eegdata:'
,
eegdata
.
shape
)
stage
=
runmodel
(
eegdata
)
print
(
'the sleep stage of this signal is:'
,
stage_map
[
stage
])
plt
.
plot
(
eegdata
)
plt
.
show
()
statistics.py
浏览文件 @
9c04cece
...
...
@@ -8,26 +8,46 @@ def stage(stages):
for
i
in
range
(
len
(
stages
)):
stage_cnt
[
stages
[
i
]]
+=
1
stage_cnt_per
=
stage_cnt
/
len
(
stages
)
util
.
writelog
(
'statistics of dataset [S3 S2 S1 R W]: '
+
str
(
stage_cnt
))
print
(
'statistics of dataset [S3 S2 S1 R W]:
\n
'
,
stage_cnt
,
'
\n
'
,
stage_cnt_per
)
util
.
writelog
(
'statistics of dataset [S3 S2 S1 R W]: '
+
str
(
stage_cnt
),
True
)
return
stage_cnt
,
stage_cnt_per
def
result
(
mat
):
def
Kappa
(
mat
):
mat
=
mat
/
10000
# avoid overflow
mat_length
=
np
.
sum
(
mat
)
wide
=
mat
.
shape
[
0
]
po
=
0.0
;
pe
=
0.0
for
i
in
range
(
wide
):
po
=
po
+
mat
[
i
][
i
]
pe
=
pe
+
np
.
sum
(
mat
[:,
i
])
*
np
.
sum
(
mat
[
i
,:])
po
=
po
/
mat_length
pe
=
pe
/
(
mat_length
*
mat_length
)
k
=
(
po
-
pe
)
/
(
1
-
pe
)
return
k
def
result
(
mat
,
print_sub
=
False
):
wide
=
mat
.
shape
[
0
]
sub_acc
=
np
.
zeros
(
wide
)
sub_recall
=
np
.
zeros
(
wide
)
sub_sp
=
np
.
zeros
(
wide
)
err
=
0
for
i
in
range
(
wide
):
if
np
.
sum
(
mat
[
i
])
==
0
:
sub_recall
[
i
]
=
0
else
:
sub_recall
[
i
]
=
mat
[
i
,
i
]
/
np
.
sum
(
mat
[
i
])
TP
=
mat
[
i
,
i
]
FN
=
np
.
sum
(
mat
[
i
])
-
mat
[
i
,
i
]
TN
=
(
np
.
sum
(
mat
)
-
np
.
sum
(
mat
[
i
])
-
np
.
sum
(
mat
[:,
i
])
+
mat
[
i
,
i
])
FP
=
np
.
sum
(
mat
[:,
i
])
-
mat
[
i
,
i
]
err
+=
mat
[
i
,
i
]
sub_acc
[
i
]
=
(
np
.
sum
(
mat
)
-
((
np
.
sum
(
mat
[
i
])
+
np
.
sum
(
mat
[:,
i
]))
-
2
*
mat
[
i
,
i
]))
/
np
.
sum
(
mat
)
sub_acc
[
i
]
=
(
TP
+
TN
)
/
(
TP
+
FN
+
TN
+
FP
)
sub_recall
[
i
]
=
(
TP
)
/
np
.
clip
((
TP
+
FN
),
1e-5
,
1e10
)
sub_sp
[
i
]
=
TN
/
np
.
clip
((
TN
+
FP
),
1e-5
,
1e10
)
if
print_sub
==
True
:
print
(
'sub_recall:'
,
sub_recall
,
'
\n
sub_acc:'
,
sub_acc
,
'
\n
sub_sp:'
,
sub_sp
)
avg_recall
=
np
.
mean
(
sub_recall
)
avg_acc
=
np
.
mean
(
sub_acc
)
avg_sp
=
np
.
mean
(
sub_sp
)
err
=
1
-
err
/
np
.
sum
(
mat
)
return
avg_recall
,
avg_acc
,
err
k
=
Kappa
(
mat
)
return
round
(
avg_recall
,
4
),
round
(
avg_acc
,
4
),
round
(
avg_sp
,
4
),
round
(
err
,
4
),
round
(
k
,
4
)
def
stagefrommat
(
mat
):
wide
=
mat
.
shape
[
0
]
...
...
@@ -36,34 +56,35 @@ def stagefrommat(mat):
stage_num
[
i
]
=
np
.
sum
(
mat
[
i
])
util
.
writelog
(
'statistics of dataset [S3 S2 S1 R W]:
\n
'
+
str
(
stage_num
),
True
)
def
show
(
plot_result
,
epoch
):
train
_recall
=
np
.
array
(
plot_result
[
'train'
])
test
_recall
=
np
.
array
(
plot_result
[
'test'
])
train
=
np
.
array
(
plot_result
[
'train'
])
test
=
np
.
array
(
plot_result
[
'test'
])
plt
.
figure
(
'running recall'
)
plt
.
clf
()
train_
recall_x
=
np
.
linspace
(
0
,
epoch
,
len
(
train_recall
))
test_
recall_x
=
np
.
linspace
(
0
,
int
(
epoch
),
len
(
test_recall
))
train_
x
=
np
.
linspace
(
0
,
epoch
,
len
(
train
))
test_
x
=
np
.
linspace
(
0
,
int
(
epoch
),
len
(
test
))
plt
.
xlabel
(
'Epoch'
)
plt
.
ylabel
(
'%'
)
plt
.
ylim
((
0
,
1
))
plt
.
ylim
((
0
,
1
00
))
if
epoch
<
10
:
plt
.
xlim
((
0
,
10
))
else
:
plt
.
xlim
((
0
,
epoch
))
plt
.
plot
(
train_recall_x
,
train_recall
,
label
=
'train'
,
linewidth
=
2.0
,
color
=
'red'
)
plt
.
plot
(
test_recall_x
,
test_recall
,
label
=
'test'
,
linewidth
=
2.0
,
color
=
'blue'
)
plt
.
legend
(
loc
=
4
)
plt
.
savefig
(
'./running_recall.png'
)
plt
.
plot
(
train_x
,
train
*
100
,
label
=
'train'
,
linewidth
=
2.0
,
color
=
'red'
)
plt
.
plot
(
test_x
,
test
*
100
,
label
=
'test'
,
linewidth
=
2.0
,
color
=
'blue'
)
plt
.
legend
(
loc
=
1
)
plt
.
title
(
'Running err.'
,
fontsize
=
'large'
)
plt
.
savefig
(
'./running_err.png'
)
# plt.draw()
# plt.pause(0.01)
def
main
():
plot_result
=
{
'train'
:
[
0.2303303787268332
,
0.2119345588626961
,
0.20542007990053074
,
0.20353191245282734
,
0.2032570804016917
,
0.20269640625503033
,
0.2020943574651975
,
0.2108357726067258
,
0.21750990713964172
,
0.23142651474994708
,
0.2318236991596459
,
0.22924187151697578
,
0.22830716248841004
,
0.2331831179181414
,
0.23604422314519158
,
0.23734486777406488
,
0.23929925551037354
,
0.2451802483014293
,
0.24753448439761755
,
0.24964581836870603
,
0.2506097959967858
,
0.2497704229822455
],
'test'
:
[
0.28670433145009416
,
0.29533625933982305
,
0.2927783086111587
,
0.28665535025585603
,
0.2884532914652956
]}
show
(
plot_result
,
10
)
mat
=
[[
37980
,
1322
,
852
,
2
,
327
],[
3922
,
8784
,
3545
,
0
,
2193
],[
1756
,
5136
,
99564
,
1091
,
991
],[
18
,
1
,
7932
,
4063
,
14
],[
1361
,
1680
,
465
,
0
,
23931
]]
mat
=
np
.
array
(
mat
)
avg_recall
,
avg_acc
,
err
=
result
(
mat
)
print
(
avg_recall
,
avg_acc
,
err
)
if
__name__
==
'__main__'
:
main
()
train.py
浏览文件 @
9c04cece
import
numpy
as
np
import
time
import
util
import
os
import
time
import
transformer
import
dataloader
# import models
from
creatnet
import
CreatNet
import
numpy
as
np
import
torch
from
torch
import
nn
,
optim
import
statistics
import
torch.backends.cudnn
as
cudnn
import
heatmap
from
options
import
Options
import
warnings
warnings
.
filterwarnings
(
"ignore"
)
import
util
import
transformer
import
dataloader
import
statistics
import
heatmap
from
creatnet
import
CreatNet
from
options
import
Options
opt
=
Options
().
getparse
()
localtime
=
time
.
asctime
(
time
.
localtime
(
time
.
time
()))
util
.
writelog
(
'
\n\n
'
+
str
(
localtime
)
+
'
\n
'
+
str
(
opt
))
t1
=
time
.
time
()
signals
,
stages
=
dataloader
.
loaddataset
(
opt
,
opt
.
dataset_dir
,
opt
.
dataset_name
,
opt
.
signal_name
,
opt
.
sample_num
,
shuffle
=
True
,
BID
=
None
)
signals
,
stages
=
dataloader
.
loaddataset
(
opt
,
opt
.
dataset_dir
,
opt
.
dataset_name
,
opt
.
signal_name
,
opt
.
sample_num
,
shuffle
=
False
,
BID
=
opt
.
BID
)
stage_cnt
,
stage_cnt_per
=
statistics
.
stage
(
stages
)
signals
,
stages
=
transformer
.
batch_generator
(
signals
,
stages
,
opt
.
batchsize
,
shuffle
=
True
)
if
opt
.
Cross_Validation
==
'k_fold'
:
signals
,
stages
=
transformer
.
batch_generator
(
signals
,
stages
,
opt
.
batchsize
,
shuffle
=
True
)
train_sequences
,
test_sequences
=
transformer
.
k_fold_generator
(
len
(
stages
),
opt
.
fold_num
)
elif
opt
.
Cross_Validation
==
'subject'
:
util
.
writelog
(
'train statistics:'
,
True
)
stage_cnt
,
stage_cnt_per
=
statistics
.
stage
(
stages
[:
int
(
0.8
*
len
(
stages
))])
util
.
writelog
(
'test statistics:'
,
True
)
stage_cnt
,
stage_cnt_per
=
statistics
.
stage
(
stages
[
int
(
0.8
*
len
(
stages
)):])
signals
,
stages
=
transformer
.
batch_generator_subject
(
signals
,
stages
,
opt
.
batchsize
,
shuffle
=
False
)
train_sequences
,
test_sequences
=
transformer
.
k_fold_generator
(
len
(
stages
),
1
)
batch_length
=
len
(
stages
)
print
(
'length of batch:'
,
batch_length
)
train_sequences
,
test_sequences
=
transformer
.
k_fold_generator
(
batch_length
,
opt
.
fold_num
)
show_freq
=
int
(
len
(
train_sequences
[
0
])
/
5
)
util
.
show_menory
()
t2
=
time
.
time
()
...
...
@@ -64,7 +74,7 @@ def evalnet(net,signals,stages,sequences,epoch,plot_result={},mode = 'part'):
confusion_mat
=
np
.
zeros
((
5
,
5
),
dtype
=
int
)
for
i
,
sequence
in
enumerate
(
sequences
,
1
):
signal
=
transformer
.
ToInputShape
(
signals
[
sequence
],
opt
.
model_name
,
test_flag
=
True
)
signal
=
transformer
.
ToInputShape
(
signals
[
sequence
],
opt
.
model_name
,
opt
.
BID
,
test_flag
=
True
)
signal
,
stage
=
transformer
.
ToTensor
(
signal
,
stages
[
sequence
],
no_cuda
=
opt
.
no_cuda
)
with
torch
.
no_grad
():
out
=
net
(
signal
)
...
...
@@ -77,11 +87,10 @@ def evalnet(net,signals,stages,sequences,epoch,plot_result={},mode = 'part'):
if
mode
==
'part'
:
plot_result
[
'test'
].
append
(
statistics
.
result
(
confusion_mat
)[
0
])
else
:
recall
,
acc
,
error
=
statistics
.
result
(
confusion_mat
)
plot_result
[
'test'
].
append
(
recall
)
recall
,
acc
,
sp
,
err
,
k
=
statistics
.
result
(
confusion_mat
)
plot_result
[
'test'
].
append
(
err
)
heatmap
.
draw
(
confusion_mat
,
name
=
'test'
)
print
(
'test avg_recall:'
,
'%.4f'
%
recall
,
'avg_acc:'
,
'%.4f'
%
acc
,
'error:'
,
'%.4f'
%
error
)
#util.writelog('epoch:'+str(epoch)+' test avg_recall:'+str(round(recall,4))+' avg_acc:'+str(round(acc,4))+' error:'+str(round(error,4)))
print
(
'avg_recall:'
,
'%.4f'
%
recall
,
'avg_acc:'
,
'%.4f'
%
acc
,
'avg_sp:'
,
'%.4f'
%
sp
,
'error:'
,
'%.4f'
%
err
,
'Kappa:'
,
'%.4f'
%
k
)
return
plot_result
,
confusion_mat
print
(
'begin to train ...'
)
...
...
@@ -92,7 +101,7 @@ for fold in range(opt.fold_num):
net
.
load_state_dict
(
torch
.
load
(
'./checkpoints/pretrained/'
+
opt
.
model_name
+
'.pth'
))
if
not
opt
.
no_cuda
:
net
.
cuda
()
plot_result
=
{
'train'
:[
0
],
'test'
:[
0
]}
plot_result
=
{
'train'
:[
1.
],
'test'
:[
1.
]}
confusion_mats
=
[]
for
epoch
in
range
(
opt
.
epochs
):
...
...
@@ -102,9 +111,9 @@ for fold in range(opt.fold_num):
net
.
train
()
for
i
,
sequence
in
enumerate
(
train_sequences
[
fold
],
1
):
signal
=
transformer
.
ToInputShape
(
signals
[
sequence
],
opt
.
model_name
,
test_flag
=
False
)
signal
=
transformer
.
ToInputShape
(
signals
[
sequence
],
opt
.
model_name
,
opt
.
BID
,
test_flag
=
False
)
signal
,
stage
=
transformer
.
ToTensor
(
signal
,
stages
[
sequence
],
no_cuda
=
opt
.
no_cuda
)
out
=
net
(
signal
)
loss
=
criterion
(
out
,
stage
)
pred
=
torch
.
max
(
out
,
1
)[
1
]
...
...
@@ -117,7 +126,7 @@ for fold in range(opt.fold_num):
for
x
in
range
(
len
(
pred
)):
confusion_mat
[
stage
[
x
]][
pred
[
x
]]
+=
1
if
i
%
show_freq
==
0
:
plot_result
[
'train'
].
append
(
statistics
.
result
(
confusion_mat
)[
0
])
plot_result
[
'train'
].
append
(
statistics
.
result
(
confusion_mat
)[
3
])
heatmap
.
draw
(
confusion_mat
,
name
=
'train'
)
# plot_result=evalnet(net,signals_eval,stages_eval,plot_result,show_freq,mode = 'part')
statistics
.
show
(
plot_result
,
epoch
+
i
/
(
batch_length
*
0.8
))
...
...
@@ -134,18 +143,15 @@ for fold in range(opt.fold_num):
net
.
cuda
()
t2
=
time
.
time
()
print
(
'cost time: %.2f'
%
(
t2
-
t1
),
's'
)
pos
=
plot_result
[
'test'
].
index
(
max
(
plot_result
[
'test'
]))
-
1
if
epoch
+
1
==
1
:
print
(
'cost time: %.2f'
%
(
t2
-
t1
),
's'
)
pos
=
plot_result
[
'test'
].
index
(
min
(
plot_result
[
'test'
]))
-
1
final_confusion_mat
=
final_confusion_mat
+
confusion_mats
[
pos
]
recall
,
acc
,
error
=
statistics
.
result
(
confusion_mats
[
pos
])
print
(
'
\n
fold:'
,
fold
+
1
,
'finished'
,
' avg_recall:'
,
'%.4f'
%
recall
,
'avg_acc:'
,
'%.4f'
%
acc
,
'error:'
,
'%.4f'
%
error
,
'
\n
'
)
util
.
writelog
(
'fold:'
+
str
(
fold
+
1
)
+
' test avg_recall:'
+
str
(
round
(
recall
,
4
))
+
' avg_acc:'
+
str
(
round
(
acc
,
4
))
+
' error:'
+
str
(
round
(
error
,
4
)))
util
.
writelog
(
'fold:'
+
str
(
fold
+
1
)
+
' recall,acc,sp,err,k: '
+
str
(
statistics
.
result
(
confusion_mats
[
pos
])),
True
)
print
(
'------------------'
)
util
.
writelog
(
'confusion_mat:
\n
'
+
str
(
confusion_mat
))
recall
,
acc
,
error
=
statistics
.
result
(
final_confusion_mat
)
#print('all finished!\n',final_confusion_mat)
#print('avg_recall:','%.4f' % recall,'avg_acc:','%.4f' % acc,'error:','%.4f' % error)
util
.
writelog
(
'final:'
+
' test avg_recall:'
+
str
(
round
(
recall
,
4
))
+
' avg_acc:'
+
str
(
round
(
acc
,
4
))
+
' error:'
+
str
(
round
(
error
,
4
)),
True
)
util
.
writelog
(
'confusion_mat:
\n
'
+
str
(
confusion_mat
),
True
)
statistics
.
stagefrommat
(
confusion_mat
)
util
.
writelog
(
'final: '
+
'recall,acc,sp,err,k: '
+
str
(
statistics
.
result
(
final_confusion_mat
)),
True
)
util
.
writelog
(
'confusion_mat:
\n
'
+
str
(
final_confusion_mat
),
True
)
statistics
.
stagefrommat
(
final_confusion_mat
)
heatmap
.
draw
(
final_confusion_mat
,
name
=
'final_test'
)
\ No newline at end of file
transformer.py
浏览文件 @
9c04cece
...
...
@@ -15,6 +15,17 @@ def shuffledata(data,target):
np
.
random
.
shuffle
(
target
)
# return data,target
def
batch_generator_subject
(
data
,
target
,
batchsize
,
shuffle
=
True
):
data_test
=
data
[
int
(
0.8
*
len
(
target
)):]
data_train
=
data
[
0
:
int
(
0.8
*
len
(
target
))]
target_test
=
target
[
int
(
0.8
*
len
(
target
)):]
target_train
=
target
[
0
:
int
(
0.8
*
len
(
target
))]
data_test
,
target_test
=
batch_generator
(
data_test
,
target_test
,
batchsize
)
data_train
,
target_train
=
batch_generator
(
data_train
,
target_train
,
batchsize
)
data
=
np
.
concatenate
((
data_train
,
data_test
),
axis
=
0
)
target
=
np
.
concatenate
((
target_train
,
target_test
),
axis
=
0
)
return
data
,
target
def
batch_generator
(
data
,
target
,
batchsize
,
shuffle
=
True
):
if
shuffle
:
shuffledata
(
data
,
target
)
...
...
@@ -26,13 +37,18 @@ def batch_generator(data,target,batchsize,shuffle = True):
def
k_fold_generator
(
length
,
fold_num
):
sequence
=
np
.
linspace
(
0
,
length
-
1
,
length
,
dtype
=
'int'
)
train_length
=
int
(
length
/
fold_num
*
(
fold_num
-
1
))
test_length
=
int
(
length
/
fold_num
)
train_sequence
=
np
.
zeros
((
fold_num
,
train_length
),
dtype
=
'int'
)
test_sequence
=
np
.
zeros
((
fold_num
,
test_length
),
dtype
=
'int'
)
for
i
in
range
(
fold_num
):
test_sequence
[
i
]
=
(
sequence
[
test_length
*
i
:
test_length
*
(
i
+
1
)])[:
test_length
]
train_sequence
[
i
]
=
np
.
concatenate
((
sequence
[
0
:
test_length
*
i
],
sequence
[
test_length
*
(
i
+
1
):]),
axis
=
0
)[:
train_length
]
if
fold_num
==
1
:
train_sequence
=
sequence
[
0
:
int
(
0.8
*
length
)].
reshape
(
1
,
-
1
)
test_sequence
=
sequence
[
int
(
0.8
*
length
):].
reshape
(
1
,
-
1
)
else
:
train_length
=
int
(
length
/
fold_num
*
(
fold_num
-
1
))
test_length
=
int
(
length
/
fold_num
)
train_sequence
=
np
.
zeros
((
fold_num
,
train_length
),
dtype
=
'int'
)
test_sequence
=
np
.
zeros
((
fold_num
,
test_length
),
dtype
=
'int'
)
for
i
in
range
(
fold_num
):
test_sequence
[
i
]
=
(
sequence
[
test_length
*
i
:
test_length
*
(
i
+
1
)])[:
test_length
]
train_sequence
[
i
]
=
np
.
concatenate
((
sequence
[
0
:
test_length
*
i
],
sequence
[
test_length
*
(
i
+
1
):]),
axis
=
0
)[:
train_length
]
return
train_sequence
,
test_sequence
...
...
@@ -52,14 +68,19 @@ def Normalize(data,maxmin,avg,sigma):
data
=
np
.
clip
(
data
,
-
maxmin
,
maxmin
)
return
(
data
-
avg
)
/
sigma
def
ToTensor
(
data
,
target
,
no_cuda
=
False
):
data
=
torch
.
from_numpy
(
data
).
float
()
target
=
torch
.
from_numpy
(
target
).
long
()
if
not
no_cuda
:
data
=
data
.
cuda
()
target
=
target
.
cuda
()
return
data
,
target
def
ToTensor
(
data
,
target
=
None
,
no_cuda
=
False
):
if
target
is
not
None
:
data
=
torch
.
from_numpy
(
data
).
float
()
target
=
torch
.
from_numpy
(
target
).
long
()
if
not
no_cuda
:
data
=
data
.
cuda
()
target
=
target
.
cuda
()
return
data
,
target
else
:
data
=
torch
.
from_numpy
(
data
).
float
()
if
not
no_cuda
:
data
=
data
.
cuda
()
return
data
def
random_transform_1d
(
data
,
finesize
,
test_flag
):
length
=
len
(
data
)
...
...
@@ -76,7 +97,7 @@ def random_transform_1d(data,finesize,test_flag):
result
=
result
[::
-
1
]
#random amp
result
=
result
*
random
.
uniform
(
0.
95
,
1.05
)
result
=
result
*
random
.
uniform
(
0.
8
,
1.2
)
return
result
...
...
@@ -100,26 +121,8 @@ def random_transform_2d(img,finesize = (224,122),test_flag = True):
return
result
# def random_transform_2d(img,finesize,test_flag):
# h,w = img.shape[:2]
# if test_flag:
# h_move = 2
# w_move = int((w-finesize)*0.5)
# result = img[h_move:h_move+finesize,w_move:w_move+finesize]
# else:
# #random crop
# h_move = int(5*random.random()) #do not loss low freq signal infos
# w_move = int((w-finesize)*random.random())
# result = img[h_move:h_move+finesize,w_move:w_move+finesize]
# #random flip
# if random.random()<0.5:
# result = result[:,::-1]
# #random amp
# result = result*random.uniform(0.95,1.05)+random.uniform(-0.02,0.02)
# return result
def
ToInputShape
(
data
,
net_name
,
BID
=
'None'
,
norm
=
True
,
test_flag
=
False
):
def
ToInputShape
(
data
,
net_name
,
norm
=
True
,
test_flag
=
False
):
data
=
data
.
astype
(
np
.
float32
)
batchsize
=
data
.
shape
[
0
]
if
net_name
==
'lstm'
:
...
...
@@ -127,16 +130,17 @@ def ToInputShape(data,net_name,norm=True,test_flag = False):
for
i
in
range
(
0
,
batchsize
):
randomdata
=
random_transform_1d
(
data
[
i
],
finesize
=
2700
,
test_flag
=
test_flag
)
result
.
append
(
dsp
.
getfeature
(
randomdata
))
if
norm
and
BID
!=
'5_95_th'
:
result
=
Normalize
(
result
,
maxmin
=
1000
,
avg
=
0
,
sigma
=
50
)
result
=
np
.
array
(
result
).
reshape
(
batchsize
,
2700
*
5
)
elif
net_name
in
[
'cnn_1d'
,
'resnet18_1d'
,
'multi_scale_resnet_1d'
]:
result
=
[]
for
i
in
range
(
0
,
batchsize
):
randomdata
=
random_transform_1d
(
data
[
i
],
finesize
=
2700
,
test_flag
=
test_flag
)
# result.append(dsp.getfeature(randomdata,ch_num = 6))
result
.
append
(
randomdata
)
result
=
np
.
array
(
result
)
if
norm
:
result
=
Normalize
(
result
,
maxmin
=
1000
,
avg
=
0
,
sigma
=
100
0
)
if
norm
and
BID
!=
'5_95_th'
:
result
=
Normalize
(
result
,
maxmin
=
1000
,
avg
=
0
,
sigma
=
5
0
)
result
=
result
.
reshape
(
batchsize
,
1
,
2700
)
elif
net_name
in
[
'squeezenet'
,
'multi_scale_resnet'
,
'dfcnn'
,
'resnet18'
,
'densenet121'
,
'densenet201'
,
'resnet101'
,
'resnet50'
]:
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}