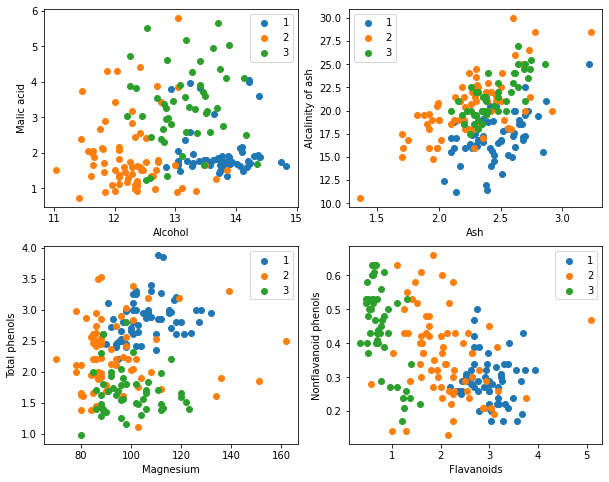
在Wine数据集的官网[Wine Data Set](http://archive.ics.uci.edu/ml/datasets/Wine)上下载[wine.data](http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data)文件。
| Data Set Characteristics: | Multivariate | Number of Instances: | 178 |
| Attribute Characteristics: | Integer, Real | Number of Attributes: | 13 |
{kind=link}
{kind=link}