docs: update docs and server ports
Showing
docs/images/deploy-failed.png
已删除
100644 → 0
{kind=link}

72.5 KB
docs/images/di-api.png
已删除
100644 → 0
{kind=link}
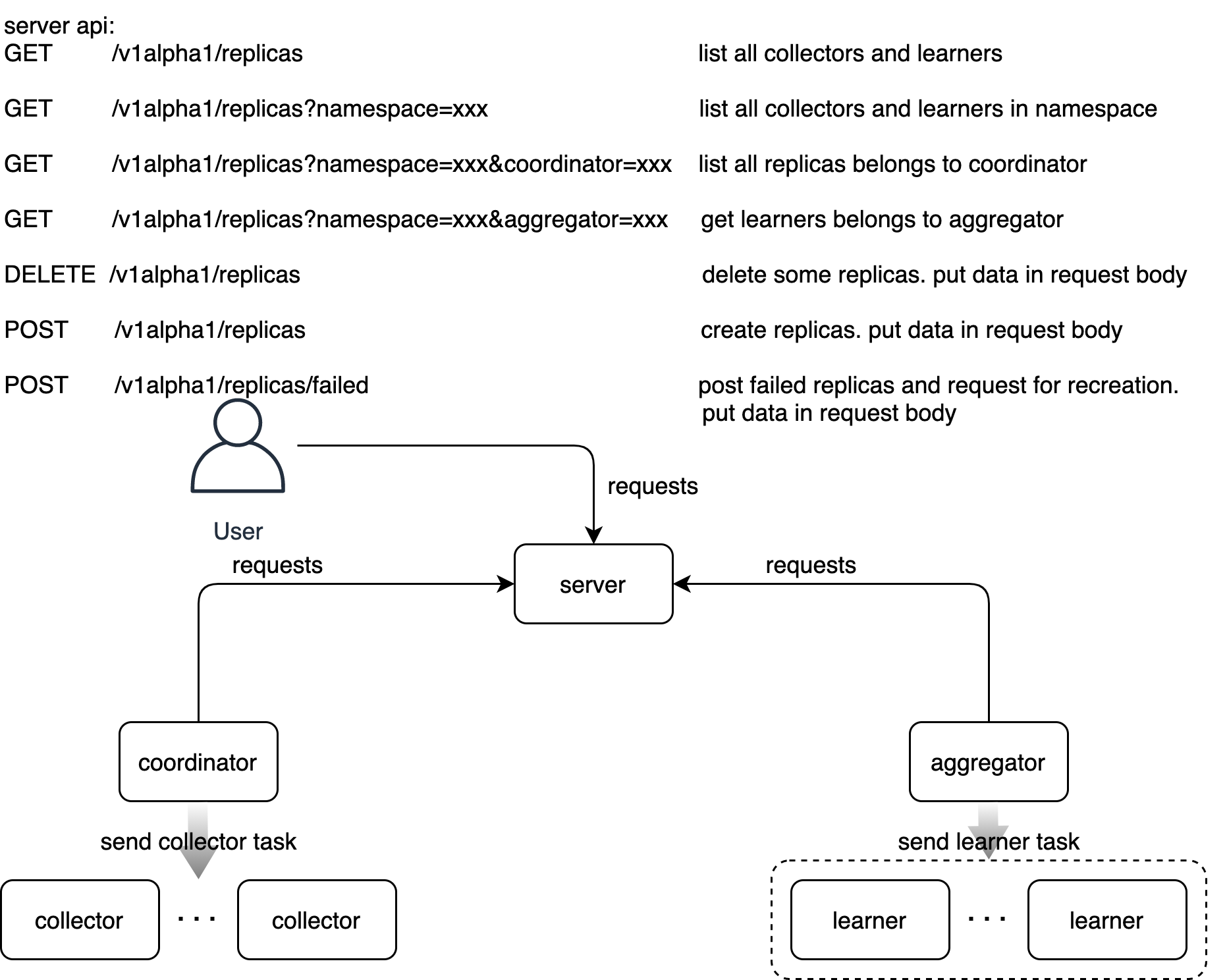
235.0 KB
docs/images/di-arch.svg
已删除
100644 → 0
{kind=link}
因为 它太大了无法显示 source diff 。你可以改为 查看blob。
docs/images/di-engine-arch.png
0 → 100644
{kind=link}
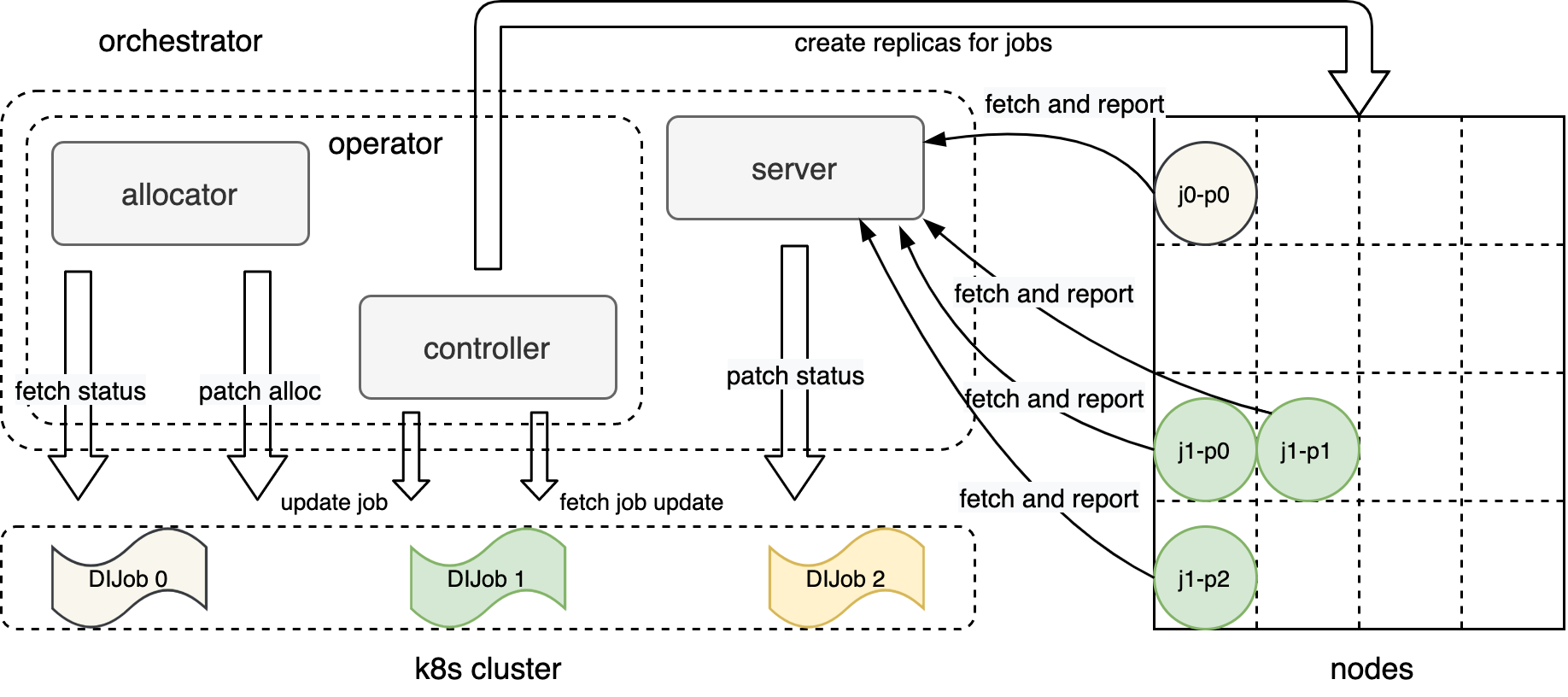
201.2 KB
{kind=link}
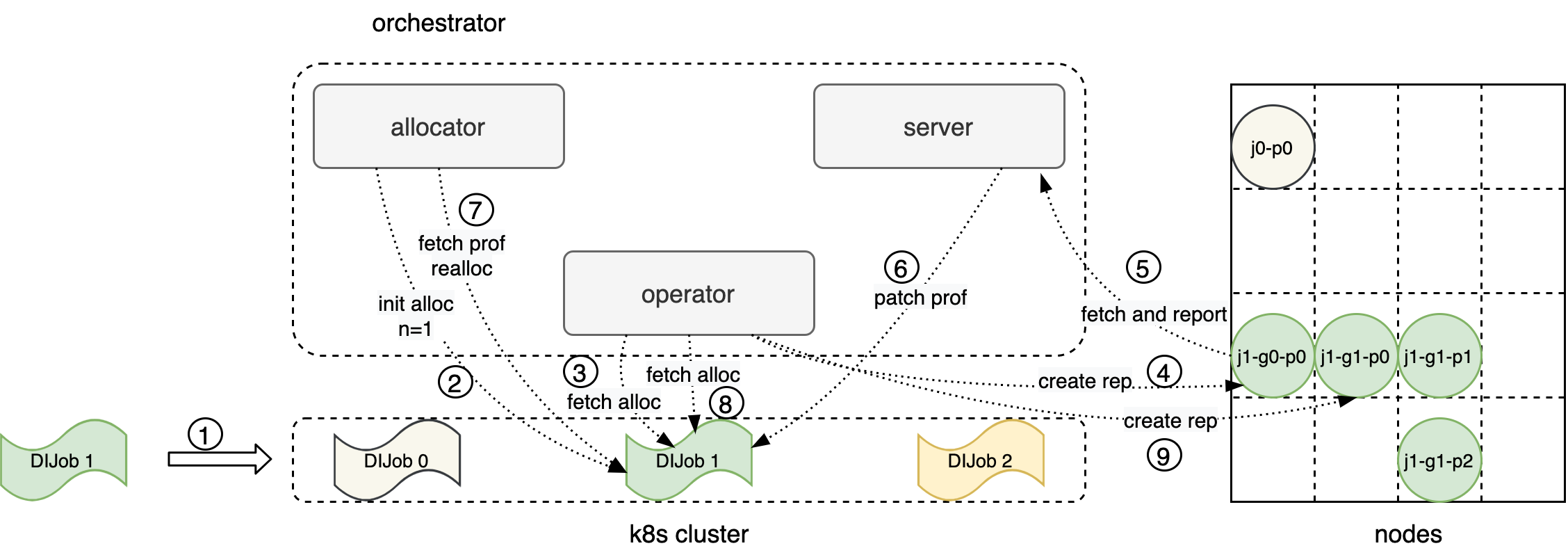
210.2 KB
{kind=link}
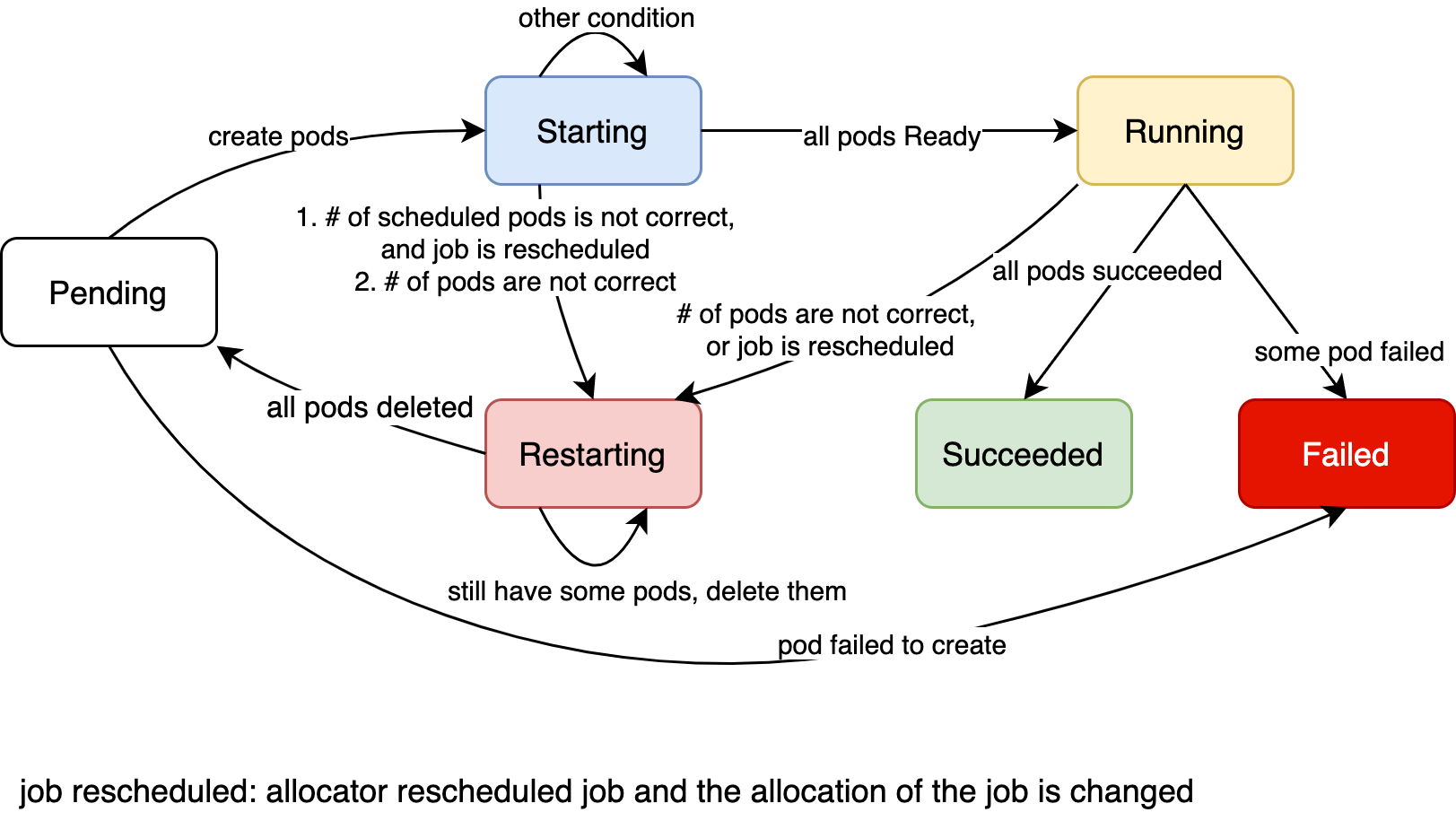
184.6 KB