Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
ElasticCTR
提交
fa6207cf
E
ElasticCTR
项目概览
PaddlePaddle
/
ElasticCTR
通知
8
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
E
ElasticCTR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
未验证
提交
fa6207cf
编写于
4月 08, 2020
作者:
D
Dong Daxiang
提交者:
GitHub
4月 08, 2020
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #4 from wangjiawei04/master
Add HDFS tutorial
上级
42106f1b
2c6414bb
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
80 addition
and
9 deletion
+80
-9
HDFS_TUTORIAL.md
HDFS_TUTORIAL.md
+59
-0
README.md
README.md
+18
-6
doc/buy_bcc.png
doc/buy_bcc.png
+0
-0
elastic-ctr-cli/data.config
elastic-ctr-cli/data.config
+3
-3
未找到文件。
HDFS_TUTORIAL.md
0 → 100644
浏览文件 @
fa6207cf
# 如何搭建HDFS集群
## 综述
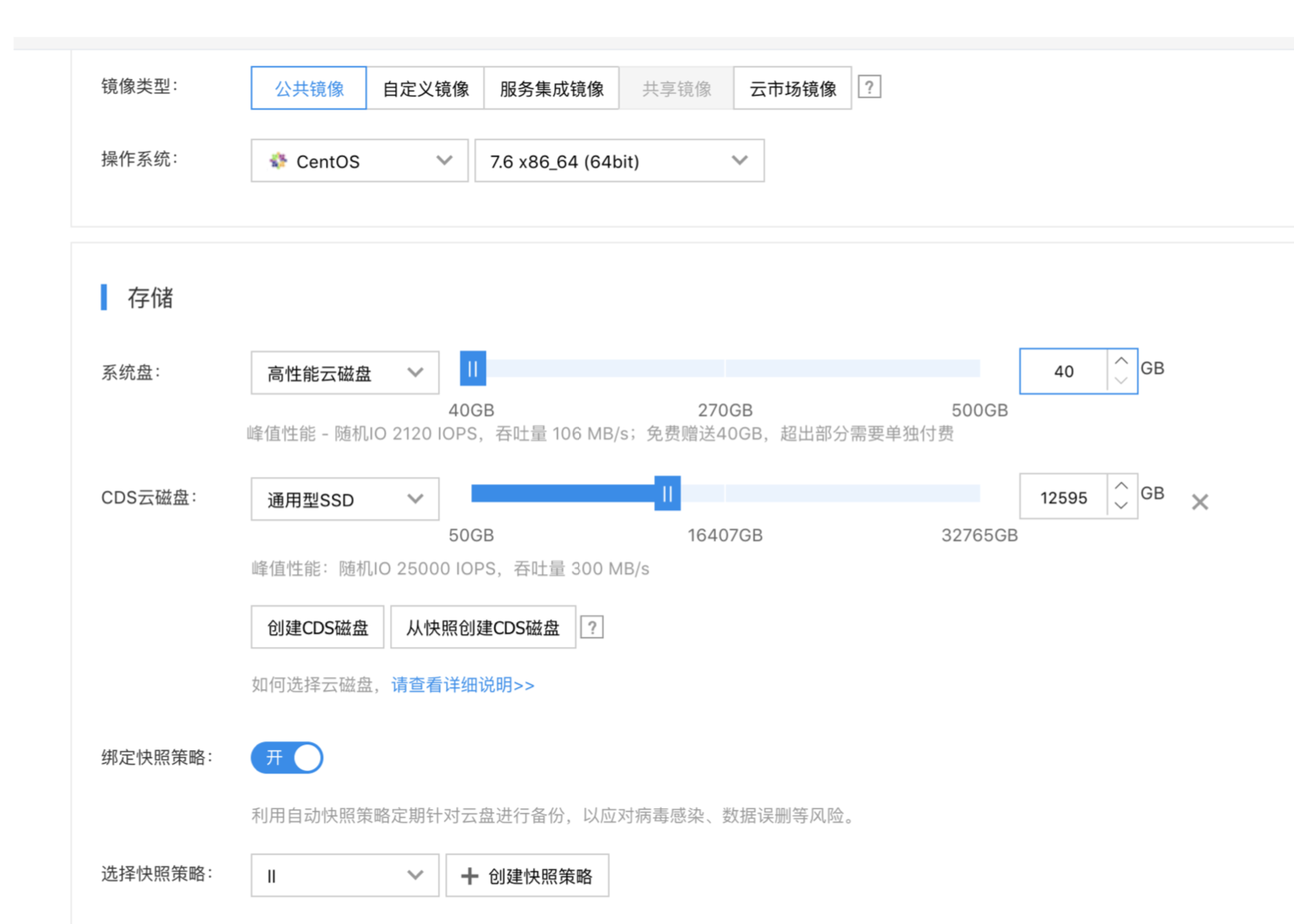
本篇文章只是用于demo的HDFS集群搭建教程,用于跑通ElasticCTR的各个流程。本文将会带着大家在百度云的节点上搭建一个HDFS,并将Criteo数据集按照ElasticCTR的数据集格式要求,存放在HDFS上。
## 购买BCC
搭建 HDFS 集群的过程较为复杂,首先需要购买一个 BCC 实例
<p
align=
"center"
>
<br>
<img
src=
'./doc/buy_bcc.png'
>
<br>
<p>
在 BCC 实例当中购买较大的 CDS 云磁盘。
## 安装并启动Hadoop
在进入 BCC 之后首先需要用 fdisk 工具确认分区是否已经安装。
选择 hadoop-2.8.5.tar.gz。下载后解压把 hadoop-2.8.5 目录 move 到/usr/local 目录下。 在/usr/local/hadoop-2.8.5/etc/hadoop/下,编辑 core-site.xml文件,修改为
```
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://${LOCAL_IP}:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop</value>
</property>
</configuration>
```
此处
`$LOCAL_IP`
推荐用内网的 IP,也就是在 ifconfig 下为
`192.168`
开头的 IP,在 K8S 当中也可以被访问 到。
在
`slave`
文件下输入
`root@127.0.0.1`
接下来配置无密码访问,首先要
`ssh-keygen`
,无论提示什么全部回车数次之后,用
`ssh-copy-id`
命令把无密码访问配置到
`127.0.0.1`
,
`localhost`
,
`0.0.0.0`
几个 IP 地址。
把
`/usr/local/hadoop-2.8.5/etc/hadoop`
设置为
`$HADOOP_HOME`
再把
`$HADOOP_HOME/bin`
放在
`$PATH`
下。如果输入
`hadoop`
命令可以被执行,就执行
`hadoop namenode format`
。
最后在
`/usr/local/hadoop-2.8.5/sbin`
目录下运行 ,
`start-all.sh`
。
以上操作之后,HDFS 服务就启动完毕,接下来就创建流式训练的文件夹
`/train_data/`
,使用命令
`hdfs dfs -mkdir hdfs://$IP:9000/train_data/`
## 复制Criteo数据集到HDFS
接下来从
`https://paddle-serving.bj.bcebos.com/criteo_ctr_example/criteo_demo.tar.gz`
下载数据集,解压之后在criteo_demo下
执行
`hdfs dfs -put * hdfs://$IP:9000/train_data/20200401`
`$IP`
就是先前到HDFS地址。
这样,就在train_data下目录到20200401目录下存放了5个小时的训练集。20200401可以改动成任意一个日期。
在主页面的教程中,
`data.config`
文件就是用来现在配置的HDFS信息,日期信息会在这里被调用。
README.md
浏览文件 @
fa6207cf
# Elastic
REC
# Elastic
CTR
Elastic
REC
是分布式训练CTR预估任务和Serving流程一键部署的方案,用户只需配置数据源、样本格式即可完成一系列的训练与预测任务
Elastic
CTR
是分布式训练CTR预估任务和Serving流程一键部署的方案,用户只需配置数据源、样本格式即可完成一系列的训练与预测任务
*
[
1. 总体概览
](
#head1
)
*
[
2. 配置集群
](
#head2
)
...
...
@@ -14,22 +14,24 @@ ElasticREC是分布式训练CTR预估任务和Serving流程一键部署的方案
1.
快速部署
Elastic
REC当前提供的方案是基于百度云的Kubernetes集群进行部署,用户可以很容易扩展到其他原生的Kubernetes环境运行ElasticREC
。
Elastic
CTR当前提供的方案是基于百度云的Kubernetes集群进行部署,用户可以很容易扩展到其他原生的Kubernetes环境运行ElasticCTR
。
2.
高性能
Elastic
REC采用PaddlePaddle提供的全异步分布式训练方式,在保证模型训练效果的前提下,近乎线性的扩展能力可以大幅度节省训练资源。在线服务方面,ElasticREC
采用Paddle Serving中高吞吐、低延迟的稀疏参数预估引擎,高并发条件下是常见开源组件吞吐量的10倍以上。
Elastic
CTR采用PaddlePaddle提供的全异步分布式训练方式,在保证模型训练效果的前提下,近乎线性的扩展能力可以大幅度节省训练资源。在线服务方面,ElasticCTR
采用Paddle Serving中高吞吐、低延迟的稀疏参数预估引擎,高并发条件下是常见开源组件吞吐量的10倍以上。
3.
可定制
用户可以通过统一的配置文件,修改训练中的训练方式和基本配置,包括在离线训练方式、训练过程可视化指标、HDFS上的存储配置等。除了通过修改统一配置文件进行训练任务配置外,Elastic
REC
采用全开源软件栈,方便用户进行快速的二次开发和改造。底层的Kubernetes、Volcano可以轻松实现对上层任务的灵活调度策略;基于PaddlePaddle的灵活组网能力、飞桨的分布式训练引擎Fleet和远程预估服务Paddle Serving,用户可以对训练模型、并行训练的模式、远程预估服务进行快速迭代;MLFlow提供的训练任务可视化能力,用户可以快速增加系统监控需要的各种指标。
用户可以通过统一的配置文件,修改训练中的训练方式和基本配置,包括在离线训练方式、训练过程可视化指标、HDFS上的存储配置等。除了通过修改统一配置文件进行训练任务配置外,Elastic
CTR
采用全开源软件栈,方便用户进行快速的二次开发和改造。底层的Kubernetes、Volcano可以轻松实现对上层任务的灵活调度策略;基于PaddlePaddle的灵活组网能力、飞桨的分布式训练引擎Fleet和远程预估服务Paddle Serving,用户可以对训练模型、并行训练的模式、远程预估服务进行快速迭代;MLFlow提供的训练任务可视化能力,用户可以快速增加系统监控需要的各种指标。
本方案整体结构请参照这篇文章
[
ElasticCTR架构
](
elasticctr_arch.md
)
## <span id='head2'>2. 配置集群</span>
运行本方案前,需要用户已经搭建好k8s集群,并安装好volcano组件。k8s环境部署比较复杂,本文不涉及。百度智能云CCE容器引擎申请后即可使用,百度云上创建k8s的方法用户可以参考这篇文档
[
百度云创建k8s教程及使用指南
](
cluster_config.md
)
。此外,Elastic CTR还支持在其他云上部署,可以参考以下两篇文档
[
华为云创建k8s集群
](
huawei_k8s.md
)
,
[
aws创建k8s集群
](
aws_k8s.md
)
运行本方案前,需要用户已经搭建好k8s集群,并安装好volcano组件。k8s环境部署比较复杂,本文不涉及。百度智能云CCE容器引擎申请后即可使用,百度云上创建k8s的方法用户可以参考这篇文档
[
百度云创建k8s教程及使用指南
](
cluster_config.md
)
。此外,Elastic CTR还支持在其他云上部署,可以参考以下两篇文档
[
华为云创建k8s集群
](
huawei_k8s.md
)
,
[
aws创建k8s集群
](
aws_k8s.md
)
.
准备好K8S集群之后,我们需要配置HDFS作为数据集的来源
[
HDFS配置教程
](
HDFS_TUTORIAL.md
)
## <span id='head3'>3. 一键部署教程</span>
...
...
@@ -68,6 +70,16 @@ $show $click $feasign0:$slot0 $feasign1:$slot1 $feasign2:$slot2......
-
**-f|--datafile**
数据路径文件,需要指明HDFS地址并指定起始与截止日期(截止日期可选)
-
**-s|--slot_conf**
特征槽位配置文件,请注意文件后缀必须为'.txt'
以下是
`data.config`
文件,其中
`START_DATE_HR`
和
`END_DATE_HR`
就是我们在上一步配置HDFS的路径。
```
export HDFS_ADDRESS="hdfs://${IP}:9000" # HDFS地址
export HDFS_UGI="root,i" # HDFS用户名密码
export START_DATE_HR=20200401/00 # 训练集开始时间,代表2020年4月1日0点
export END_DATE_HR=20200401/03 # 训练集结束时间,代表2020年4月1日3点
export DATASET_PATH="/train_data" # 训练集在HDFS上的前缀
export SPARSE_DIM="1000001" # 稀疏参数维度,可不动
```
脚本的使用示例如下:
```
bash elastic-control.sh -r -u 4 -m 20 -t 2 -p 2 -b 5 -s slot.conf -f data.config
...
...
doc/buy_bcc.png
0 → 100644
浏览文件 @
fa6207cf
245.1 KB
elastic-ctr-cli/data.config
浏览文件 @
fa6207cf
export
HDFS_ADDRESS
=
"hdfs://
192.168.48.87
:9000"
export
HDFS_ADDRESS
=
"hdfs://
${IP}
:9000"
export
HDFS_UGI
=
"root,i"
export
START_DATE_HR
=
20
19122
1
/
00
export
END_DATE_HR
=
20
191221
/
09
export
START_DATE_HR
=
20
20040
1
/
00
export
END_DATE_HR
=
20
200401
/
03
export
DATASET_PATH
=
"/train_data"
export
SPARSE_DIM
=
"1000001"
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}