Add Prioritized DQN (#326)
- add prioritized dqn - fix#239
Showing
文件已添加
examples/Prioritized_DQN/atari.py
0 → 120000
{kind=link}
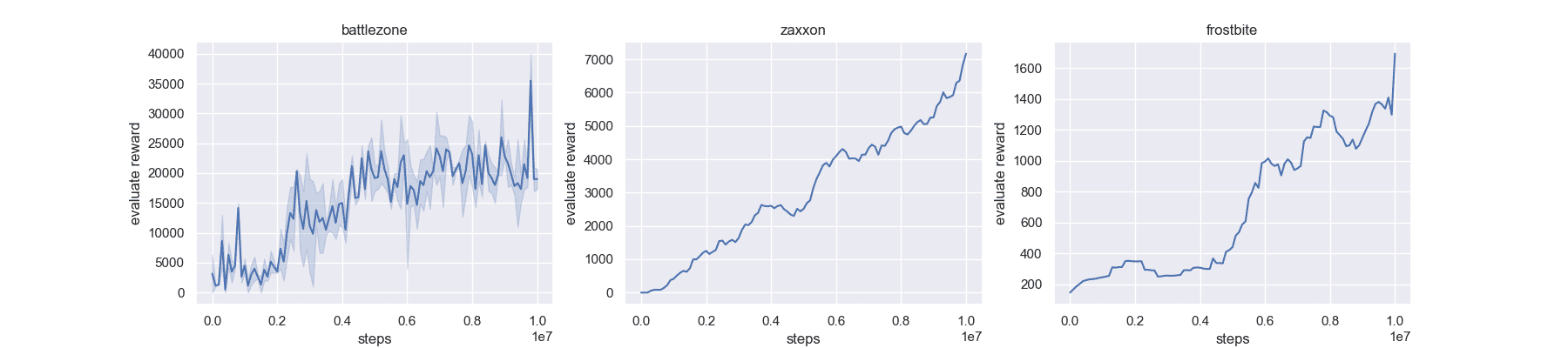
23.7 KB
examples/Prioritized_DQN/train.py
0 → 100644
examples/Prioritized_DQN/utils.py
0 → 120000