Zhoubo01 es (#127)
* add learning curve for ES * add learning curve for ES * support new APIs of the cluster * Update README.md * Update README.md * Update README.md * Update README.md * Update README.md * rename learner.py * Update README.md * Update README.md * Update README.cn.md * Update README.md * Update README.cn.md * Update README.md
Showing
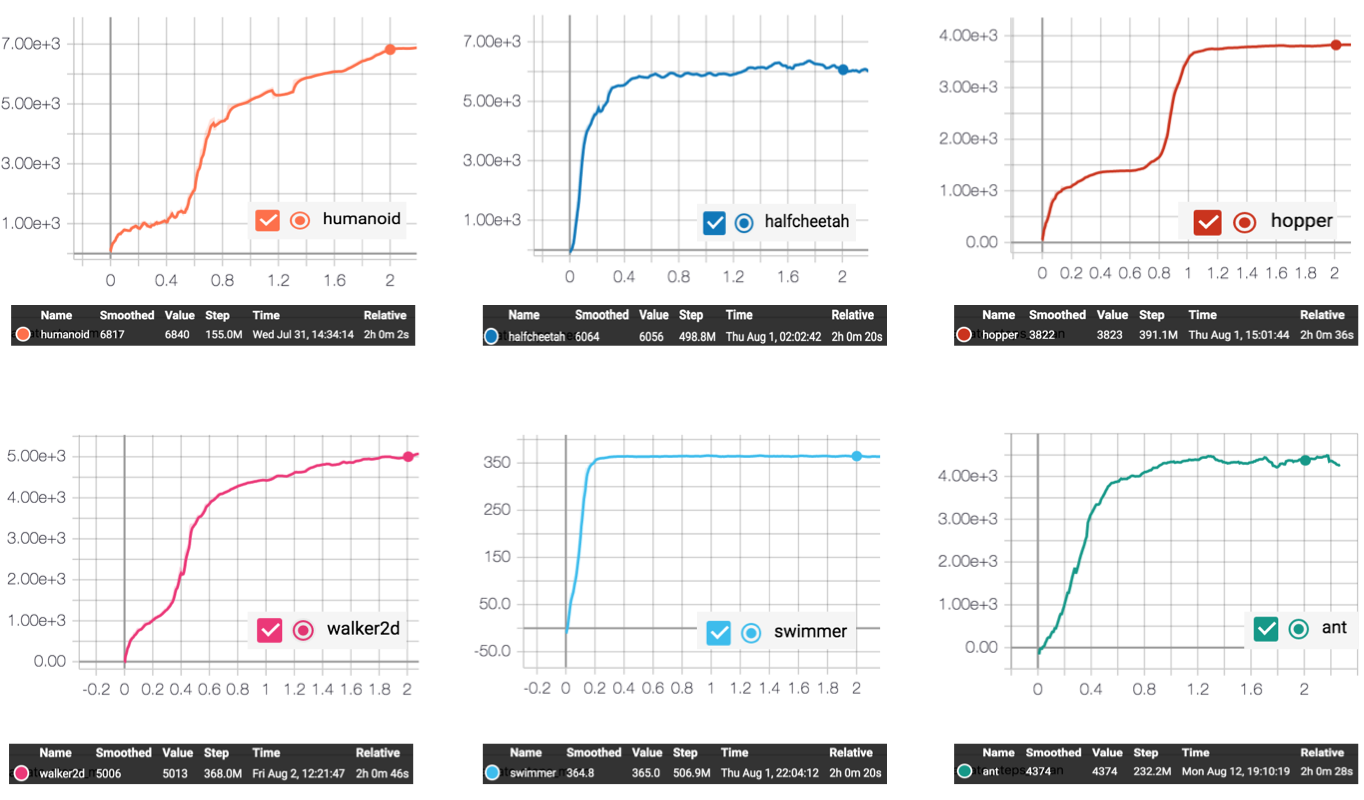
examples/ES/learning_curve.png
0 → 100644
{kind=link}
294.5 KB
examples/ES/run_actors.sh
已删除
100644 → 0