Refine documents of PARL (#43)
* remove not used files, add benchmark for DQN and DDPG, add Parameters management Readme * Update README.md * Update README.md * add parl dependence in examples, use np shuffle instead of sklean * fix codestyle * refine readme of nips example * fix bug * fix code style * Update README.md * Update README.md * Update README.md * refine document and remove outdated design doc * Update README.md * Update README.md * refine comment * release version 1.0 * gif of examples * Update README.md * update Readme
Showing
.github/Aircraft.gif
0 → 100644
{kind=link}

9.0 MB
.github/Breakout.gif
0 → 100644
{kind=link}
194.7 KB
.github/Half-Cheetah.gif
0 → 100644
{kind=link}

1.0 MB
.github/NeurlIPS2018.gif
0 → 100644
{kind=link}

2.6 MB
docs/ct.png
已删除
100644 → 0
{kind=link}
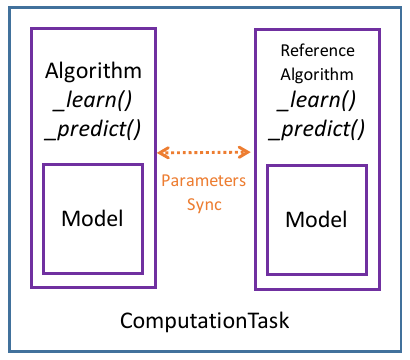
19.0 KB
docs/design_doc.md
已删除
100644 → 0
docs/framework.png
已删除
100644 → 0
{kind=link}
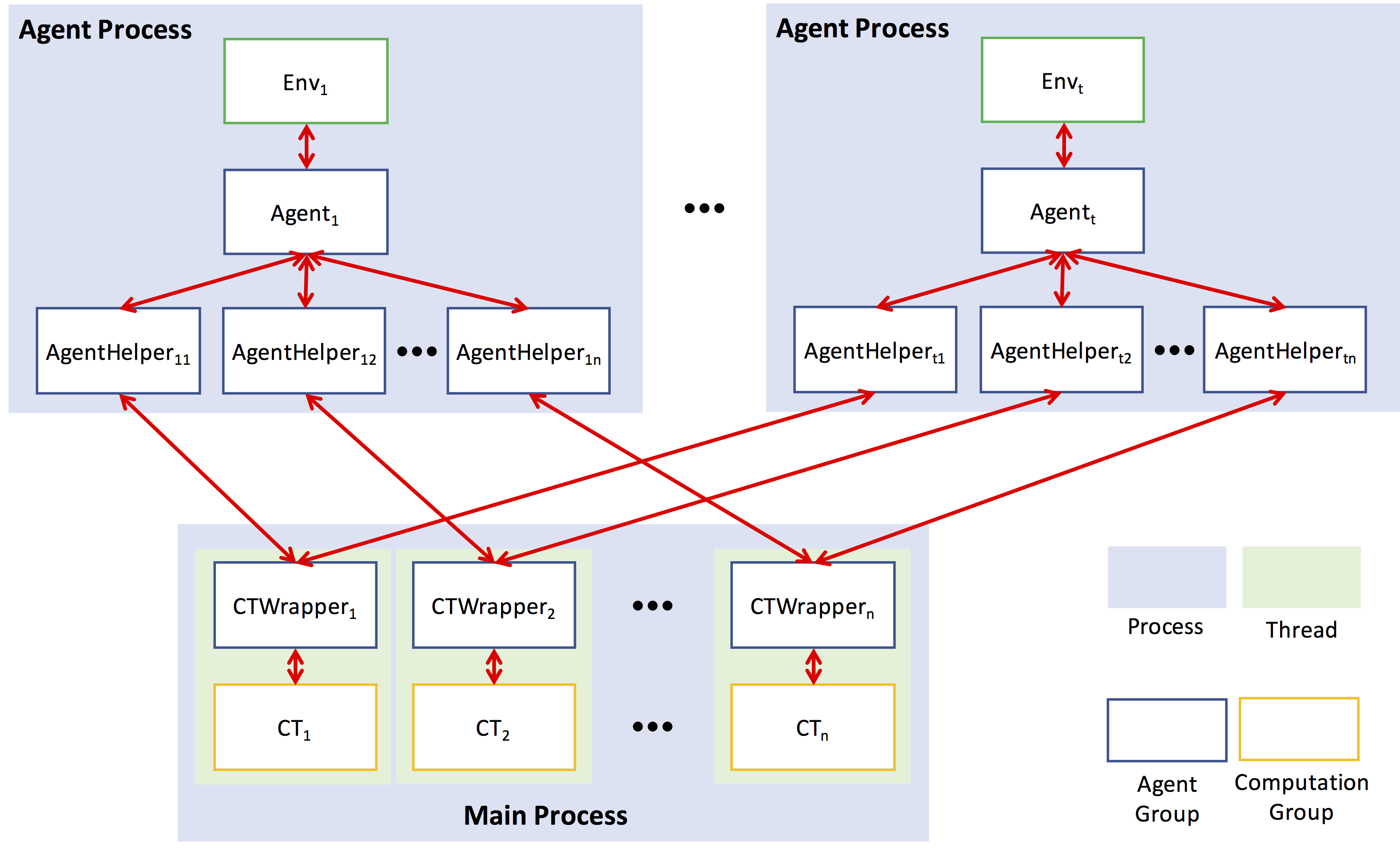
328.6 KB
docs/model.png
已删除
100644 → 0
{kind=link}

10.5 KB
docs/relation.png
已删除
100644 → 0
{kind=link}
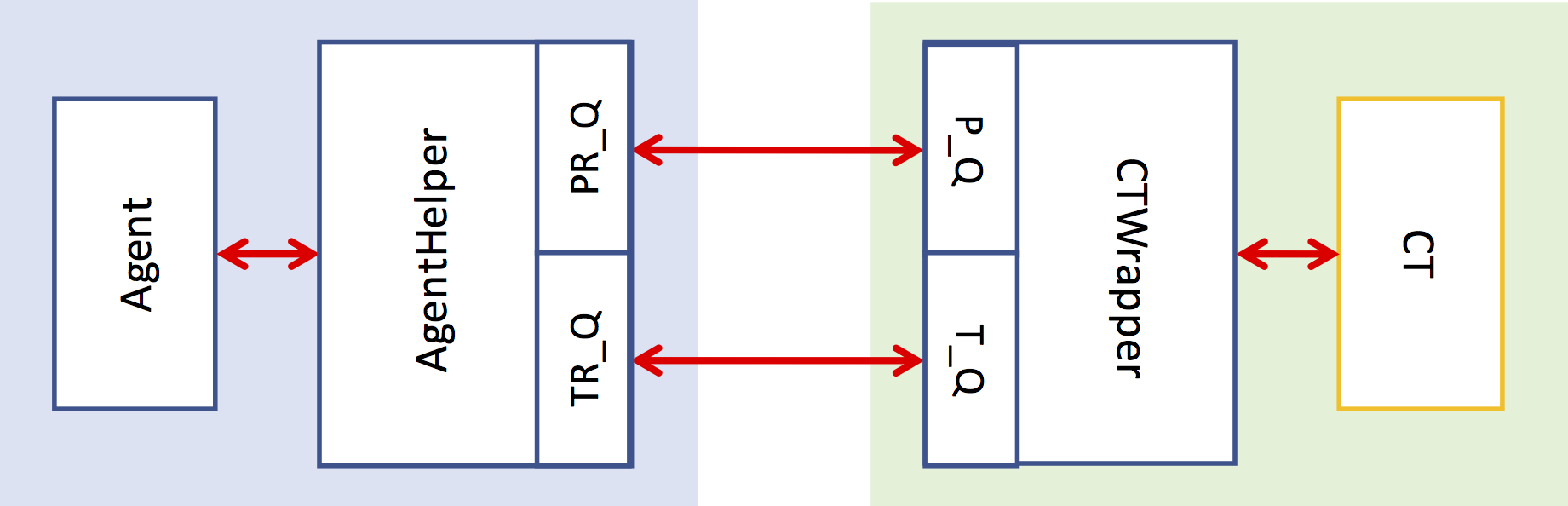
61.6 KB
docs/step.png
已删除
100644 → 0
{kind=link}
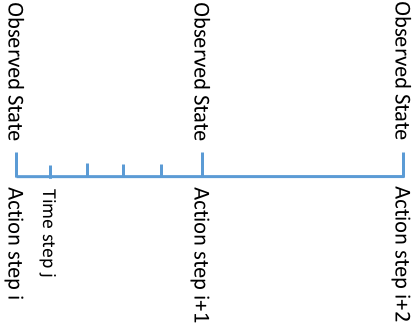
16.9 KB
{kind=link}
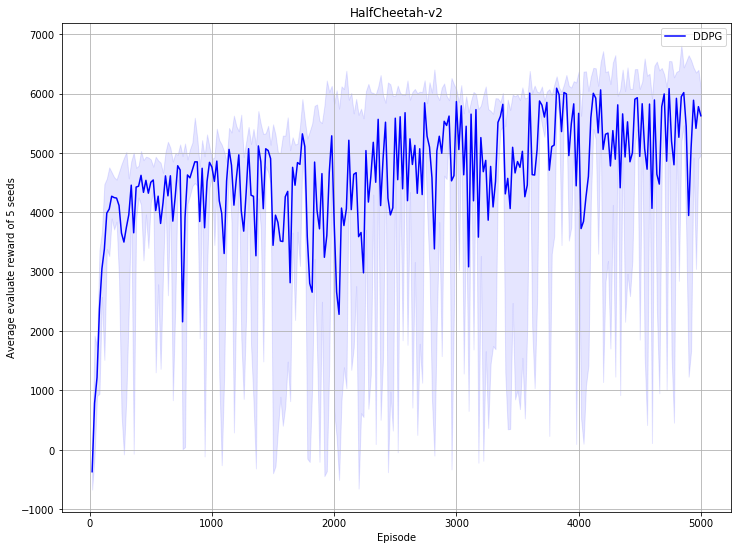
91.8 KB
{kind=link}
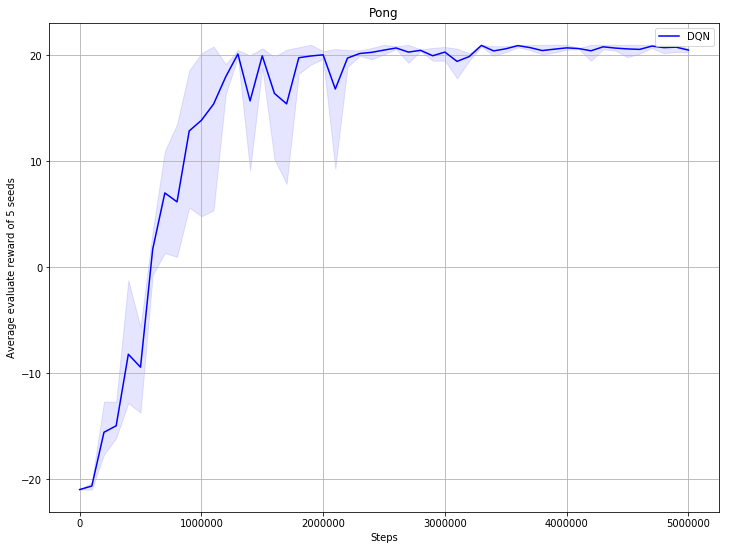
30.6 KB
parl/common/__init__.py
已删除
100644 → 0
parl/common/error_handling.py
已删除
100644 → 0
parl/common/replay_buffer.py
已删除
100644 → 0
parl/model_zoo/__init__.py
已删除
100644 → 0