Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
酥脆的小菠萝
hexbook
提交
efab319b
H
hexbook
项目概览
酥脆的小菠萝
/
hexbook
通知
5
Star
4
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
H
hexbook
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
efab319b
编写于
8月 29, 2021
作者:
S
star
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Kafka
上级
129f03c4
变更
12
隐藏空白更改
内联
并排
Showing
12 changed file
with
1640 addition
and
5 deletion
+1640
-5
docs/_posts/basic/2021-08-29-clean-code.md
docs/_posts/basic/2021-08-29-clean-code.md
+1010
-0
notes/中间件/NoSQL数据库/分布式搜索引擎-Elasticsearch.md
notes/中间件/NoSQL数据库/分布式搜索引擎-Elasticsearch.md
+5
-5
notes/中间件/img/5781124193bae6ab972bmayuan.jpg
notes/中间件/img/5781124193bae6ab972bmayuan.jpg
+0
-0
notes/中间件/img/conteplonkohit.jpg
notes/中间件/img/conteplonkohit.jpg
+0
-0
notes/中间件/img/elas_0202.png
notes/中间件/img/elas_0202.png
+0
-0
notes/中间件/img/elas_0203.png
notes/中间件/img/elas_0203.png
+0
-0
notes/中间件/img/elas_0204.png
notes/中间件/img/elas_0204.png
+0
-0
notes/中间件/img/elas_0205.png
notes/中间件/img/elas_0205.png
+0
-0
notes/中间件/img/elas_1110.png
notes/中间件/img/elas_1110.png
+0
-0
notes/中间件/img/elas_1111.png
notes/中间件/img/elas_1111.png
+0
-0
notes/中间件/img/g20nblonblogs.jpg
notes/中间件/img/g20nblonblogs.jpg
+0
-0
notes/中间件/消息队列中间件/消息队列中间件-Kafka.md
notes/中间件/消息队列中间件/消息队列中间件-Kafka.md
+625
-0
未找到文件。
docs/_posts/basic/2021-08-29-clean-code.md
0 → 100644
浏览文件 @
efab319b
---
title
:
"
代码整洁之道"
subtitle
:
"
Clean
Code"
layout
:
post
author
:
"
Hex"
header-style
:
text
hidden
:
false
tags
:
-
编程基础
---
:bulb:
***Later equals never.**
*
#### 1.有意义的命名
软件中随处可见命名,我们给变量、函数、类和包命名,下面是起一个好名字应该遵从的规则。
==名副其实==
选个好名字要花时间,但是省下来的时间比花掉的多,注意命名,而且一旦发现有更好的命名就换掉旧的,这样做,读代码的人都会更开心。
1.
指明计量单位和计量单位的名称,如:int elapsedTimeInDays、int fileAgeInDays 等。
2.
选择体现业务本意的名称,而不是字母(如:d、e),类型(如:theList、list1)等名称。
3.
利用类代替复杂的数据结构。
例如:应用中使用 int
\[
]
\[
] 数组表示坐标,如果在代码中大量使用这个二维数组,代码会变得极其繁杂,我们可以定义一个类
~~~
java
public
class
Position
{
private
int
value
;
private
int
x
;
private
int
y
;
}
~~~
4.
避免使用魔术变量(未经定义的常量),例如:
~~~
java
if
(
age
==
5
){
// do something
}
~~~
此时,我们应当将 5 这个魔术数放到文件前面并定义一个数字,如:
`private static final int MIN_AGE = 5;`
。
==避免误导==
程序员必须避免留下掩藏代码本意的错误线索,避免使用与本意相悖的词。
1.
避免使用某些专有名称作为变量名,例如:aix、sco、bat 等,虽然看起来像是不错的缩写,但是极易引起误导。
2.
不要使用 accountList 来表示一组账号,除非它真的是 List 类型,否则会引起错误的判断,此时使用 accountGroup 或 accounts 都是更好的选择。
3.
不要使用外形相似度较高的名称,例如 XYZControllerForEfficientHandlingOfStrings 和 XYZControllerForEfficientStorageOfStrings,更有甚者使用小写的字母 l 和大写的字母 O,他们看起来完全像常量「壹」和「零」。
==做有意义的区分==
在代码中,同一作用范围的两样不同的东西不能重名,如果我们只是为满足编译器或解释器的需要而修改代码,那么将会带来无尽麻烦。
1.
只是在命名后添加数字远远不够,每个不同的命名都应该能表达出不同的意义,如 a1、a2、a3、a4... 等名称纯属误导,完全没有提供正确的信息,例:
~~~
java
public
void
copyChars
(
char
[]
c1
,
char
[]
c2
)
{
for
(
i
=
0
;
i
<
c1
.
length
;
i
++)
{
c2
[
i
]
=
c1
[
i
];
}
}
~~~
此时,两个参数名 c1 和 c2 完全没有任何意义,如果将其替换为 source 和 destination,函数就会好看许多。
2.
避免使用废话来区分命名,假设有一个 Product 类,还有一个 ProductData 和 ProductInfo 类,那么它们虽然名称不同,但是都是意义含混的废话;当我们面对 getActiveAccount、getActiveAccounts 和 getActiveAccountInfo 这 3 个函数时,也无法快速的分辨到底该调用哪一个函数。
3.
避免冗余的命名,例如 variable 永远不要出现在变量名中,table 永远不要出现在数据库表名中,nameString 也不会比 name 更好。
==使用读得出来的名称==
人类擅长于记忆和使用单词,如果名称读不出来,在讨论的时候就会变得十分尴尬。
1.
不要使用字母组合命名,例如程序里面有一个 genymdhms 函数(生成年月日时分秒),这样的函数名完全无法读出来也无法一眼看出它的含义,如果换成 genTimestamp 这样的命名就会使函数读起来更像人话。
2.
不要使用不恰当的缩写,例如:DtaRcrd、Cstm、Acct 并不会比 DataRecord、Customer、Account 这些完整的单词更好更简洁。
==使用可搜索的名称==
对于单字母名称和数字常量,有一个问题就是很难再一大段代码中搜索出来。
1.
搜索 MAX_CLASSES_PER_STUDENT 很容易,但是查找数字 7 就比较麻烦了,同时字母 e、s 等也不是一个便于搜索的好名称,我们应该尽量避免使用单字母名称和数字常量。
2.
名称长短应该与其作用域大小相对应,如果变量或常量可能在代码中多处使用,则应该赋予它们便于搜索的名称。
==避免使用标记==
现代编程语言有丰富的类型系统,并且强制使用类型,所以把类型和作用域编进名称里面,只会突然增加负担。
1.
不必使用 m_ 来标记成员变量,我们要学会无视前缀或后缀,只看到名称中有意义的部分。
2.
在创建接口时,不要使用前导字母 I,比如 IShapeFactory 对于 ShapeFactory 来说,前面的 I 字母根本就是一句废话。
==类名和方法名==
1.
类名和对象名应该是名称和名词短语,例如 Customer、Account 等,此外还要避免使用 Data、Info、Manager 这样语义广泛的名称。
2.
方法名应当是动词或动词短语,如 postPayment、deletePage 等。
==一词一义==
1.
每个概念值对应一个词,假如一堆代码中的控制器有 controller、manager 和 driver,name就会让人产生困惑,我们的命名应当一以贯之。
2.
避免将同一单词用于不同目的(双关),例如:使用 add 用于向集合中添加元素,而在另外的地方用来拼接字符串,这种做法是强烈禁止的。
==使用解决方案领域名称和问题领域名称==
1.
只有程序员才会读你的代码,所以我们可以尽情的使用那些计算机科学术语,算法名,模式名,没有程序员不知道 AccoutVisitor 的含义,同样,大多数程序员也都了解 JobQueue 的含义。
2.
如果不能使用程序员熟悉的术语进行命名,那么可以考虑从所涉及的问题的领域获取命名,与软件的实际功能更为贴近。
==为代码添加语境==
很少有名称是能够自我说明的,如果不能自我说明,我们还剩最后一招,给名称添加前缀语境。
1.
当我们看见一堆单词如 state、city、street、name、houseNumber 时,我们很容易推断这是一个地址的描述,但是如果我们只看见一个孤零零的 name 变量呢,我们无法进行推断,但是我们可以添加前缀进行说明:addrName,这样我们就可以明白这个变量是更大结构的一部分。
2.
当需要使用到一堆相关联的变量时,可以使用一个类封装它们,类也是语境的一部分。
3.
不要添加无意义的语境,假如有一个名为 Gas Station Deluxe(加油站豪华版)的应用,如果给其中的每一个类都加上 GSD 前缀就不是什么好点子了;只要名称足够清楚,短名称就比长名称好。
---
#### 2.函数
在编程的早期岁月,系统由程序和子程序组成,后来到了 Fortran 和 PL/1 的年代,系统由程序、子程序和函数组成,如今只有函数保留了下来,函数是所有程序中的第一组代码。
==短小==
函数的第一条规则是短小,第二条规则还是要短小。
1. 函数尽量不要写得过长,**20** 行封顶最佳。
> :gear: 个人不倾向于这这么短的函数,频繁的函数调用不仅不会降低代码编写难度,还会提高难度。一般情况下,**50-60** 行左右封顶为最佳。
2. if、else、while 等语句,其中的代码应该只占一行,该行一般为一个函数调用语句,这样能够很好的保持函数大小。
3. 函数中的代码嵌套层级(if、while 等嵌套)不宜过多,否则不易于阅读和理解,最好是一层或两层,不可超过三层。
==只做一件事==
函数应该只做一件事,做好这件事,只做一件事。
如何判断函数只做了一件事,还是做了几件事?例:
~~~java
public void buy() {
// 1.走进商店
// 2.选好商品
// 3.掏出钱包
// 4.付钱
// 5.放回钱包
// 6.走出商店
}
~~~
在这个函数中,模拟了一个买东西的情节,其中 1、2、6 步骤都是买东西过程下的抽象层中的一件事,但是 3、4、5 却是在买东西这个动作下的更细分的步骤,很明显不属于函数名下的抽象层,此时 3、4、5 就合一被拆出一个新函数「结账」。
>
:yellow_heart:
向下原则:让每个函数后面跟着位于下一抽象层及的函数,在阅读时就能遵循抽象层级向下阅读。
=
=使用具有描述性的名称==
为
函数起一个具有描述性的名称,函数的功能越集中,就越便于起一个好名字。
不
要害怕长名称,长名称要比短而费解的短名称好。
在
同一个模块中,函数的命名方式要保持一致,使用与模块名一脉相承的短语、名词和动词给函数命名。
=
=函数参数==
最
理想的函数参数是 0,其次是 1,再次是 2,应当尽量避免 3 参数的函数(除非万不得已)。
1
. 一般来说,信息通过参数输入函数,然后通过返回值进行输出,所以尽量不要在参数中输出函数结果。
2
. 不要使用标识参数:向函数输入 boolean 值是一种不优雅的做法,相当于大声宣布本函数不只做一件事,在任何情况下我们都不要这样做;此时我们应该将这种情况拆分为 2 个函数 doXxxForXxx 和 doXxxForNonXxx。
3
. 双参数函数:
1. 两个参数最好是某个值的有序组成部分,如:`new Point(0, 0);`。
2. 使用两个同类型的参数时,应额外注意其先后顺序,如:`assertEquals(expected, actual);`中一般约定期望值在前,实际值在后。
3. 尽量的转化双参数函数为单参数函数,可以使用诸如添加成员变量、新建一个类等方法。
4
. 三参数函数:如果一个函数看起来需要 2 个、3 个及 3 个以上的参数,说明一些参数应该封装成类了,例:
~~~java
Circle makeCircle(double x, double y, double radius);
Circle makeCircle(Point center, double radius);
~~~
5
. 可变参数:在 Java 中,可以使用 ... 向函数传入可变长度的参数。
6
. 函数和参数应当形成一种非常良好的动词/名词的对应关系,例如: `writeField(name);`。
=
=分割指令和询问==
1
. 函数要么做什么事,要么回答什么事,两者不可得兼,例:
~~~java
boolean isSuccess = setAttribute("username", "unclebob");
---------------------------------------------------------
if(attributeExists("username")) {
setAttribute("username", "unclebob");
}
~~~
此两种代码明显后者更优。
2
. 使用异常替代返回错误码,将询问以异常的形式抛出,能够很好的分割指令和询问。
1. 将 try/catch 代码块单独抽离为一个函数,使之从主代码块中分离出来,代码就会变得更简洁。
2. 错误处理就是一件事,处理错误的函数不应该做其他的事,如果在抛出错误的时候需要做另外的一件事,那么应该好好考虑此处是否应该抛出错误。
3. 尽量使用异常代替错误码,返回错误码一般是一个枚举类,其他许多类都要依赖并使用它,使得在修改这个枚举类时造成了很大的负面压力,所以,尽量使用异常派生类。
-
--
#### 3.注释
注释的恰当用法是弥补我们在用代码表达意图时遭遇的失败。
注释会撒谎;我们的代码在变动,在演化,但是注释不总是随之变动,只有代码才能忠实的告诉你它在做的事情。
好助手是必需的,是有利的;尽管我们需要注释,但是我们也应该多花心思尽量减少注释量。
==好注释==
1.
法律信息:有时,公司代码规范每个源文件开头放置与法律相关的注释,如版权与著作声明:
~~~
java
// Copyright (c) 2003,2004,2005 by Object Mentor,Inc. All rights reserved.
~~~
注意:此类注释不应该是合同或法典,只要有可能,就应该指向一份标准许可或外部文档。
2.
对意图的解释:对某段代码的目的作出解释。
3.
阐释:对某些晦涩难懂的方法的返回值,变量值的意义翻译为可读形式。
4.
警示:对调用代码的程序员作出相应的警示,如:
~~~
java
// SimpleDateFormat is not thread safe, so we need to create each instance independently.
~~~
5.
TODO 注释:TODO 是程序员认为该做,但是由于某个原因目前还没有完成的工作,同时,我们也要定期查看,删除不必要的 TODO 注释。
6.
放大:可以用来放大在某处看起来不合理的代码的重要性。
7.
公共 API 的 Javadoc。
==坏注释==
1.
喃喃自语:如果只是因为觉得应该写注释或者是过程需要就添加注释,那就是无谓之举。
2.
误导性注释:当代码的行为与注释描述不符时,那就是误导性注释。
3.
循规式注释:不是每个函数都需要添加 Javadoc 注释,也不是每个变量都需要注释,否则就会让代码变得散乱。
4.
日志型注释:有人会在每次编辑代码时在模块开始处添加一段注释,此种注释维护困难,大可不必。
5.
废话注释:在某些简单的函数或变量上添加自述一般的注释纯属废话注释。
6.
位置标记,如:
~~~
java
// Actions ---------------------------------
~~~
7.
括号后面的注释:有时候我们会在括号后面放置注释用来标记括号的结束,但是此时我们更应该做的是缩小括号。
8.
署名信息,如:
`//Added By David`
。
9.
注释掉的代码:现在我们有良好的源代码控制系统(Git、SVN)帮助我们记住写过的代码,对于不需要的代码块,直接删除即可。
10.
非本地信息:假如你一定要写注释,请确保它描述了离它最近的代码。
11.
过多的注释:不要在注释中添加不必要的细节信息和其他话题。
12.
不明显的联系:如果一定要写注释,那么请确保注释描述和代码之间保持显而易见的联系。
13.
非公共代码的 Javadoc:如果代码并不打算用作公共用途,那么请尽量减少 Javadoc 注释。
---
#### 4.格式
垂直尺寸:通过对各个开源系统代码的总结,我们用大多数为 **200**,最长不超过 500 行的单个文件可以构造出较为出色的系统。
垂直格式:
1. 源文件要像报纸一样,名称应当简单且一目了然,源文件顶部应该给出高层次的概念和算法,细节向下渐次展开。
2. 在垂直方向上,每组代码使用空白行区隔开来。
3. 在垂直方向上,紧密相关的代码应该互相靠近(如类的各个属性值)。
4. 垂直距离:
1. 关系密切的概念应当相互靠近,除非有很好的理由,否则不要把关系密切的概念放置在不同的文件中。
2. 变量声明:变量声明要尽可能地靠近其使用位置。
3. 实体变量:实体变量应该在类的顶部进行声明。
4. 相关函数:若某个函数调用了另一个,就应该把它们放在一起,而且调用者应该尽可能地放在被调用者的上面。
横向尺寸:我们应当尽力保持代码短小,,一般来说尽量保持无需左右拖动滚动条就可以看到最右边代码的原则(120 字符左右为最佳)。
横向格式:
1. 水平方向上的区隔:
1. 赋值符号两边加空格以区隔。
2. 函数体 `{}` 与函数声明和参数间加一个空格以区隔。
3. 使用空格强调运算符,如:`a = b*b - 4*a*c`,乘法之间不加空格,因为它们的优先级较高,减法间使用空格进行区分。
---
#### 5.对象和数据结构
对象和数据结构:
1.
对象:对象把数据隐藏于抽象之后,暴露操作数据的函数。
~~~
java
public
class
Square
implements
Shape
{
private
Point
topLeft
;
private
double
side
;
public
double
area
()
{
return
side
*
side
;
}
}
--------------------------------------------
public
class
Circle
implements
Shape
{
public
static
final
double
PI
=
3.1415926
;
private
Point
center
;
private
double
radius
;
public
double
area
()
{
return
PI
*
radius
*
radius
;
}
}
~~~
2.
数据结构:数据结构暴露其数据,不提供有意义的函数。
~~~
java
public
class
Square
{
public
Point
topLeft
;
public
double
side
;
}
--------------------------------------------
public
class
Circle
{
public
Point
center
;
public
double
radius
;
}
--------------------------------------------
public
class
Geometry
{
public
static
final
double
PI
=
3.1415926
;
public
double
area
(
Object
shape
)
throws
NoSuchShapeException
{
if
(
shape
instanceof
Square
)
{
Square
s
=
(
Square
)
shape
;
return
s
.
side
*
s
.
side
;
}
else
if
(
shape
instanceof
Circle
)
{
Circle
c
=
(
Circle
)
shape
;
return
PI
*
c
.
radius
*
c
.
radius
;
}
else
{
throw
new
NoSuchShapeException
();
}
}
}
~~~
我们将代码 [1] 称为面向对象的代码,而代码 [2] 则为过程式代码。
如果我们需要给 [2] 中的 Geometry 添加一个 primeter() 函数,这些形状类根本不会受到影响,另一方面,如果我们添加一个新形状,那么需要修改 Geometry 中所有的函数来处理它。
代码 [1] 与代码 [2] 恰恰相反,如果需要添加一个新形状,原来的形状类不会受到任何影响;但如果接口需要添加一个新函数,所有形状类都需要做出相应修改。
所以:==过程式代码(使用数据结构的代码)便于在不改动既有数据结构的情况下添加新函数;面向对象代码便于在不改动既有函数的情况下添加新类==。
**得墨忒耳定律**
-- 对象 O 的 M 方法,可以访问/调用如下的:
1.
对象 O 本身。
2.
M 方法的传入参数。
3.
M 方法中创建或实例化的任意对象。
4.
对象 O 直接的组件对象。
5.
在 M 范围内,可被 O 访问的全局变量。
方法不应该调用由任何函数返回的对象的方法(只跟朋友谈话,不跟陌生人谈话)。例:
~~~
java
final
String
outputDir
=
ctxt
.
getOptions
().
getScratchDir
().
getAbsolutePath
();
~~~
此段代码是否违背了得墨忒耳定律?
1.
如果 ctxt、Options 和 ScratchDir 是对象,则它们的内部结构应当被隐藏,显然违反了得墨忒耳定律。
2.
如果 ctxt、Options 和 ScratchDir 只是单纯的数据结构,没有任何行为,此段代码可以看作:
~~~
java
final
String
outputDir
=
ctxt
.
options
.
scratchDir
.
absolutePath
;
~~~
只是数据结构在暴露其内部数据,不算做调用 ctxt 的任何行为方法。
> :yin_yang: 有时候我们会使用混杂的结构,即一般是对象,一半是数据结构;此种结构增加了添加新函数的难度,也增加了添加数据结构的难度,两头不讨好;同时对于各种规则定律的判断产生误导,应当避免创造这种结构。
那么,如果 ctxt 是对象,此段代码应该如何修改呢?
既然 ctxt 是对象,就应该要求它做点什么,所以,这件事不妨交给 ctxt 对象本身来做:
~~~
java
final
String
outputDir
=
ctxt
.
createAbsolutePathOfScratchDirOption
();
~~~
此时,既没有暴露 ctxt 的内部细节,也没有违反得墨忒耳定律。
> 在任何系统中,有时我们希望能够灵活地添加数据类型,所以更喜欢在这部分使用对象。另外的一些时候,我们希望能够灵活地添加新行为,这时候我们更希望使用数据类型和过程代码。
>
> 优秀的程序员能够不带成见地了解这两种情形,并依据手中的工作性质选择一种合适的手段。
---
#### 6.错误处理
>
:baby_chick:
错误处理是编程时必须要做的事情之一,错误处理很重要,但如果它搞坏了代码逻辑,那就是错误的做法。
J
ava 代码中的错误处理:
1
. 使用异常而非返回码。
2
. try-catch-finally 语句的使用:
1. 在明明白白地知道自己的代码会发生错误时,再使用 try-catch 语句就不太合适了。例如:如果传递给函数的参数是字符串而非数值,就会造成函数出错,那么就应该先检查参数的类型,然后再决定如何去做。
2. 在 catch 块中,可以对错误进行处理,也可以在处理过后在抛出一个缩小异常类型范围的新异常。
3. 尝试编写强行抛出异常的代码,再想处理器中添加行为,结果就是你需要先构造 try 代码块的事务范围,可以帮阻尼维护好该范围的事务特征。
3
. 使用未检异常:如果你在代码中抛出已检异常时,当 try-catch 语句的调用层级很高时,意味着你需要你在调用的每个方法签名上声明该异常,此点违背了 [开放/闭合原则]。
如果我们在编写一些关键的代码库,已检异常有时也会有用,但是对于一般的应用开发,未检异常更加好用。
4
. 给出异常发生的环境说明:在抛出异常时应创建充分的错误信息,并和异常一起传递出去。
5
. 在引用第三方代码时,我们可以将第三方的异常打包,抛出自己的异常进行解释。
6
. 定义常规流程:如果某一个业务因为某种特例抛出错误而中断了业务流程,我们可以考虑创建或配置一个特例对象来处理这种情况。
7
. 不要返回 null 值和传递 null 值。
-
--
#### 7.类
类的组织:遵循 Java 的约定,类应该从一组变量列表开始;
变量的出现顺序为:公共静态常量 --> 私有静态变量 --> 私有实体变量。
类应该短小:对于函数,我们通过计算代码行数衡量其大小;对于类,我们采用权责(responsibility)进行衡量。
1.
类的名称应当描述其权责,如果无法为某个类命以精确的名称,那么大概这个类就太长了。
2.
单一权责原则(
**SRP**
):类或模块应该有且只有一条加以修改的理由。
> :desert_island: 系统应该由许多短小的类而不是少量巨大的类组成,每个小类封装一个权责,只有一个修改的原因,并与少数其他类一起协同达成期望的系统行为。
3.
内聚:类应该只有少数实体变量,类中的每个方法都应该操作一个或多个这种变量。一般来说,方法操作的变量越多,就越粘聚在类上。
> :balloon: 保持函数和参数列表短小的策略,有时会导致一组子集方法所用的实体变量数量增加,出现这种情况时,往往意味着至少有一个类要从大类中挣扎出来,我们应当将这些变量和方法拆分到两个或多个类中,使新的类更加内聚。
4.
面向修改关闭:需求会改变,所以代码也会改变;具体类包含实现细节,而抽象类只呈现概念,依赖具体细节的实现类,当细节改变时,就会有风险。我们可以借助接口和抽象类来隔离这些细节所带来的影响。
> :aerial_tramway: 通过接口和抽象类,也对系统的部件进行了解耦,也就遵循了另一条类设计原则,及依赖倒置(Dependency Inversion Principle)原则。
---
#### 8.系统
>
:rabbit2:
软件系统应将起始过程和起始过程之后的运行时逻辑分开。在起始过程中创建应用对象,也会存在着互相缠结的依赖关系。
将
系统的构造和使用分开的方法:
1
. 分解 main:将全部的构造过程搬迁到 main 方法或者被称之为 main 的模块之内,设计系统的其余部分时,假设所有的对象都已经正确构造和设置。
2
. 工厂:使用工厂创建对象,应用程序能够决定何时创建对象,单创建对象的过程隔离与工厂之内。
3
. 依赖注入:将第二权责(构造)从对象当中拿出来,转移到另一个专注于此的对象中,从而遵循了单一权责原则。
> :zzz: 真正的依赖注入还需要更进一步,类并不直接解决依赖问题,而是保持完全被动,它提供用于注入依赖的赋值器或构造器,由容器在恰当的时候创建需要的对象。
扩
容:与物理系统相比,软件系统比较独特,软件系统的架构可以递增式的增长,只要我们持续将关注面恰当的切分。
横
贯型关注面:在代码实践中,我们不得不将同种代码铺展到许多对象中,我们用横贯型关注面来形容这种情况。
面
向切面编程(AOP):将横贯型关注面模块化的手段,目前主要包含以下 3 种机制
1
. Java 代理:Java 代理适用于简单情况,将单独的对象或类中包装方法调用。
2
. 纯 Java AOP 框架:如 Spring AOP 和 JBoss AOP,通过在 xml 中定义所有的实体 bean,将应用程序的构造和使用进行分离。
3
. AspectJ:AspectJ 提供了一套用以切分关注面的强有力的工具,Spring 中也对 AspectJ 进行了组合。
-
--
#### 9.迭进
Kent Beck 提出了关于简单设计的 4 条规则:
1.
运行所有测试
2.
不可重复
3.
表达程序员的意图
4.
尽可能的减少类和方法的数量
以上规则逐条迭进,只要遵循以上规则,设计就能变得简单。
运行所有测试:设计必须制造出如预期一般工作的系统,这是首要因素。
规则 2-4(重构):要保持代码的整洁,方法就是递增式的重构代码。
1.
消除重复:重复有多种表现,雷同的代码是重复的代码,类似的代码也可以调整得更相似,这样能更容易的进行重构。
> 还有一些其他方式的重复,例如某个类存在两个方法:
>
> ~~~java
> int size();
> boolean isEmpty();
> ~~~
>
> 这两个方法可以分别实现,但是我们也可以通过在 isEmpty 方法中使用 size 来消除重复:
>
> ~~~java
> boolean isEmpty() {
> return 0 == size();
> }
> ~~~
==模板方法模式是一种消除高层及重复的通用技巧。==
---
#### 10.并发编程
并发是一种解耦策略,它帮助我们将做什么和何时做分解开,并明显的改进程序的吞吐量和结构。
为了正确的并发,有一系列的防御并发代码的原则和技巧:
1. 单一权责原则:并发代码有自己的开发,修改和调优的生命周期。并发代码有自己要应对的挑战,而且往往更为困难。
建议:分离并发相关代码和其他代码。
2. 限制数据作用域:谨记数据封装,严格限制对可能被共享的数据的访问。
3. 使用数据副本:通过复制数据副本来减少减少可能因为共享数据而导致错误的可能性。
4. 线程应尽可能的独立:尝试将数据分解为可独立线程操作的独立子集。
>
:japanese_goblin:
Java
并发库:java.util.concurrent,java.util.concurrent.atomic,java.util.concurrent.locks
多
线程代码应当注意的原则:
1
. 保持同步区域微小:锁是昂贵的,它带来了延迟和额外开销,所以我们应尽可能的减小同步区域。
2
. 编写正确的关闭代码:尽早地考虑关闭问题,尽早令其正常工作。
3
. 测试线程代码:编写有潜力暴露问题的测试,在不同的编程配置,系统配置和负载条件下反复运行测试。
1. 不要讲系统错误归结于偶发事件。
2. 先使非线程代码可以正常工作,不要同时追踪非线程缺陷和线程缺陷。
3. 编写可拔插的线程代码,这样就能在不同的配置环境下运行。
4. 运行多于处理器核心数量的线程,促使任务交换的发生,更快的暴露线程问题。
5. 在不同的平台上运行测试。
6. 装置试错代码:例如向代码中加入 wait(); sleep(); yield() 等的调用来进行测试。
-
--
#### 11.味道与启发
> :bookmark: 注释
1.
不恰当的信息
让注释不应该保存本该出现在源代码控制系统、问题追踪系统或任何其他记录系统中的相关信息,例如版本历史、作者、最后修改时间等。
<u>
注释只应该描述有关代码和设计的技术性信息
</u>
。
2.
废弃的注释
过时、无关或不正确的注释就是废弃的注释。如果发现废弃的注释,最好尽快的更新或删除。
废弃的注释会远离它们曾经描述的代码,变成与代码无关的误导阅读者的浮岛。
3.
冗余注释
如果注释描述的东西是代码已经充分自我描述了的东西,那么这个注释就是冗余注释。如:
~~~
java
i
++
;
// increment 1
~~~
另外一个是冗余式的函数签名 javadoc:
~~~
java
/**
* @param SellRequest
* @return SellResponse
* @throws ManagedComponentException
*/
public
SellResponse
beginSellItem
(
SellRequest
request
)
throws
ManagedComponentException
;
~~~
此函数签名完全多余,
<u>
注释应该谈及代码自身没有提到的东西
</u>
。
4.
糟糕的注释
如果需要编写注释,那么就花时间保证写出最好的注释,字斟句酌,使用正确的语法和拼写、不闲扯、不画蛇添足、保持简洁。
5.
注释掉的代码
没人会去删除别人注释掉的代码,因为大家都假设别人需要它或者是有进一步的计划,这样的代码随着时间推移就这样腐烂掉,它污染了所属的模块,分散了阅读者的注意力,注释掉的代码纯属厌物。
如果有注释掉的代码,就删除它,不要担心,源代码控制系统还记得它,如果有人真的需要,可以还原到较旧的版本。
> :triangular_flag_on_post: 函数
1.
过多的参数
<u>
函数的参数个数应尽可能的少
</u>
。没参数最好,一个次之,两个、三个再次之。三个以上的参数非常值得质疑,应当坚决避免。
2.
输出参数
不要将函数结果输出在参数中,读者希望参数用于输入而非输出。如果函数非要修改什么东西,就修改函数所属对象的状态好了。
3.
标识参数 boolean
布尔值参数大声地宣告函数不止做一件事,它们令人疑惑,应当坚决避免。
4.
死函数
<u>
永不被调用的函数应当被丢弃
</u>
,不要害怕删除死函数,源代码控制系统还记得它。
> :gear: 一般性问题
1.
一个源文件中存在多种语言
现代编程语言允许单个源文件中存在多种不同语言。但是我们
<u>
应该尽力去缩小源文件中额外语言的数量和范围
</u>
,避免时源文件变得驳杂不精、令人迷惑。
2.
不正确的边界行为
没有什么可以替代谨小慎微。每种边界条件、每种极端情形、每个异常都代表了可能搞乱算法的东西。
<u>
不要依赖直觉、追索每种边界条件并进行测试
</u>
。
3.
忽视安全
忽视代码安全非常危险。关闭某些编译器警告(或者全部警告)有助于构建成功,但是却有可能陷入无穷无尽的调试当中。
关闭编译器警告、告诉自己过后再处理等行为,和假装刷信用卡不用还钱一样存在安全隐患。
4.
重复
每次看到了重复代码,都代表你遗漏了抽象,重复的代码可能成为子程序或者干脆是一个类。重复存在着多种形态:
-
最明显的形态就是明显一样的代码,就像鼠标复制粘贴出来的一样。
-
较隐蔽的形态是不同模块中重复出现的检测同一组条件的 switch/case 和 if/else 语句,它们可以使用多态来替换。
-
最隐蔽的形态是采用类似的算法(或执行流程)但具体代码不同的代码,我们可以使用
<u>
模板方法模式
</u>
和
<u>
策略模式
</u>
来修正。
5.
在错误抽象层级上的代码
有时,我们会创造抽象类来容纳较高层级概念,创建派生类来容纳较低层级的概念,这样做的时候,需要确保分离完整。
<u>
只与细节实现有关的常量、变量或函数不应该在基类当中出现
</u>
。例如:
~~~
java
public
interface
Stack
{
Object
pop
()
throws
EmptyException
;
void
push
(
Object
o
)
throws
FullException
;
double
percentFull
();
class
EmptyException
exends
Exception
{}
class
FullException
exends
Exception
{}
}
~~~
此时函数 percentFull 就位于了错误的抽象层级,尽管存在着许多 percentFull 的有意义的实现,但是也有其他不能知道自己有多满的 Stack 的存在,所以应该讲 percentFull 放置在类似于 BoundedStack 之类的派生接口当中。
6.
基类依赖派生类
<u>
较高层级基类概念不可以依赖较低层级的派生类概念,基类应该对派生类一无所知
</u>
。
7.
信息过多
设计良好的模块有着非常小的接口,它不会提供许多需要依赖的函数,耦合度也极低。
我们需要限制类或模块当中的暴露的接口数量。类中的方法越少越好,类拥有的实体变量越少越好,函数知道的变量越少越好。
不要创建拥有大量方法和大量实体变量的类,不要为子类创建大量受保护(protected)变量和函数,尽力保持接口紧凑。
8.
死代码
死代码就是不执行的代码,如果你找到了死代码,就毫不犹豫地将它从系统中删除掉。
9.
垂直分割
函数和变量应该在靠近被使用的地方上定义。
10.
前后不一致
<u>小心选择约定,并且持续遵循</u>。例如:如果在前面使用了 XxxResp 来定义响应对象,在之后就不要使用其他后缀进行表示。
11.
人为耦合
<u>不互相依赖的东西不应该耦合</u>。例如将普通的 Enum 随意的定义在某个特殊类中,或者在某个特殊类中声明一般目的的 static 函数。
我们应该多花时间研究在什么地方声明函数、常量和变量,不要为了方便随手放置,然后置之不理。
12.
选择算子参数
没有什么比在函数末尾遇到一个 false 参数更可憎的事了,调用人员必须记住 true 代表什么,false 代表什么。这种参数只是一种避免把大函数切分为小函数的偷懒做法,例如下面的代码:
~~~java
public int calculateWeeklyPar(boolean overTime) {
int straightPay = getStraightPay();
int overtimePay = (int) Math.round(overTime ? 1.5 : 1.0 * rate);
return straightPay + overtimePay;
}
~~~
如果加班工资以 1.5 倍计算时使用 true 调用函数,以 1.0 倍计算时使用 false 调用函数,每次调用都必须记住 overTime 代表什么,此种方式太糟糕了,我们完全可以将这两种情形拆分为 2 个函数,以函数名来区分它们。
注意:算子参数不一定是 boolean 类型,也有可能是美剧元素,整数或其他选择函数行为的参数。
通常来说,<u>使用多个函数往往优于向单个函数传递某些代码来选择函数的行为</u>
13.
不恰当的静态方法
Math.max(double a, double b) 是一个良好的静态方法,这个 max 所用到的数据完全来自于两个参数,它并不在单个的实体上操作。但并不是任何时候都适合写静态方法:
~~~java
HourlyPayCalculator.calculatePay(employee, overtimeRate);
~~~
函数 calculatePay 极有可能有多种算法,这种情况下函数就不应该是静态的。
<u>通常情况下,我们应该倾向于使用静态方法,如果有疑问就使用非静态方法,但是此时就要确保没机会打算让它有多态的行为</u>。
14.
函数名称应表达其行为
看看这个代码:
~~~java
Date newDate = date.add(5);
~~~
到底是在原来的基础上添加 5 天?5小时?还是 5 分钟,仅仅从调用中看不出函数的行为。
<u>如果必须要看函数的实现或者文档才能知道它是做什么的,那么就应该换一个函数名</u>。
15.
把逻辑依赖改为物理依赖
如果某个模块依赖于另一个模块,依赖就应该是物理上的而非逻辑上的,换言之,依赖者不应该对被依赖着有所假定,它应该明确地向后者询问全部信息。例:
~~~java
public class HourlyReporter {
private HourlyReporterFormatter formatter;
private List<LineItem> page;
private final int PAGE_SIZE = 50;
}
~~~
HourlyReporter 依赖 HourlyReporterFormatter 模块,但是它维护了原本应该存在于 Formatter 中的 PAGE_SIZE 变量,这就是逻辑依赖。
16.
用多态替代 if/else 或 switch/case
<u>如果 if/else 或 switch/case 对同一个选择类型在多处(大于等于 2 处)进行了判断,那么就应该使用多态进行代替</u>。
17.
使用命名的常量代替魔术数
如数字 86400 应当藏在 SECONDS_PER_DAY 后面,如果每页打印 55 行,那么使用常量 LINES_PER_PAGE 在代码中进行使用。
<u>魔术数不仅指数字,它泛指代码中任何不能自我描述的符号</u>。
18.
封装条件
如果没有充分阅读上下文,布尔逻辑值就难以理解,通常来说:
~~~java
if(shouldBeDeleted(timer))
~~~
优于代码:
~~~java
if(timer.hasExpired() && !timer.isRecurrent())
~~~
19.
避免否定条件
通常情况下,否定式条件比肯定式条件更难理解:
~~~java
if(buffer.shouldCompact())
~~~
要好于
~~~java
if(!buffer.shouldNotCompact())
~~~
20.
函数只应该做一件事
函数只应该做函数名下同一抽象层的步骤。每个函数后面跟着位于下一抽象层及的函数,在阅读时就能遵循抽象层级向下阅读。
21.
掩蔽时序耦合
编码中常常有必要使用时序耦合,即代码必须遵循一定的顺序。看下面的代码:
~~~java
public class MoogDiver {
Gradient gradient;
List<Spline> splines;
public void dive(String reason) {
saturateGradient();
reticulateSplines();
diveForMoog(reason);
}
...
}
~~~
这 3 个函数的次序很重要,捕鱼前先织网,织网前先编绳。但是代码并没有强调这种时序耦合,调用者可以不按顺序调用,所以更好的方式是:
~~~java
public class MoogDiver {
Gradient gradient;
List<Spline> splines;
public void dive(String reason) {
Gradient gradient = saturateGradient();
List<Spline> splines = reticulateSplines(gradient);
diveForMoog(splines, reason);
}
...
}
~~~
这样就通过创建顺序队列强调了时序耦合,每一个函数都产生下一个函数所需要的结果。
22.
封装边界条件
边界条件难以追踪,我们应把处理边界条件的代码集中到一处,不要散落于代码中。看一个简单例子:
~~~java
if(level + 1 < tags.length) {
parts = new Parse(body, tags, level + 1, offset + endTag);
body = null;
}
~~~
注意:<u>level + 1 出现了两次,这是一个应该封装到 nextNevel 之类的变量中的边界条件</u>。
23.
在较高层级放置可配置数据
如果你有一个已知的在较高抽象层级的默认常量或配置值,不要将它埋藏在较低层级的函数中,应该将它放置在类的顶部等显眼位置。
24.
避免传递浏览
通常我们不想让某个模块了解太多协作者的信息,假设 A 与 B 协作,B 与 C 协作,我们不想让使用 A 的模块了解 C 的信息。例如:
~~~java
a.getB().getC().doSomething();
~~~
如果多个模块使用类似的架构,那么就难以修改设计和架构,此时我们应该让直接协作者提供所需的全部服务:
~~~java
a.doSomething();
~~~
> :tea: Java
1.
不要继承常量
不要直接使用父类中定义的静态常量,这样让人摸不着头脑,我们应该使用静态导入:
~~~
java
import
static
payrollConstants
.*;
~~~
2.
常量和枚举
使用 Enum 代替老式代码中的
`public static final int`
,Enum 可以拥有方法和字段,比 int 提供了更多表达力和灵活性。
> :national_park: 命名
1.
采用描述性名称
<u>
不要太快起名,确认名字具有描述性。事物的意义经常随着代码的演化而变化,所以要经常性的重新估量名称是否恰当
</u>
。
2.
尽可能使用标准命名法
假如你采用工厂模式,那么在命名时用上 Factory 字样,在 Java 中,将对象转为 String 的函数通常命名为 toString,最好是遵循这些约定,而不是自己创造命名法。
3.
为较大作用范围选用较长名称
例如使用 i、j 在循环中作为临时变量,如果使用了较长变量,反而是徒增混乱,而在较长的距离上,使用短名称的变量会使其丧失含义。
<u>
名称作用范围越大,名称就该越长,越准确
</u>
。
4.
避免编码
<u>
代码中不应该有 m_ 或 f_ 之类的前缀
</u>
,我们使用其他名称也能够提供这些信息。
5.
名称应该说明副作用
名称应该说明函数、变量或类的一切信息,不要用名称掩蔽副作用。例如:
~~~
java
public
ObjectOutputStream
getOos
()
throws
Exception
{
if
(
oos
==
null
)
{
oos
=
new
ObjectOutputStream
(
socket
.
getOutputStream
());
}
return
oos
;
}
~~~
该函数不仅仅是获取一个 oos,如果 oos 不存在还会创建一个,所以说更好的函数名称大概是 getOrCreateOos。
\ No newline at end of file
notes/中间件/NoSQL数据库/分布式搜索引擎-Elasticsearch.md
浏览文件 @
efab319b
...
...
@@ -824,7 +824,7 @@ Elasticsearch 集群分配:
1
. 单节点集群:当 Elasticsearch 服务只有一个节点时,这一个节点也称为一个集群(单节点集群),在此时创建一个 3 个分片 1 个拷贝的索引时,其分片的分布情况如下:


此时 3 个分片都为主分片(副本分片不会被分配),集群的健康状态为`yellow`。
...
...
@@ -862,7 +862,7 @@ Elasticsearch 集群分配:
第 2 个节点加入集群后,Elasticsearch 将会对分片重新分配,此时 3 个主分片和 3 个复制分片均已被分配,其分布情况如下:


主分片和复制分片位于不同的节点当中,集群状态为`green`。当集群损失任意一个节点时,数据不会丢失。
...
...
@@ -870,7 +870,7 @@ Elasticsearch 集群分配:
此时的分片分布如下:


此时丢失一个节点不会丢失数据,丢失 2 个节点时也只会丢失 1/3 的数据,我们也可以将`number_of_replicas`调大到 2:
...
...
@@ -987,11 +987,11 @@ Elasticsearch 会将文档内容拆分为词条,创建一个包含所有不重
**段合并**
:由于每秒钟 refresh 都会产生一个新的 segment(段),段数量过多会导致过多的消耗文件句柄、内存和 CPU 时间,影响查询速度。基于这个原因,Lucene 通过合并段来解决这个问题,即将一小部分大小相似的段合并为一个更大的段:


如图:段合并将两个已经提交了的段和一个没有提交的段合并为了一个更大的段,合并时已删除的文档不会被合并到大的分段当中。


合并完成后,老的段被删除,新的段被 flush 到磁盘。
...
...
notes/中间件/img/5781124193bae6ab972bmayuan.jpg
0 → 100644
浏览文件 @
efab319b
53.6 KB
notes/中间件/img/conteplonkohit.jpg
0 → 100644
浏览文件 @
efab319b
48.6 KB
notes/中间件/
NoSQL数据库/Image
/elas_0202.png
→
notes/中间件/
img
/elas_0202.png
浏览文件 @
efab319b
文件已移动
notes/中间件/
NoSQL数据库/Image
/elas_0203.png
→
notes/中间件/
img
/elas_0203.png
浏览文件 @
efab319b
文件已移动
notes/中间件/
NoSQL数据库/Image
/elas_0204.png
→
notes/中间件/
img
/elas_0204.png
浏览文件 @
efab319b
文件已移动
notes/中间件/
NoSQL数据库/Image
/elas_0205.png
→
notes/中间件/
img
/elas_0205.png
浏览文件 @
efab319b
文件已移动
notes/中间件/
NoSQL数据库/Image
/elas_1110.png
→
notes/中间件/
img
/elas_1110.png
浏览文件 @
efab319b
文件已移动
notes/中间件/
NoSQL数据库/Image
/elas_1111.png
→
notes/中间件/
img
/elas_1111.png
浏览文件 @
efab319b
文件已移动
notes/中间件/img/g20nblonblogs.jpg
0 → 100644
浏览文件 @
efab319b
35.1 KB
notes/中间件/消息队列中间件/消息队列中间件-Kafka.md
浏览文件 @
efab319b
...
...
@@ -111,6 +111,7 @@ Kafka 基本操作:
>
2. Partitions(分区):消息的实际存储单位。
>
3. Producer(生产者):消息生产者。
>
4. Consumer(消费者):消息消费者。
>
5. Broker(代理):服务器上运行的 Kafka 的实例,在 Kafka 集群中每一个 Broker 对应一个唯一的 ID,即 BrokerId。
...
...
@@ -183,5 +184,628 @@ Kafka 主题 Topic 操作:
#### 2.Kafka API-客户端操作
Kafka 主要为我们提供了五类 API:
1.
**AdminClient API**
:允许管理和检测 Topic、Broker 以及其他 Kafka 实例,与 Kafka 自带的脚本命令作用类似。
2.
**Producer API**
:发布消息到 1 个或多个 Topic,也就是生产者或者说发布方需要用到的 API。
3.
**Consumer API**
:订阅 1 个或多个 Topic,并处理产生的消息,也就是消费者或者说订阅方需要用到的 API。
4.
**Stream API**
:高效地将输入流转换到输出流,通常应用在一些流处理场景。
5.
**Connector API**
:从一些源系统或应用程序拉取数据到 Kafka。
引入对应版本依赖:
~~~
xml
<dependency>
<groupId>
org.apache.kafka
</groupId>
<artifactId>
kafka-clients
</artifactId>
<version>
2.8.0
</version>
</dependency>
~~~
创建 AdminClient:
~~~
java
public
class
AdminClientTest
{
public
static
void
main
(
String
[]
args
)
{
Properties
properties
=
new
Properties
();
properties
.
setProperty
(
AdminClientConfig
.
BOOTSTRAP_SERVERS_CONFIG
,
"192.168.253.136:9092"
);
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
System
.
out
.
println
(
adminClient
);
adminClient
.
close
();
}
}
~~~
创建 Topic:
~~~
java
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
NewTopic
newTopic
=
new
NewTopic
(
"order"
,
1
,
(
short
)
1
);
CreateTopicsResult
result
=
adminClient
.
createTopics
(
Collections
.
singleton
(
newTopic
));
System
.
out
.
println
(
result
);
adminClient
.
close
();
~~~
> :desert_island: 需要远程连接 Kafka 时,配置文件的 listeners 不能使用 localhost。
查询 Topic:
~~~
java
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
ListTopicsResult
result
=
adminClient
.
listTopics
();
result
.
names
().
get
().
forEach
(
System
.
out
::
println
);
// 列出包含内部 Topic 的清单
ListTopicsOptions
options
=
new
ListTopicsOptions
().
listInternal
(
true
);
ListTopicsResult
optionResult
=
adminClient
.
listTopics
(
options
);
optionResult
.
names
().
get
().
forEach
(
System
.
out
::
println
);
adminClient
.
close
();
---------------------------------------------------------
news
order
...
news
__consumer_offsets
order
~~~
查询 Topic 时,可以带 ListTopicsOptions 进行查询。
删除 Topic:
~~~
java
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
adminClient
.
deleteTopics
(
Collections
.
singleton
(
"news"
));
adminClient
.
close
();
~~~
查看 Topic 描述信息:
~~~
java
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
DescribeTopicsResult
result
=
adminClient
.
describeTopics
(
Collections
.
singleton
(
"order"
));
result
.
all
().
get
().
forEach
((
k
,
v
)
->
System
.
out
.
println
(
v
.
toString
()));
adminClient
.
close
();
---------------------------------------------------------
(
name
=
order
,
internal
=
false
,
partitions
=(
partition
=
0
,
leader
=
192.168
.
253.136
:
9092
(
id:
0
rack:
null
),
replicas
=
192.168
.
253.136
:
9092
(
id:
0
rack:
null
),
isr
=
192.168
.
253.136
:
9092
(
id:
0
rack:
null
)),
authorizedOperations
=
null
)
~~~
查看 Topic 描述信息:
~~~
java
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
ConfigResource
configResource
=
new
ConfigResource
(
ConfigResource
.
Type
.
TOPIC
,
"order"
);
DescribeConfigsResult
configs
=
adminClient
.
describeConfigs
(
Collections
.
singleton
(
configResource
));
configs
.
all
().
get
().
forEach
((
k
,
v
)
->
System
.
out
.
println
(
v
.
toString
()));
adminClient
.
close
();
---------------------------------------------------------
Config
(
entries
=[
ConfigEntry
(
name
=
compression
.
type
,
value
=
producer
,
source
=
DEFAULT_CONFIG
...
~~~
Topic 配置信息修改:
~~~
java
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
Map
<
ConfigResource
,
Collection
<
AlterConfigOp
>>
configs
=
new
HashMap
<>();
ConfigResource
configResource
=
new
ConfigResource
(
ConfigResource
.
Type
.
TOPIC
,
"order"
);
Set
<
AlterConfigOp
>
configOps
=
Collections
.
singleton
(
new
AlterConfigOp
(
new
ConfigEntry
(
"preallocate"
,
"true"
),
AlterConfigOp
.
OpType
.
SET
));
configs
.
put
(
configResource
,
configOps
);
adminClient
.
incrementalAlterConfigs
(
configs
);
DescribeConfigsResult
configsResult
=
adminClient
.
describeConfigs
(
Collections
.
singleton
(
configResource
));
System
.
out
.
println
(
configsResult
.
all
().
get
().
get
(
configResource
).
get
(
"preallocate"
));
adminClient
.
close
();
~~~
增加 Topic 的 Partitions 数量:
~~~
java
AdminClient
adminClient
=
AdminClient
.
create
(
properties
);
Map
<
String
,
NewPartitions
>
newPartitions
=
new
HashMap
<>();
newPartitions
.
put
(
"order"
,
NewPartitions
.
increaseTo
(
2
));
adminClient
.
createPartitions
(
newPartitions
);
adminClient
.
close
();
~~~
---
#### 3.Kafka API-Producer
>
:apple:
在
Kafka
中,所有的消息发送均以<u>异步</u>的方式进行发送。
P
roducer 异步发送实例:
~
~~java
p
ublic class ProducerTest {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.253.136:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(properties);
Order order = newOrder("显示器");
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("order", order.getOrderId(), JSONUtil.toJsonStr(order));
Future<RecordMetadata> sendResult = producer.send(producerRecord);
producer.close();
}
}
~
~~
P
roducer 在发送数据后将会立即返回一个 Future\<RecordMetadata\> 供我们后续进行调用获取结果。
>
:ear_of_rice: Kafka 默认提供了 String、Integer 等的序列化器,如果我们需要直接发送对象则需要自定义 StringSerializer。
P
roducer 异步回调发送实例:
~
~~java
p
ublic class ProducerTest {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.253.136:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(properties);
Order order = newOrder("显示器");
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("order", order.getOrderId(), JSONUtil.toJsonStr(order));
Future<RecordMetadata> sendResult = producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println("do something...");
}
});
producer.close();
}
}
~
~~
P
roducer 消息发送过程:
1
. 构建 KafkaProducer,构建过程如下:
1. 初始化参数...
2. 通过 RPC 远程调用获取 metadata,在 metadata 中包含整个 Kafka 集群信息,包括分区和 Broker。
3. 创建累加器 accumulator:通过累加器来判断何时进行发送。
在 KafkaProducer 中,消息以批量发送,当消息累计到具体数量或者时间超过某阈值时执行一次批量发送,具体的配置如下:
~~~java
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "16384");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "1"); // ms 为单位
~~~
4. 创建 sender 客户端并启动。
2
. 执行 send 方法,执行的过程如下:
1. 对消息头、Topic 进行序列化。
2. 计算分区,判断消息应该进入哪一个分区。
3. 将消息追加到 accumulator 中(accumulator.append)并获取追加的结果。
> :dart: 代码中调用 send 方法时,实际上是将这一批消息累加到了 KafkaProducer 的 accumulator 中,然后在达到阈值时进行发送。
4. 根据结果判断是否进行批量发送:
~~~java
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
~~~
5. 将消息发送到指定分区的 leader 节点(Broker)上,由 Broker 进行存储。
在
KafkaProducer 中获取分区时,Kafka 默认分区机制为:
1
. 如果 ProducerRecord 中指定了分区,则直接使用(可以在 KafkaProducer 构造器中进行指定)。
2
. 如果未指定分区,但指定了 key 值,则根据 key 的 hash 值选择一个分区(相同的 key 所发送到的 Partition 是同一个,可保证消息的局部有序性)
3
. 如果未指定分区,也未指定 key 值,则以 '黏性分区' 策略(2.4 版本以前使用轮询策略)选择一个分区。
部
分代码如下:
~
~~java
p
ublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
~
~~
>
:neutral_face: 黏性分区策略:择单个分区发送所有无 Key 的消息。一旦这个分区的 batch 已满或处于 "已完成" 状态,黏性分区器会随机地选择另一个分区并会尽可能地坚持使用该分区(像黏住这个分区一样)直到这个分区的 batch 也满了或处于 "已完成" 状态。
除
此之外,我们还可以自定义分区策略(实现`org.apache.kafka.clients.producer.Partitioner`)并对 properties 进行配置:
~
~~java
p
roperties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.star.kafka.config.MyPartitioner");
~
~~
-
--
#### 4.Kafka API-Consumer
Kafka 消费者概念:
1.
Consumer Group:消费组是 Kafka 提供的可扩展且具有容错性的消费者机制,一个消费组包含多个消费者实例,它们共享一个公共的 Group ID,组内的所有消费者协调在一起来消费 Topics 的所有分区,每个 Partiton 只能被消费组内的某一个 Consumer 所消费。
2.
Offset:偏移量专指 Partition 以及 Consumer Group 而言,记录某个 Consumer 在对应的 Partiton 中当前已经消费到达的位置;如果某消费者宕机,接替的消费者将从 Offset 处重新开始消费消息。
Kafka 中 Offset 的管理方式:
在 0.9 版本之前,Kafka 将 Offset 保存在 Zookeeper 中,但 Zookeeper 并不适合进行大批量的读写操作。在此之后,Kafka 通过内部主题
`__consumer_offsets`
来管理 Offset 信息,每个 Consumer 将 Offset 消息发送至该主题。
Kafka 集群启动时,Kafka 就会自动创建位移主题,默认的分区数是 50,副本数是 3。
Comsumer 提交位移的方式:
1.
自动提交位移:Kafka 默认定期自动提交位移。
~~~
properties
enable.auto.commit
=
true
auto.commit.interval.ms
=
1
~~~
每隔
`auto.commit.interval.ms`
所指定的毫秒数后,Consumer 便会自动提交 Offset 到内部主题
`__consumer_offsets`
中。
~~~
java
public
class
ConsumerTest
{
public
static
void
main
(
String
[]
args
)
{
Properties
properties
=
new
Properties
();
properties
.
setProperty
(
ConsumerConfig
.
BOOTSTRAP_SERVERS_CONFIG
,
"192.168.253.136:9092"
);
properties
.
setProperty
(
ConsumerConfig
.
GROUP_ID_CONFIG
,
"store_system"
);
properties
.
setProperty
(
ConsumerConfig
.
KEY_DESERIALIZER_CLASS_CONFIG
,
"org.apache.kafka.common.serialization.StringDeserializer"
);
properties
.
setProperty
(
ConsumerConfig
.
VALUE_DESERIALIZER_CLASS_CONFIG
,
"org.apache.kafka.common.serialization.StringDeserializer"
);
Consumer
<
String
,
String
>
consumer
=
new
KafkaConsumer
<>(
properties
);
// 订阅 order 主题
consumer
.
subscribe
(
Collections
.
singleton
(
"order"
));
while
(
true
)
{
// 每隔一秒拉取一次消息
ConsumerRecords
<
String
,
String
>
records
=
consumer
.
poll
(
Duration
.
ofSeconds
(
1L
));
records
.
forEach
(
record
->
System
.
out
.
println
(
record
.
toString
()));
}
}
}
~~~
> :baby_chick: Consumer 除了订阅主题以外,还可以指定分区进行订阅:
>
> ~~~java
> TopicPartition tp = new TopicPartition("order", 0);
> consumer.assign(Collections.singleton(tp));
> ~~~
2.
手动提交位移:设置
`enable.auto.commit=false`
,然后在代码中进行手动提交。
~~~
JAVA
while (true) {
// 每隔一秒拉取一次消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1L));
try {
// 处理数据
records.forEach(record -> System.out.println(record.toString()));
}catch (Exception e) {
// 进行回滚不提交 Offset
}
// 所有 records 处理成功后提交 Offset
consumer.commitSync();
}
~~~
:black_flag: 分 Partition 进行 Offset 提交:
~~~
java
while
(
true
)
{
// 每隔一秒拉取一次消息
ConsumerRecords
<
String
,
String
>
records
=
consumer
.
poll
(
Duration
.
ofSeconds
(
1L
));
records
.
partitions
().
forEach
(
partition
->
{
// 获取这一批消息中包含的分区
List
<
ConsumerRecord
<
String
,
String
>>
partitionRecords
=
records
.
records
(
partition
);
try
{
// 按分区处理数据
partitionRecords
.
forEach
(
record
->
System
.
out
.
println
(
record
.
toString
()));
}
catch
(
Exception
e
)
{
// 进行回滚
}
// 当一个分区的 records 处理成功后提交该分区的 Offset
long
offset
=
partitionRecords
.
get
(
partitionRecords
.
size
()
-
1
).
offset
();
OffsetAndMetadata
offsetAndMetadata
=
new
OffsetAndMetadata
(
offset
+
1
);
consumer
.
commitSync
(
Collections
.
singletonMap
(
partition
,
offsetAndMetadata
));
});
}
~~~
分 Partition 进行 Offset 提交的好处:当消费者接收到一批消息时,这批消息可能来自多个分区,如果统一进行 Offset 提交则只有当这一批消息都处理成功才能提交。如果分 Partition 进行 Offset 提交,则我们可以允许部分 Partition 成功而部分 Partition 失败,此时我们只需要重新消费处理消息失败的 Partition 即可。
Consumer 多线程消费可以分为两种实现方式:
1.
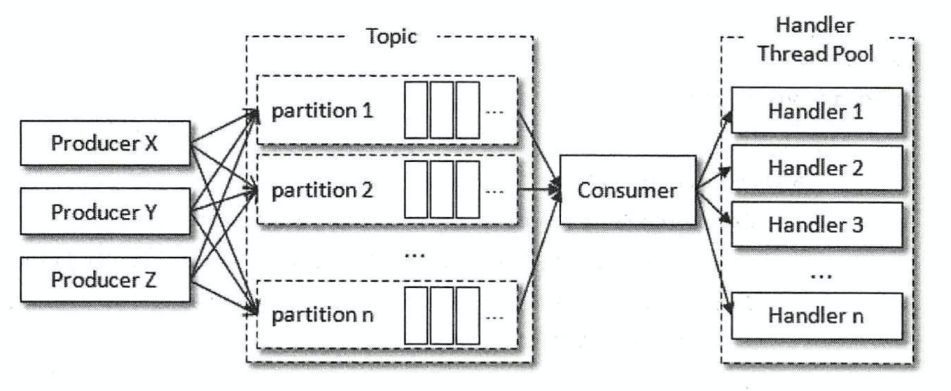
每一个 Partition 对应一个 Consumer 线程,Consumer 线程负责消息的获取和处理,此种方式保证了线程安全,实现起来也比较简单。
!
[](
../img/g20nblonblogs.jpg
)
此种方式消费数据的缺点:
1.
消费者的个数受限于 Partition 的数量,无法很好地进行扩展。
2.
在每一个线程中都维护了一个 Consumer 对象,占用的系统资源较大。
2.
由一个或几个 Consumer 专门负责消息获取,然后交由处理数据的线程池进行处理:
!
[](
D:\GitRepository\HexBook\notes\中间件\img\5781124193bae6ab972bmayuan.jpg
)
此种方式消费数据的并发能力高且容易扩展,但是也存在着一些缺点:
1.
无法感知数据处理线程的处理结果,可能会丢失数据。
应用场景:
-
如果是对数据的一致性要求较高的场景,则需要采用多 Consumer 的处理方式。
-
如果是处理流式数据,对数据的准确性要求不高,则使用第二种多线程的方式更为合适。
手工控制 offset 位置:在实际的消费过程中,如果我们在发生错误后需要重复消费,或者是使用了第三方组件来记录 Offset(如 Redis),我们在消费时还可以手动指定 Offset 位置:
~~~
java
while
(
true
)
{
// 每隔一秒拉取一次消息
ConsumerRecords
<
String
,
String
>
records
=
consumer
.
poll
(
Duration
.
ofSeconds
(
1L
));
// 从头开始获取消息
consumer
.
seekToBeginning
(
records
.
partitions
());
records
.
partitions
().
forEach
(
partition
->
{
List
<
ConsumerRecord
<
String
,
String
>>
partitionRecords
=
records
.
records
(
partition
);
try
{
// 处理数据
partitionRecords
.
forEach
(
record
->
System
.
out
.
println
(
record
.
toString
()));
}
catch
(
Exception
e
)
{
// 进行回滚
}
long
offset
=
partitionRecords
.
get
(
partitionRecords
.
size
()
-
1
).
offset
();
OffsetAndMetadata
offsetAndMetadata
=
new
OffsetAndMetadata
(
offset
+
1
);
consumer
.
commitSync
(
Collections
.
singletonMap
(
partition
,
offsetAndMetadata
));
});
}
~~~
> :cactus: 除此之外,Consumer 还提供了 pause 和 resume 方法,可以结合<u>令牌桶</u>进行流量控制。
---
#### 5.Kafka 消息传递保障
:kimono: 在 Kafka 中对消息传递的保障有下列三种担保语义:
1. 最多一次:消息可能丢失,但绝不会重发。
2. 最少一次:消息绝不会丢失,但有可能重新发送。
3. 正好一次:每个消息传递一次且仅一次。
Producer 端对着三种语义的支持:
Kafka 中通过配置 acks 来控制 Broker 对 Producer 的应答策略,具体的值和说明如下:
|
参数
|
说明
|
|
-------- | ------------------------------------------------------------ |
|
acks=0 | 如果设置为零,那么生产者根本不会等待来自服务器的任何确认。该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下不能保证服务器已经收到记录,并且 retries 配置不会生效,每个记录返回的偏移量将始终设置为 -1。 |
|
acks=1 | 如果设置为壹,这意味着 leader 节点会将记录写入其本地日志,但会在不等待所有 follower 节点的完全确认的情况下进行响应。在这种情况下,如果 leader 节点在确认记录后立即失败,但 follower 节点还未进行复制,则记录将丢失。 |
|
acks=all | 这意味着 leader 节点将等待完整的同步副本集确认记录。这保证了只要至少一个同步副本还活着,记录就不会丢失,是最强的可用保证。 |
当
我们配置`acks=0`或者禁用`retries`时,就实现了`最多一次`的担保语义;如果配置`acks=all`并启动`retries`时,则实现了`最少一次`的担保语义。
当
acks 的值为 1 或 all 时,如果 Broker 报告失败,Producer 则会根据 retries 配置进行重试,如果 Broker 已经记录了数据但是因为网络原因未正确返回成功到 Producer 时,消息可能会重复,Kafka 通过两种方式来保证消息的生产不产生重复:
1
. 幂等传递:Kafka 在 Broker 中为每个生产者分配一个 ID,并通过生产者发送的序列号为每个消息进行去重。
开启幂等性`enable.idempotence=true`,同时还需要满足几个要求:
1. **retries** 在指定重试次数的时候,这个参数必须大于 0,默认为`Integer.MAX_VALUE`。
2. **max.in.flight.requests.per.connection** 这个参数必须大于等于 5,默认为 5。
3. **acks** 必须指定为 -1(all)。
注意:<u>幂等性只能保证单个主题的单个分区上不出现重复消息,如果要实现多个分区的幂等性必须使用事务</u>。
2
. 使用事务:使用时需要设置 Producer 的 transactional.id 例如`transactional.id=producer-01`。
事务使用代码如下:
~~~java
producer.initTransactions();
try {
producer.beginTransaction();
// 发送多次消息...
Future<RecordMetadata> sendResult = producer.send(producerRecord);
// 发送多次消息...
producer.commitTransaction();
}catch (Exception e) {
producer.abortTransaction();
}
~~~
在使用事务时,还需要对 Consumer 设置`isolation.level`参数的,当前这个参数有两个取值:
1. `read_uncommitted`:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。
2. `read_committed`:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
C
onsumer 端对着三种语义的支持:
消
费者在消费消息时一般分为 3 个步骤:读取消息、处理消息,保存消息的位置(Offset),不同的执行顺序可以实现不同的语义支持:
1
. 读取消息、保存消息的位置、最后处理消息:在这种情况下,有可能消费者保存了位置之后,但是处理消息输出之前崩溃了,此时接管处理的进程会在已保存的位置开始,即使该位置之前有几个消息尚未处理成功。这对应于`最多一次`的担保语义。
2
. 读取消息、处理消息、最后保存消息的位置:在这种情况下,可能消费进程处理消息之后,但保存它的位置之前崩溃了,此时新的进程将接收已经被处理的前几个消息,这就符合了`至少一次`的语义(在多数情况下消息有一个主键,业务系统可以编写相关逻辑对重复消费的消息进行去重)。
如
果要实现`正好一次`的担保语义,也就代表着处理消息,保存消息的位置这两个动作必须在同一个事务当中,有两种方式可以进行实现:
1
. 在保存消息的位置和处理消息之间引入**<u>两阶段提交</u>**。
2
. 将 Offset 保存在处理消息(存储消息)的系统当中。
例如:处理消息是将消息存在 MySQL 中,则将 Offset 也保存在 MySQL 中,保存 Offset 和保存消息使用同一个事务进行。
>
:ear_of_rice: 综上所述:Kafka 默认是保证`至少一次`传递,并允许用户通过禁止生产者重试和处理一批消息前提交它的偏移量来实现`最多一次`传递,而`正好一次`传递需要与目标存储系统合作,但 Kafka 提供了偏移量,实现起来也比较简单。
-
--
#### 6.Kafka API-Stream
Kafka Stream 是处理存储在 Kafka 的数据的客户端程序库。
> :dragon_face: Kafka Stream 基本概念:
>
> 1. Stream(流):Kafka 中流代表一个无限的,不断更新的数据集,一个 Stream 是一个有序的,允许重放的不可变的数据记录,其中数据记录被定义为一个容错的键值对。
> 2. Processor Topology(处理拓扑):流处理拓扑定义了由流数据处理的计算逻辑,相当于流程图。
> 3. Stream Processor(流处理器):流处理器用来处理拓扑中的各个节点,它代表拓扑中的每个处理步骤,用来完成数据转换功能;除一般的处理器外,Kafka 中还有两种特殊的处理器:
> 1. 源处理器:该处理器没有任何上游处理器,它从 Kafka 的一个或多个主题消费数据作为处理拓扑的输入流,将该输入流发送到下游处理器。
> 2. Sink 处理器:该处理器没有任何下游处理器,它将从上游处理器接收到的任何数据发送到指定的主题当中。
流处理状态:
1.
一些流处理应用不需要状态,这意味着每个消息的处理都是彼此独立的。如果你只需要进行消息转换,或者基于某些条件进行筛选,那么你的流处理应用程序的拓扑会非常简单。
2.
然而,能够保存状态,使得流处理系统可以应用在更多场景。你可以进行 Join、Group by 或者 aggregate 操作,Kafka Streams 就是这种包含状态的流处理。
使用 Kafka Stream 需要引入依赖:
~~~
xml
<dependency>
<groupId>
org.apache.kafka
</groupId>
<artifactId>
kafka-streams
</artifactId>
<version>
2.8.0
</version>
</dependency>
~~~
使用 Kafka Stream 编写 Word Count 流计算实例:
1.
创建两个 Topic,一个用来接收存储在 Kafka 的数据,一个用于输出警告流处理完成后的数据。
2.
编写流处理程序:
~~~
java
public
class
StreamTest
{
public
static
void
main
(
String
[]
args
)
{
Properties
properties
=
new
Properties
();
properties
.
setProperty
(
StreamsConfig
.
BOOTSTRAP_SERVERS_CONFIG
,
"192.168.253.136:9092"
);
properties
.
setProperty
(
StreamsConfig
.
APPLICATION_ID_CONFIG
,
"stream_application"
);
properties
.
setProperty
(
StreamsConfig
.
DEFAULT_KEY_SERDE_CLASS_CONFIG
,
ClassUtil
.
getClassName
(
Serdes
.
String
().
getClass
(),
false
));
properties
.
setProperty
(
StreamsConfig
.
DEFAULT_VALUE_SERDE_CLASS_CONFIG
,
ClassUtil
.
getClassName
(
Serdes
.
String
().
getClass
(),
false
));
// 构建流
StreamsBuilder
streamsBuilder
=
new
StreamsBuilder
();
// 流处理拓扑
countWord
(
streamsBuilder
);
KafkaStreams
streams
=
new
KafkaStreams
(
streamsBuilder
.
build
(),
properties
);
// 开启流
streams
.
start
();
}
public
static
void
countWord
(
final
StreamsBuilder
streamsBuilder
)
{
KStream
<
String
,
String
>
sources
=
streamsBuilder
.
stream
(
"stream_in"
);
// 将 values 进行 flatMap
KTable
<
String
,
Long
>
count
=
sources
.
flatMapValues
(
text
->
Arrays
.
asList
(
text
.
toLowerCase
().
split
(
" "
)))
.
groupBy
((
k
,
v
)
->
v
)
.
count
();
// 输出键值对到 stream_out 这个 Topic 中,其中 key 为 string 类型,value 为 long 类型
count
.
toStream
().
to
(
"stream_out"
,
Produced
.
with
(
Serdes
.
String
(),
Serdes
.
Long
()));
}
}
~~~
3.
向
`stream_in`
这个 Topic 发送文字消息。
4.
监听
`stream_out`
(需指定一些参数):
~~~
shell
/usr/local/kafka/bin/kafka-console-consumer.sh
--bootstrap-server
192.168.253.136:9092
--topic
stream_out
\
--property
print.key
=
true
--property
print.value
=
true
\
--property
key.deserializer
=
org.apache.kafka.common.serialization.StringDeserializer
\
--property
value.deserializer
=
org.apache.kafka.common.serialization.LongDeserializer
\
--from-beginning
~~~
向
`stream_in`
发送文字消息时,Kafka Stream 将会持续性地对流数据进行统计处理并输出到
`stream_out`
中。
KStream(事件流)和 KTable(changelog 流):
1.
KStream 就是数据流,它不间断地获取 Topic 中的内容,并且每一次获取都是向其中插入新数据(insert)。
2.
KTable 类似于传统数据库,它是截止到某一个窗口时间内的数据集合的抽象,每一次操作,都是更新插入(upsert)。
KTable负责抽象的,就是表状数据。每一次操作,都是更新插入(upsert)。
---
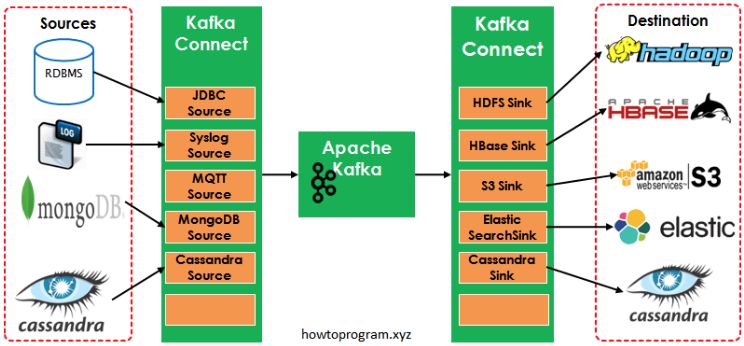
#### 7.Kafka API-Connect
Kafka Connect 是 Kafka 流式计算的一部分,主要用来跟其他中间件建立流式通道。
<img src="D:\GitRepository\HexBook\notes\中间件\img\conteplonkohit.jpg" />
Kafka Connect 提供了一套统一的 API 用来与其他系统的集成,目前已经有很多开源的和商业版本的 Kafka Connect 实现。
---
#### 8.Kafka 集群
---
#### 9.Kafka 集群监控
---
#### 10.Kafka 集成微服务
---
#### 11.Kafka 常见面试题
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
