爬取时间:2019-10-12
爬取难度:★★☆☆☆☆
请求链接:https://bbs.hupu.com/bxj
爬取目标:爬取虎扑论坛步行街的帖子,包含主题,作者,发布时间等,数据保存到 MongoDB 数据库
涉及知识:请求库 requests、解析库 Beautiful Soup、数据库 MongoDB 的操作
完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/hupu
其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
【1x00】循环爬取网页模块
观察虎扑论坛步行街分区,请求地址为:https://bbs.hupu.com/bxj
第一页:https://bbs.hupu.com/bxj
第二页:https://bbs.hupu.com/bxj-2
第三页:https://bbs.hupu.com/bxj-3
不难发现,每增加一页,只需要添加 -页数 参数即可,最后一页是第 50 页,因此可以利用 for 循环依次爬取,定义一个 get_pages() 函数,返回初始化 Beautiful Soup 的对象 page_soup,方便后面的解析函数调用
虽然一共有 50 页,但是当用户访问第 10 页以后的页面的时候,会要求登录虎扑,不然就没法查看,而且登录时会出现智能验证,所以程序只爬取前 10 页的数据
1
2
3
4
5
6
7
8
9
10
11
12
| def get_pages(page_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url=page_url, headers=headers)
page_soup = BeautifulSoup(response.text, 'lxml')
return page_soup
if __name__ == '__main__':
for i in range(1, 11):
url = 'https://bbs.hupu.com/bxj-' + str(i)
soup = get_pages(url)
|
【2x00】解析模块
使用 Beautiful Soup 对网页各个信息进行提取,最后将这些信息放进一个列表里,然后调用列表的 .append() 方法,再将每条帖子的列表依次加到另一个新列表里,最终返回的是类似于如下形式的列表:
1
| [['帖子1', '作者1'], ['帖子2', '作者2'], ['帖子3', '作者3']]
|
这样做的目的是:方便 MongoDB 依次储存每一条帖子的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| def parse_pages(page_soup):
data_list = []
all_list = page_soup.find('ul', class_='for-list')
post_list = all_list.find_all('li')
for post in post_list:
post_title = post.find('a', class_='truetit').text
post_url = 'https://bbs.hupu.com' + post.find('a', class_='truetit')['href']
author = post.select('.author > a')[0].text
author_url = post.select('.author > a')[0]['href']
post_date = post.select('.author > a')[1].text
reply_view = post.find('span', class_='ansour').text
post_reply = reply_view.split('/')[0].strip()
post_view = reply_view.split('/')[1].strip()
last_data = post.select('.endreply > a')[0].text
last_user = post.select('.endreply > span')[0].text
data_list.append([post_title, post_url, author, author_url, post_date, post_reply, post_view, last_data, last_user])
return data_list
|
【3x00】MongoDB 数据储存模块
首先使用 MongoClient() 方法,向其传入地址参数 host 和 端口参数 port,指定数据库为 hupu,集合为 bxj
将解析函数返回的列表传入到储存函数,依次循环该列表,对每一条帖子的信息进行提取并储存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def mongodb(data_list):
client = MongoClient('localhost', 27017)
db = client.hupu
collection = db.bxj
for data in data_list:
bxj = {
'帖子名称': data[0],
'帖子链接': data[1],
'作者': data[2],
'作者主页': data[3],
'发布日期': str(data[4]),
'回复数': data[5],
'浏览量': data[6],
'最后回复时间': str(data[7]),
'最后回复用户': data[8]
}
collection.insert_one(bxj)
|
【4x00】完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
import requests
import time
import random
from pymongo import MongoClient
from bs4 import BeautifulSoup
def get_pages(page_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url=page_url, headers=headers)
page_soup = BeautifulSoup(response.text, 'lxml')
return page_soup
def parse_pages(page_soup):
data_list = []
all_list = page_soup.find('ul', class_='for-list')
post_list = all_list.find_all('li')
for post in post_list:
post_title = post.find('a', class_='truetit').text
post_url = 'https://bbs.hupu.com' + post.find('a', class_='truetit')['href']
author = post.select('.author > a')[0].text
author_url = post.select('.author > a')[0]['href']
post_date = post.select('.author > a')[1].text
reply_view = post.find('span', class_='ansour').text
post_reply = reply_view.split('/')[0].strip()
post_view = reply_view.split('/')[1].strip()
last_data = post.select('.endreply > a')[0].text
last_user = post.select('.endreply > span')[0].text
data_list.append([post_title, post_url, author, author_url, post_date, post_reply, post_view, last_data, last_user])
return data_list
def mongodb(data_list):
client = MongoClient('localhost', 27017)
db = client.hupu
collection = db.bxj
for data in data_list:
bxj = {
'帖子名称': data[0],
'帖子链接': data[1],
'作者': data[2],
'作者主页': data[3],
'发布日期': str(data[4]),
'回复数': data[5],
'浏览量': data[6],
'最后回复时间': str(data[7]),
'最后回复用户': data[8]
}
collection.insert_one(bxj)
if __name__ == '__main__':
for i in range(1, 11):
url = 'https://bbs.hupu.com/bxj-' + str(i)
soup = get_pages(url)
result_list = parse_pages(soup)
mongodb(result_list)
print('第', i, '页数据爬取完毕!')
time.sleep(random.randint(3, 10))
print('前10页所有数据爬取完毕!')
|
【5x00】数据截图
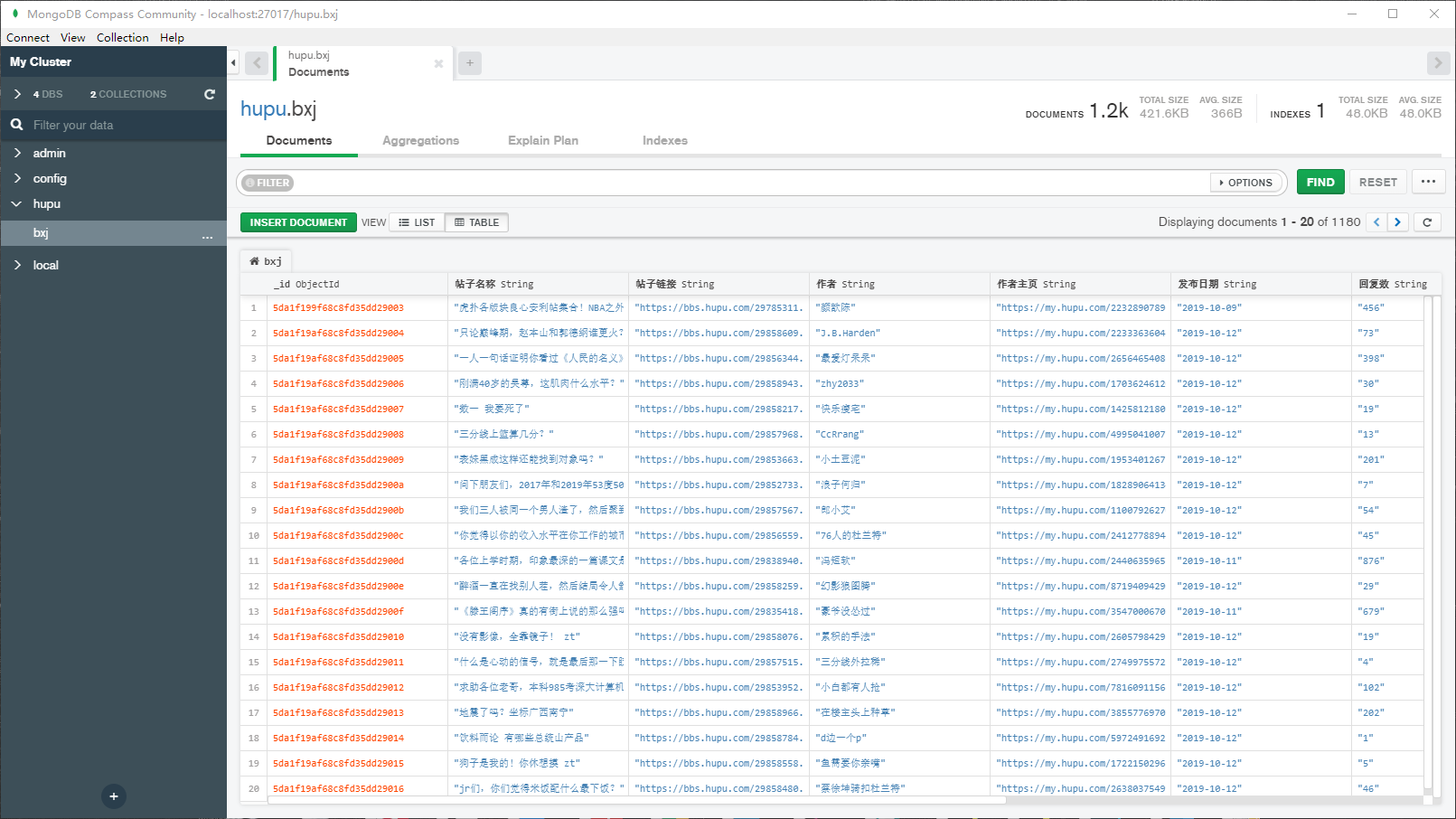
一共爬取到 1180 条数据:
【6x00】程序不足的地方
程序只能爬取前 10 页的数据,因为虎扑论坛要求从第 11 页开始,必须登录账号才能查看,并且登录时会有智能验证,可以使用自动化测试工具 Selenium 模拟登录账号后再进行爬取。


:https://github.com/TRHX/Python3-Spider-Practice爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
)
:https://github.com/TRHX/Python3-Spider-Practice爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
)
:https://github.com/TRHX/Python3-Spider-Practice爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
)