init project
上级
Showing
CMakeLists.txt
0 → 100644
CONTRIBUTING.md
0 → 100644
LICENSE
0 → 100644
NOTICE
0 → 100644
README.md
0 → 100644
RELEASE.md
0 → 100644
此差异已折叠。
build.sh
0 → 100644
cmake/RT.cmake
0 → 100644
cmake/external_libs/isl.cmake
0 → 100644
cmake/utils.cmake
0 → 100644
docs/akg-design.png
0 → 100644
{kind=link}
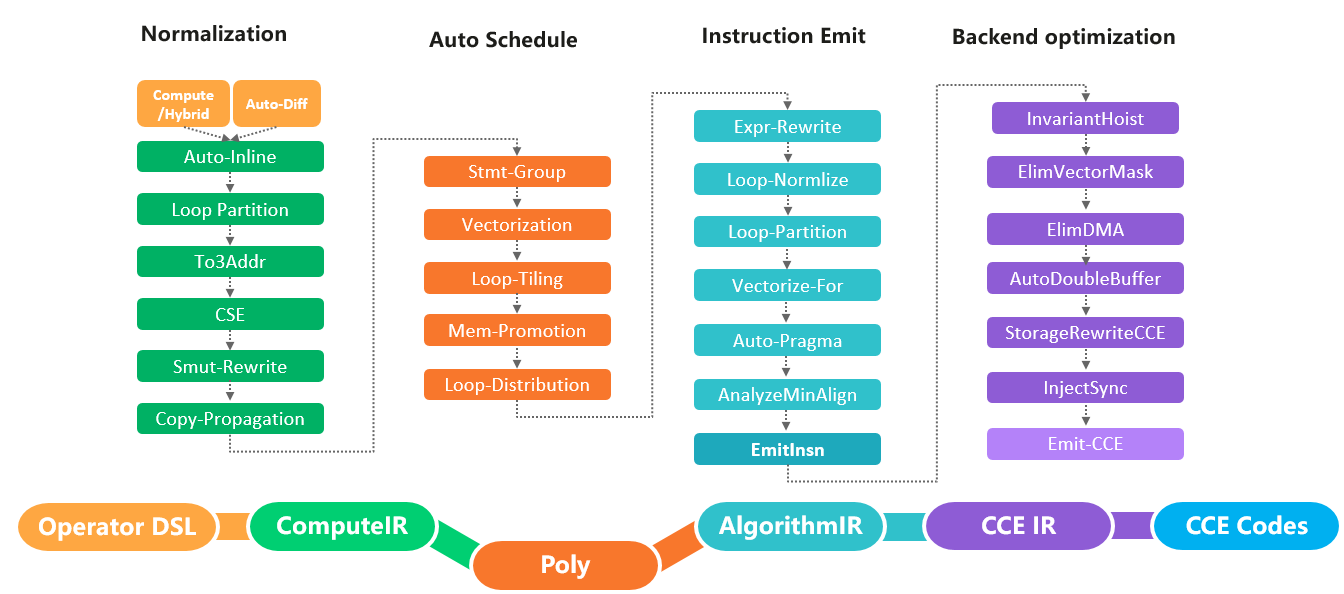
56.2 KB
python/akg/__init__.py
0 → 100644
python/akg/autodiff.py
0 → 100644
python/akg/backend/__init__.py
0 → 100644
python/akg/backend/aic_model.py
0 → 100644
python/akg/backend/cce_buffer.py
0 → 100644
python/akg/backend/cce_build.py
0 → 100644
python/akg/backend/cce_conf.py
0 → 100644
python/akg/backend/cce_params.py
0 → 100644
python/akg/backend/cce_runtime.py
0 → 100644
python/akg/build_module.py
0 → 100644
python/akg/composite/__init__.py
0 → 100644
此差异已折叠。
python/akg/contrib/__init__.py
0 → 100644
python/akg/dim.py
0 → 100644
python/akg/lang/__init__.py
0 → 100644
python/akg/lang/cce/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ms/__init__.py
0 → 100644
python/akg/ms/cce/__init__.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/add.py
0 → 100644
python/akg/ms/cce/addn.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/argmax.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/assign_add.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/bias_add.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ms/cce/cast.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/clear_zero.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/conv.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ms/cce/conv_bn1.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/div.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/equal.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/equal_count.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/exp.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/five2four.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/floordiv.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/four2five.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ms/cce/fused_bn1.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/fused_bn2.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/fused_bn3.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ms/cce/gather_v2.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/less.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/log.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/matmul.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/max.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ms/cce/mean.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/mean_grad.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/mul.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/neg.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/one_hot.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/realdiv.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/reciprocal.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/reduce_mean.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/relu.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/relu_grad.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/reshape.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/softmax.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ms/cce/sub.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/sum.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/tile.py
0 → 100644
此差异已折叠。
python/akg/ms/cce/zeros_like.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/__init__.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/cast.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ms/gpu/equal.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/mean.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/mean_grad.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/mul.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/relu6.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/relu6_grad.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/squeeze.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/squeeze_grad.py
0 → 100644
此差异已折叠。
python/akg/ms/gpu/tile.py
0 → 100644
此差异已折叠。
python/akg/ms/message.py
0 → 100644
此差异已折叠。
python/akg/ms/op_build.py
0 → 100644
此差异已折叠。
python/akg/ms/save_gpu_param.py
0 → 100644
此差异已折叠。
python/akg/ms/utils.py
0 → 100644
此差异已折叠。
python/akg/ops/__init__.py
0 → 100644
python/akg/ops/array/__init__.py
0 → 100644
python/akg/ops/array/five2four.py
0 → 100644
此差异已折叠。
python/akg/ops/array/four2five.py
0 → 100644
此差异已折叠。
python/akg/ops/array/gather_v2.py
0 → 100644
此差异已折叠。
python/akg/ops/array/one_hot.py
0 → 100644
此差异已折叠。
python/akg/ops/array/reshape.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/array/tile.py
0 → 100644
此差异已折叠。
python/akg/ops/math/__init__.py
0 → 100644
python/akg/ops/math/abs.py
0 → 100644
此差异已折叠。
python/akg/ops/math/abs_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/math/add.py
0 → 100644
此差异已折叠。
python/akg/ops/math/addn.py
0 → 100644
此差异已折叠。
python/akg/ops/math/argmax.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/math/cast.py
0 → 100644
此差异已折叠。
python/akg/ops/math/div.py
0 → 100644
此差异已折叠。
python/akg/ops/math/equal.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/math/exp.py
0 → 100644
此差异已折叠。
python/akg/ops/math/exp_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/math/floor.py
0 → 100644
此差异已折叠。
python/akg/ops/math/floordiv.py
0 → 100644
此差异已折叠。
python/akg/ops/math/less.py
0 → 100644
此差异已折叠。
python/akg/ops/math/log.py
0 → 100644
此差异已折叠。
python/akg/ops/math/log_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/math/mean.py
0 → 100644
此差异已折叠。
python/akg/ops/math/mul.py
0 → 100644
此差异已折叠。
python/akg/ops/math/neg.py
0 → 100644
此差异已折叠。
python/akg/ops/math/realdiv.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/math/reciprocal.py
0 → 100644
此差异已折叠。
python/akg/ops/math/reduce_max.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/math/rsqrt.py
0 → 100644
此差异已折叠。
python/akg/ops/math/sub.py
0 → 100644
此差异已折叠。
python/akg/ops/math/sum.py
0 → 100644
此差异已折叠。
python/akg/ops/math/tanh.py
0 → 100644
此差异已折叠。
python/akg/ops/math/tanh_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/__init__.py
0 → 100644
python/akg/ops/nn/avgpool.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/nn/batchmatmul.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/bias_add.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/bias_add_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/conv.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ops/nn/conv_bn1.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ops/nn/maxpool.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/maxpool_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/maxpool_grad.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/nn/mean_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/relu.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/relu_ad.py
0 → 100644
此差异已折叠。
python/akg/ops/nn/softmax.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/akg/ops/nn/zeros_like.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/ops/state/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/utils/__init__.py
0 → 100644
python/akg/utils/custom_tiling.py
0 → 100644
此差异已折叠。
python/akg/utils/dsl_create.py
0 → 100644
此差异已折叠。
python/akg/utils/dynamic_shape.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/akg/utils/kernel_exec.py
0 → 100644
此差异已折叠。
python/akg/utils/math.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
requirements.txt
0 → 100644
此差异已折叠。
src/api/api_mem.cc
0 → 100644
此差异已折叠。
src/api/api_pass.cc
0 → 100644
此差异已折叠。
src/api/api_schedule.cc
0 → 100644
此差异已折叠。
src/codegen/build_cce.cc
0 → 100644
此差异已折叠。
src/codegen/build_module.cc
0 → 100644
此差异已折叠。
src/codegen/intrin_rule_cce.cc
0 → 100644
此差异已折叠。
src/codegen/pass_mgr.cc
0 → 100644
此差异已折叠。
src/codegen/pass_mgr.h
0 → 100644
此差异已折叠。
src/codegen/util.cc
0 → 100644
此差异已折叠。
src/codegen/util.h
0 → 100644
此差异已折叠。
src/common/array_api.h
0 → 100644
此差异已折叠。
src/common/common.cc
0 → 100644
此差异已折叠。
src/common/util_cce.h
0 → 100644
此差异已折叠。
src/composite/composite.cc
0 → 100644
此差异已折叠。
src/composite/composite_topi.cc
0 → 100644
此差异已折叠。
src/composite/util.h
0 → 100644
此差异已折叠。
src/contrib/cce_parm/cceconf.cc
0 → 100644
此差异已折叠。
src/contrib/cce_parm/cceconf.h
0 → 100644
此差异已折叠。
src/contrib/cce_parm/cceparam.cc
0 → 100644
此差异已折叠。
src/contrib/cce_parm/cceparam.h
0 → 100644
此差异已折叠。
src/contrib/parser/Grammar
0 → 100644
此差异已折叠。
src/contrib/parser/NOTICE
0 → 100644
此差异已折叠。
src/contrib/parser/ast.cc
0 → 100644
此差异已折叠。
src/contrib/parser/ast.h
0 → 100644
此差异已折叠。
src/contrib/parser/codegen.cc
0 → 100644
此差异已折叠。
src/contrib/parser/codegen.h
0 → 100644
此差异已折叠。
src/contrib/parser/grammar.cc
0 → 100644
此差异已折叠。
src/contrib/parser/grammar.h
0 → 100644
此差异已折叠。
src/contrib/parser/key_word.md
0 → 100644
此差异已折叠。
src/contrib/parser/meta_token.md
0 → 100644
此差异已折叠。
src/contrib/parser/parser.cc
0 → 100644
此差异已折叠。
src/contrib/parser/parser.h
0 → 100644
此差异已折叠。
src/contrib/parser/token.cc
0 → 100644
此差异已折叠。
src/contrib/parser/token.h
0 → 100644
此差异已折叠。
src/emit_insn/cce_params.h
0 → 100644
此差异已折叠。
此差异已折叠。
src/emit_insn/insn_builder.cc
0 → 100644
此差异已折叠。
src/emit_insn/insn_builder.h
0 → 100644
此差异已折叠。
src/emit_insn/insn_builder_dma.cc
0 → 100644
此差异已折叠。
src/emit_insn/insn_builder_rpn.cc
0 → 100644
此差异已折叠。
此差异已折叠。
src/emit_insn/insn_emitter.cc
0 → 100644
此差异已折叠。
src/emit_insn/insn_emitter.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/emit_insn/insn_info.cc
0 → 100644
此差异已折叠。
src/emit_insn/insn_info.h
0 → 100644
此差异已折叠。
此差异已折叠。
src/emit_insn/insn_pattern.cc
0 → 100644
此差异已折叠。
src/emit_insn/insn_pattern.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/include/build_module.h
0 → 100644
此差异已折叠。
src/include/floating.h
0 → 100644
此差异已折叠。
src/include/ir_generictree.h
0 → 100644
此差异已折叠。
src/include/ir_pass.h
0 → 100644
此差异已折叠。
src/include/schedule_pass.h
0 → 100644
此差异已折叠。
src/include/tvm.h
0 → 100644
此差异已折叠。
src/lang/cgtypes.h
0 → 100644
此差异已折叠。
src/pass/algebra_simplify.cc
0 → 100644
此差异已折叠。
此差异已折叠。
src/pass/align_partition.cc
0 → 100644
此差异已折叠。
src/pass/allocate_unify.cc
0 → 100644
此差异已折叠。
src/pass/analyze_align.h
0 → 100644
此差异已折叠。
src/pass/analyze_align_dynamic.cc
0 → 100644
此差异已折叠。
src/pass/analyze_align_static.cc
0 → 100644
此差异已折叠。
src/pass/append_stride_msg.cc
0 → 100644
此差异已折叠。
src/pass/append_stride_msg.h
0 → 100644
此差异已折叠。
src/pass/arch.h
0 → 100644
此差异已折叠。
src/pass/arith_expr_simplify.cc
0 → 100644
此差异已折叠。
src/pass/arith_expr_simplify.h
0 → 100644
此差异已折叠。
src/pass/atomic_dma_elim.cc
0 → 100644
此差异已折叠。
src/pass/auto_double_buffer.cc
0 → 100644
此差异已折叠。
src/pass/auto_mad_pragma_attr.cc
0 → 100644
此差异已折叠。
src/pass/auto_pragma.cc
0 → 100644
此差异已折叠。
src/pass/auto_reorder.cc
0 → 100644
此差异已折叠。
src/pass/autodiff.cc
0 → 100644
此差异已折叠。
src/pass/autodiff.h
0 → 100644
此差异已折叠。
src/pass/autodiff_cce.cc
0 → 100644
此差异已折叠。
src/pass/autodiff_cce.h
0 → 100644
此差异已折叠。
src/pass/broadcast_rewrite.cc
0 → 100644
此差异已折叠。
src/pass/bypass_l1.cc
0 → 100644
此差异已折叠。
src/pass/c0_expand_split.cc
0 → 100644
此差异已折叠。
src/pass/canonical_form.cc
0 → 100644
此差异已折叠。
src/pass/canonical_form.h
0 → 100644
此差异已折叠。
src/pass/cast_filter.cc
0 → 100644
此差异已折叠。
src/pass/cast_kernel_params.cc
0 → 100644
此差异已折叠。
src/pass/cast_normalize.cc
0 → 100644
此差异已折叠。
src/pass/check_shape_params.cc
0 → 100644
此差异已折叠。
src/pass/coarsen-img2col.cc
0 → 100644
此差异已折叠。
src/pass/coarsen-img2col.h
0 → 100644
此差异已折叠。
src/pass/collect_external_call.cc
0 → 100644
此差异已折叠。
src/pass/common.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/pass/convert_if_to_select.cc
0 → 100644
此差异已折叠。
src/pass/convolution_model.cc
0 → 100644
此差异已折叠。
src/pass/convolution_model.h
0 → 100644
此差异已折叠。
src/pass/copy_propagation.cc
0 → 100644
此差异已折叠。
src/pass/correct_tilingcover.cc
0 → 100644
此差异已折叠。
此差异已折叠。
src/pass/cse.cc
0 → 100644
此差异已折叠。
src/pass/dataflow_analyze.cc
0 → 100644
此差异已折叠。
src/pass/dead_code_elim.cc
0 → 100644
此差异已折叠。
src/pass/dependency_graph.h
0 → 100644
此差异已折叠。
src/pass/dma_sink.cc
0 → 100644
此差异已折叠。
src/pass/dtype_adapter.cc
0 → 100644
此差异已折叠。
src/pass/dump_c.cc
0 → 100644
此差异已折叠。
src/pass/dump_tensor.cc
0 → 100644
此差异已折叠。
src/pass/elim_vector_mask.cc
0 → 100644
此差异已折叠。
src/pass/emit_insn.cc
0 → 100644
此差异已折叠。
src/pass/emit_insn_debugger.cc
0 → 100644
此差异已折叠。
src/pass/expr_alg_simplify.cc
0 → 100644
此差异已折叠。
src/pass/expr_alg_simplify.h
0 → 100644
此差异已折叠。
src/pass/expr_pattern_rewrite.cc
0 → 100644
此差异已折叠。
src/pass/feature_lib_transform.cc
0 → 100644
此差异已折叠。
src/pass/fix_bind_buffer.cc
0 → 100644
此差异已折叠。
src/pass/fix_loop_extent.cc
0 → 100644
此差异已折叠。
src/pass/fix_mad_attrs.cc
0 → 100644
此差异已折叠。
src/pass/fix_realize_shape.cc
0 → 100644
此差异已折叠。
src/pass/flatten_elementwise.cc
0 → 100644
此差异已折叠。
src/pass/for_eliminate.cc
0 → 100644
此差异已折叠。
src/pass/gather_loop_info.cc
0 → 100644
此差异已折叠。
src/pass/hoist_fmatrix.cc
0 → 100644
此差异已折叠。
src/pass/if_eliminate.cc
0 → 100644
此差异已折叠。
src/pass/inject_attr.cc
0 → 100644
此差异已折叠。
src/pass/inject_pipe.cc
0 → 100644
此差异已折叠。
src/pass/inject_sync.cc
0 → 100644
此差异已折叠。
src/pass/inject_thread_bind.cc
0 → 100644
此差异已折叠。
src/pass/insn_to_pip.cc
0 → 100644
此差异已折叠。
src/pass/ir_generictree.cc
0 → 100644
此差异已折叠。
src/pass/isolate_loops.cc
0 → 100644
此差异已折叠。
src/pass/load3d_transform.cc
0 → 100644
此差异已折叠。
src/pass/loop_normlize.cc
0 → 100644
此差异已折叠。
src/pass/loop_switch_hoist.cc
0 → 100644
此差异已折叠。
src/pass/lower_select.cc
0 → 100644
此差异已折叠。
src/pass/lower_with.cc
0 → 100644
此差异已折叠。
src/pass/math_intrin_rewrite.cc
0 → 100644
此差异已折叠。
src/pass/merge_loops.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/pass/optimize_pragma.cc
0 → 100644
此差异已折叠。
src/pass/overflow_check.h
0 → 100644
此差异已折叠。
src/pass/pooling_transform.cc
0 → 100644
此差异已折叠。
src/pass/post_fusion.cc
0 → 100644
此差异已折叠。
src/pass/post_fusion_utils.cc
0 → 100644
此差异已折叠。
src/pass/post_fusion_utils.h
0 → 100644
此差异已折叠。
src/pass/postprocess_img2col.cc
0 → 100644
此差异已折叠。
此差异已折叠。
src/pass/promote_common_expr.cc
0 → 100644
此差异已折叠。
src/pass/promote_const_expr.cc
0 → 100644
此差异已折叠。
src/pass/promote_if.cc
0 → 100644
此差异已折叠。
src/pass/promote_let.cc
0 → 100644
此差异已折叠。
此差异已折叠。
src/pass/realize_compress.cc
0 → 100644
此差异已折叠。
src/pass/reduce_fusion_opt.cc
0 → 100644
此差异已折叠。
src/pass/remove_assert.cc
0 → 100644
此差异已折叠。
src/pass/rename_realize.cc
0 → 100644
此差异已折叠。
src/pass/replace_fargmax_cast.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/pass/rewrite_floordiv.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/pass/rewrite_simplify_cce.cc
0 → 100644
此差异已折叠。
src/pass/rewrite_simplify_cce.h
0 → 100644
此差异已折叠。
src/pass/rewrite_tensor_index.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/pass/sink_allocate.cc
0 → 100644
此差异已折叠。
src/pass/sink_if.cc
0 → 100644
此差异已折叠。
src/pass/special_value_replace.cc
0 → 100644
此差异已折叠。
此差异已折叠。
src/pass/stmt_pattern_rewrite.cc
0 → 100644
此差异已折叠。
src/pass/storage_access_cce.cc
0 → 100644
此差异已折叠。
src/pass/storage_rewrite_cce.cc
0 → 100644
此差异已折叠。
src/pass/storage_rewrite_cce.h
0 → 100644
此差异已折叠。
src/pass/stride_kernel_op.cc
0 → 100644
此差异已折叠。
src/pass/substitute_div_var.cc
0 → 100644
此差异已折叠。
src/pass/to_three_address.cc
0 → 100644
此差异已折叠。
src/pass/unify_loop_vars.cc
0 → 100644
此差异已折叠。
此差异已折叠。
src/pass/utils.cc
0 → 100644
此差异已折叠。
src/pass/utils.h
0 → 100644
此差异已折叠。
src/pass/value_numbering.cc
0 → 100644
此差异已折叠。
src/pass/vectorize_for.cc
0 → 100644
此差异已折叠。
src/pass/zero_elimination.cc
0 → 100644
此差异已折叠。
src/pass/zero_elimination.h
0 → 100644
此差异已折叠。
src/poly/cce_isl_emitter.cc
0 → 100644
此差异已折叠。
src/poly/cce_isl_emitter.h
0 → 100644
此差异已折叠。
src/poly/cce_optimizer.cc
0 → 100644
此差异已折叠。
src/poly/custom_tiling.h
0 → 100644
此差异已折叠。
src/poly/dma_dataflow.cc
0 → 100644
此差异已折叠。
src/poly/dma_dataflow.h
0 → 100644
此差异已折叠。
src/poly/dma_inject.cc
0 → 100644
此差异已折叠。
src/poly/dma_inject.h
0 → 100644
此差异已折叠。
src/poly/dump_log.cc
0 → 100644
此差异已折叠。
src/poly/dump_log.h
0 → 100644
此差异已折叠。
src/poly/dynamic_shape.h
0 → 100644
此差异已折叠。
src/poly/gen_tiling_space.cc
0 → 100644
此差异已折叠。
src/poly/isl.h
0 → 100644
此差异已折叠。
src/poly/isl_emitter.cc
0 → 100644
此差异已折叠。
src/poly/isl_emitter.h
0 → 100644
此差异已折叠。
src/poly/memory_manager.cc
0 → 100644
此差异已折叠。
src/poly/poly.cc
0 → 100644
此差异已折叠。
src/poly/poly_util.cc
0 → 100644
此差异已折叠。
src/poly/poly_util.h
0 → 100644
此差异已折叠。
src/poly/reschedule.cc
0 → 100644
此差异已折叠。
src/poly/reschedule.h
0 → 100644
此差异已折叠。
src/poly/rm_self_dep.cc
0 → 100644
此差异已折叠。
src/poly/rm_self_dep.h
0 → 100644
此差异已折叠。
src/poly/schtree_analyzer.cc
0 → 100644
此差异已折叠。
src/poly/schtree_analyzer.h
0 → 100644
此差异已折叠。
src/poly/scop.cc
0 → 100644
此差异已折叠。
src/poly/scop.h
0 → 100644
此差异已折叠。
src/poly/scop_builder.cc
0 → 100644
此差异已折叠。
src/poly/scop_builder.h
0 → 100644
此差异已折叠。
src/poly/scop_dynamic.cc
0 → 100644
此差异已折叠。
src/poly/scop_info.cc
0 → 100644
此差异已折叠。
src/poly/sink_axis.cc
0 → 100644
此差异已折叠。
src/poly/sink_axis.h
0 → 100644
此差异已折叠。
src/poly/space_analyzer.cc
0 → 100644
此差异已折叠。
src/poly/space_analyzer.h
0 → 100644
此差异已折叠。
src/poly/spec_gemm_builder.cc
0 → 100644
此差异已折叠。
src/poly/stmt_parse.cc
0 → 100644
此差异已折叠。
src/poly/stmt_parse.h
0 → 100644
此差异已折叠。
src/poly/tile_space.h
0 → 100644
此差异已折叠。
src/poly/tiling.cc
0 → 100644
此差异已折叠。
src/poly/tiling_algorithm.h
0 → 100644
此差异已折叠。
src/poly/tiling_analyzer.cc
0 → 100644
此差异已折叠。
src/poly/tiling_analyzer.h
0 → 100644
此差异已折叠。
src/poly/tiling_solver.cc
0 → 100644
此差异已折叠。
src/poly/tiling_solver.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/poly/tiling_utils.cc
0 → 100644
此差异已折叠。
src/poly/tiling_utils.h
0 → 100644
此差异已折叠。
src/poly/transform.cc
0 → 100644
此差异已折叠。
src/poly/transform.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/runtime/csim/half_float.h
0 → 100644
此差异已折叠。
此差异已折叠。
src/runtime/stub/runtime_stub.cc
0 → 100644
此差异已折叠。
src/schedule/auto_inline.cc
0 → 100644
此差异已折叠。
tests/__init__.py
0 → 100644
tests/common/__init__.py
0 → 100644
tests/common/base.py
0 → 100644
此差异已折叠。
tests/common/boot.py
0 → 100644
此差异已折叠。
tests/common/ftp_handel.py
0 → 100644
此差异已折叠。
tests/common/fuzz.py
0 → 100644
此差异已折叠。
tests/common/gen_json_data.py
0 → 100644
此差异已折叠。
tests/common/gen_random.py
0 → 100644
此差异已折叠。
tests/common/log.py
0 → 100644
此差异已折叠。
tests/common/profiling_base.py
0 → 100644
此差异已折叠。
tests/common/tensorio.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/__init__.py
0 → 100644
tests/common/test_op/abs_sum.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/acos.py
0 → 100644
此差异已折叠。
tests/common/test_op/acos_grad.py
0 → 100644
此差异已折叠。
tests/common/test_op/acosh.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/add_ad.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/argmin.py
0 → 100644
此差异已折叠。
tests/common/test_op/asin.py
0 → 100644
此差异已折叠。
tests/common/test_op/asin_grad.py
0 → 100644
此差异已折叠。
tests/common/test_op/asinh.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/assign.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/atan.py
0 → 100644
此差异已折叠。
tests/common/test_op/atan2.py
0 → 100644
此差异已折叠。
tests/common/test_op/atan_grad.py
0 → 100644
此差异已折叠。
tests/common/test_op/atanh.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/axpy.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/bc_test.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/blas_axby.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/ceil.py
0 → 100644
此差异已折叠。
tests/common/test_op/cholesky.py
0 → 100644
此差异已折叠。
tests/common/test_op/clip.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/col2im.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/concat.py
0 → 100644
此差异已折叠。
tests/common/test_op/concat_ad.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/cos.py
0 → 100644
此差异已折叠。
tests/common/test_op/cos_ad.py
0 → 100644
此差异已折叠。
tests/common/test_op/cosh.py
0 → 100644
此差异已折叠。
tests/common/test_op/cross.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/dense.py
0 → 100644
此差异已折叠。
tests/common/test_op/depthwise.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/diagpart.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/dropout.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/eltwise.py
0 → 100644
此差异已折叠。
tests/common/test_op/elu.py
0 → 100644
此差异已折叠。
tests/common/test_op/elu_ad.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/erf.py
0 → 100644
此差异已折叠。
tests/common/test_op/erf_ad.py
0 → 100644
此差异已折叠。
tests/common/test_op/erfc.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/expm1.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/fc.py
0 → 100644
此差异已折叠。
tests/common/test_op/fill.py
0 → 100644
此差异已折叠。
tests/common/test_op/flatten.py
0 → 100644
此差异已折叠。
tests/common/test_op/floormod.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/gather.py
0 → 100644
此差异已折叠。
tests/common/test_op/gelu.py
0 → 100644
此差异已折叠。
tests/common/test_op/gelu_ad.py
0 → 100644
此差异已折叠。
tests/common/test_op/gelu_grad.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/greater.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/im2col.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/inv_grad.py
0 → 100644
此差异已折叠。
tests/common/test_op/invert.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/l1_loss.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/l2loss.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/lin_space.py
0 → 100644
此差异已折叠。
tests/common/test_op/load3d.py
0 → 100644
此差异已折叠。
tests/common/test_op/log1p.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/lstm_rnn.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/matmul.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/matmul_ad.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/maximum.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/minimum.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/mul_ad.py
0 → 100644
此差异已折叠。
tests/common/test_op/nms.py
0 → 100644
此差异已折叠。
tests/common/test_op/not_equal.py
0 → 100644
此差异已折叠。
tests/common/test_op/ones_like.py
0 → 100644
此差异已折叠。
tests/common/test_op/pack.py
0 → 100644
此差异已折叠。
tests/common/test_op/pad.py
0 → 100644
此差异已折叠。
tests/common/test_op/pooling.py
0 → 100644
此差异已折叠。
tests/common/test_op/pow.py
0 → 100644
此差异已折叠。
tests/common/test_op/prelu.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/range.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/relu6.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/relu_grad.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/reverse.py
0 → 100644
此差异已折叠。
tests/common/test_op/rint.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/roipool.py
0 → 100644
此差异已折叠。
tests/common/test_op/round.py
0 → 100644
此差异已折叠。
tests/common/test_op/rsqrt_ad.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/scale.py
0 → 100644
此差异已折叠。
tests/common/test_op/scatter_.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/select.py
0 → 100644
此差异已折叠。
tests/common/test_op/selu.py
0 → 100644
此差异已折叠。
tests/common/test_op/sgd.py
0 → 100644
此差异已折叠。
tests/common/test_op/sigmoid.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/sign.py
0 → 100644
此差异已折叠。
tests/common/test_op/sin.py
0 → 100644
此差异已折叠。
tests/common/test_op/sinh.py
0 → 100644
此差异已折叠。
tests/common/test_op/slice.py
0 → 100644
此差异已折叠。
tests/common/test_op/sliceeven.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/softplus.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/softsign.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/split.py
0 → 100644
此差异已折叠。
tests/common/test_op/sqrt.py
0 → 100644
此差异已折叠。
tests/common/test_op/sqrt_ad.py
0 → 100644
此差异已折叠。
tests/common/test_op/square.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/squeeze.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/sub_ad.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/tan.py
0 → 100644
此差异已折叠。
tests/common/test_op/tanh_grad.py
0 → 100644
此差异已折叠。
tests/common/test_op/topk.py
0 → 100644
此差异已折叠。
tests/common/test_op/transpose.py
0 → 100644
此差异已折叠。
tests/common/test_op/triangle.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/unpack.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_op/where.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_op/xdivy.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/__init__.py
0 → 100644
此差异已折叠。
tests/common/test_run/abs_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/acos_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/add_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/addn_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/asin_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/atan_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/axpy_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/bc_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/cast_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/ceil_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/clip_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/conv_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/cos_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/cosh_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/div_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/elu_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/erf_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/erfc_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_run/exp_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/fc_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/fill_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/gelu_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/less_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/log_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/mean_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/mod_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_run/mul_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/neg_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/nms_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/pack_run.py
0 → 100644
此差异已折叠。
tests/common/test_run/pad_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/common/test_run/pow_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/common/test_run/relu_run.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。