Dev sx insightface (#127)
* add insightface pr template * update readme and add fp32 results * update readme * update readme and modify scripts * update insightface readme and add reports * add pics in chinese report * add pics in english * add en pics * refine readme.md * update test pics * upfate report * Update dlperf_insightface_test_report_v1.md test pic * Create dlperf_insightface_test_report_v1.md test pics again * fix pic bug * Update dlperf_insightface_test_report_v1.md * fix data * add new path of insightface and update as reviewed * refine scripts and update readme * update data and pics * modify as reviewed * update report as reviewed * modify OOM into - and rm invalid pics' links * fix mxnet max num_classes * update changelog * update change log * add insightface report links and introduction * modify as reviewed * modify as reviewed * fix part num and dataset zoo * rm data preprocess part * update link * update data of 2 nodes * add multi node scripts * update results of 4 nodes * update report * update pics * update mxnet data * update multi-node scripts and rm different insightface_train.py * rm insightface_train.py and mv config into scripts with sed * update gnuplot img Co-authored-by: NLiang Depeng <liangdepeng@gmail.com> Co-authored-by: NFlowingsun007 <flowingsun007@163.com> Co-authored-by:MARD1NO <359521840@qq.com>
Showing
{kind=link}
29.8 KB
{kind=link}
29.8 KB
{kind=link}
28.3 KB
{kind=link}
28.1 KB
{kind=link}
22.7 KB
{kind=link}
18.8 KB
{kind=link}
21.4 KB
{kind=link}
{kind=link}
| W: | H:
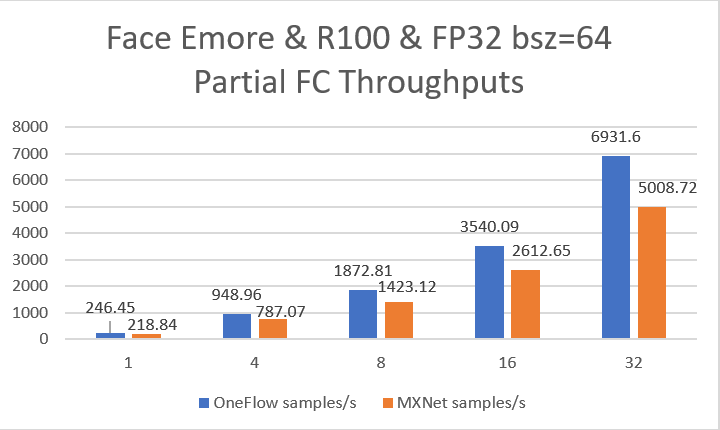
| W: | H:
{kind=link}
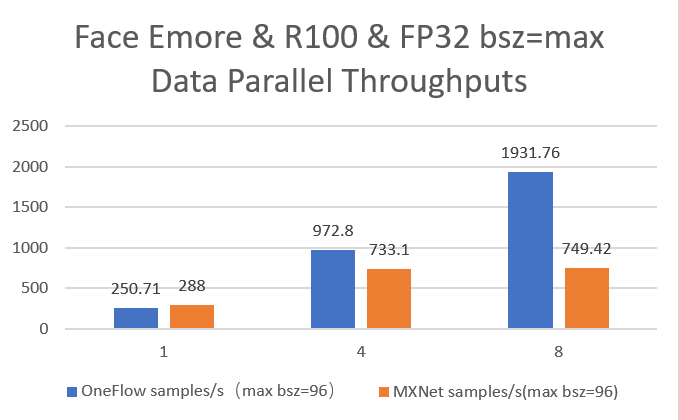
21.7 KB
{kind=link}
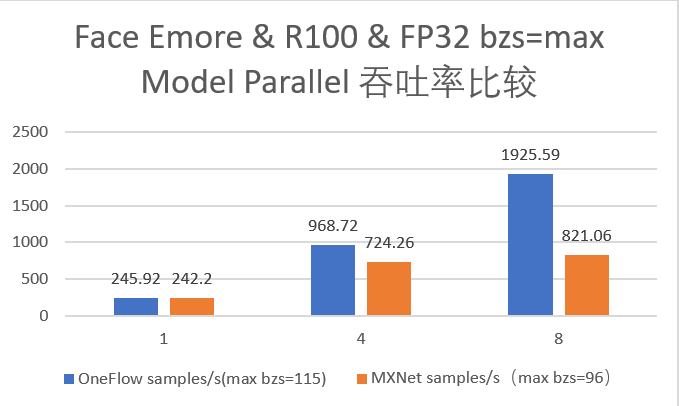
22.7 KB
{kind=link}
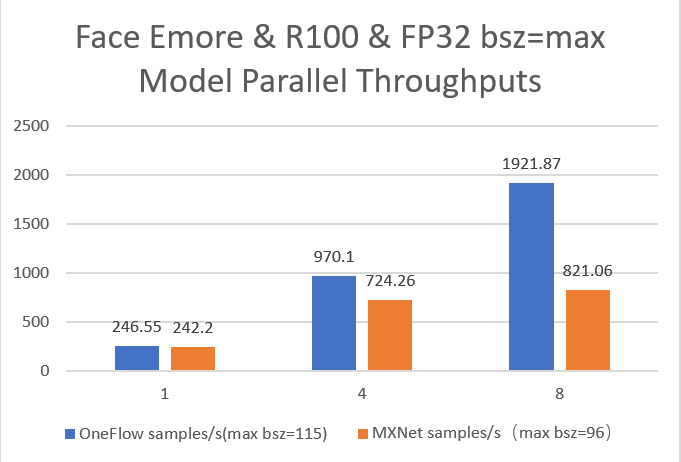
22.1 KB
{kind=link}
{kind=link}
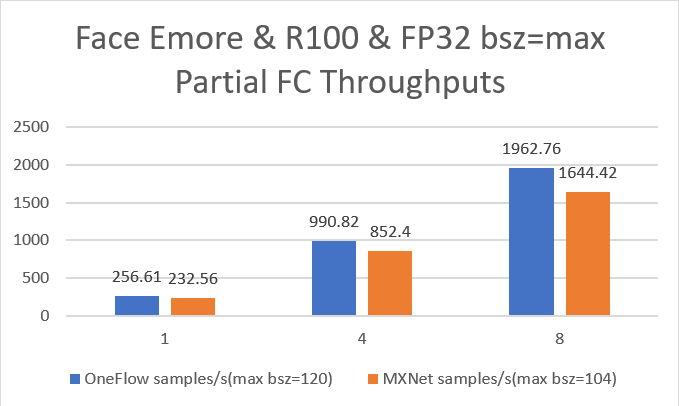
| W: | H:
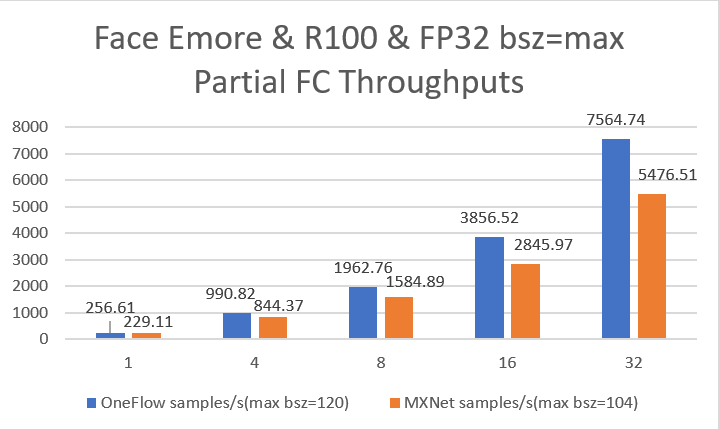
| W: | H:
{kind=link}
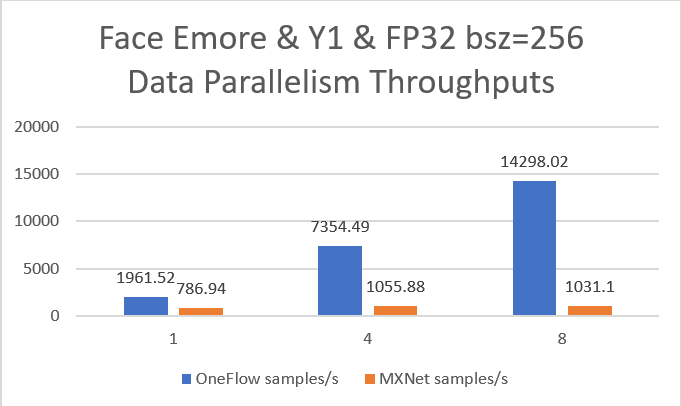
19.9 KB
{kind=link}
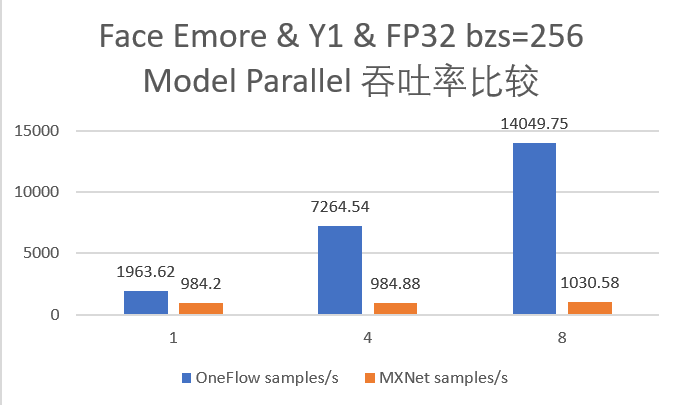
20.4 KB
{kind=link}
19.4 KB
{kind=link}
21.3 KB
{kind=link}
21.5 KB
{kind=link}
21.9 KB
{kind=link}
19.8 KB
{kind=link}
21.1 KB
{kind=link}
30.2 KB
{kind=link}
30.1 KB
{kind=link}
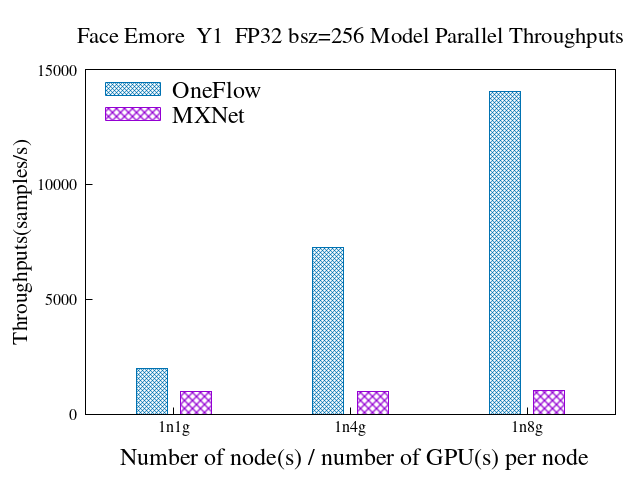
28.4 KB
{kind=link}
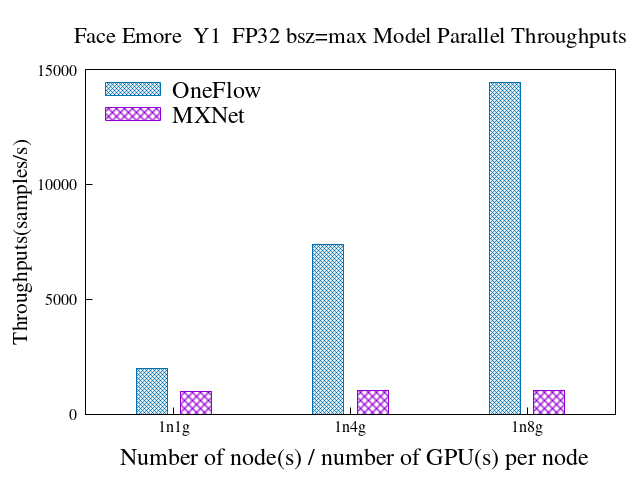
28.2 KB
{kind=link}
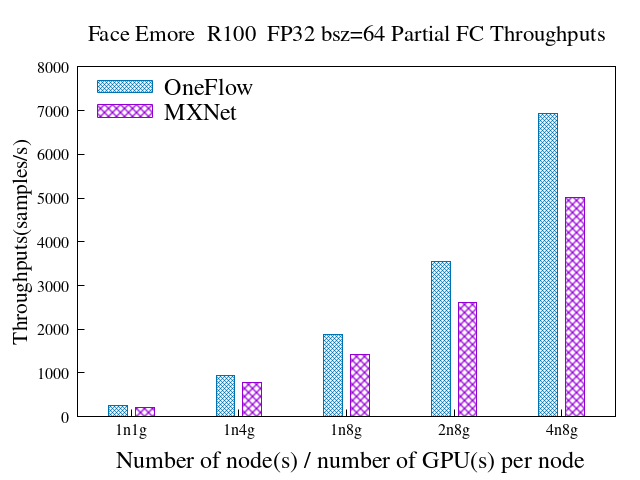
33.1 KB
{kind=link}
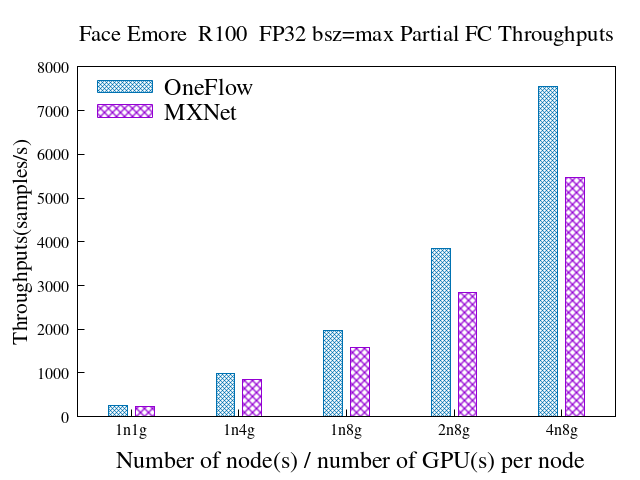
33.0 KB
{kind=link}
31.0 KB
{kind=link}
31.4 KB