2020-10-19 21:18:53
Showing
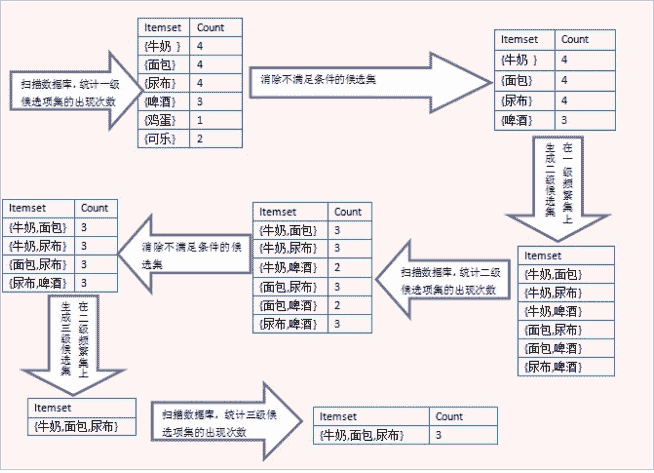
docs/ml/img/Apriori流程图.png
0 → 100644
{kind=link}
22.9 KB
{kind=link}
7.8 KB
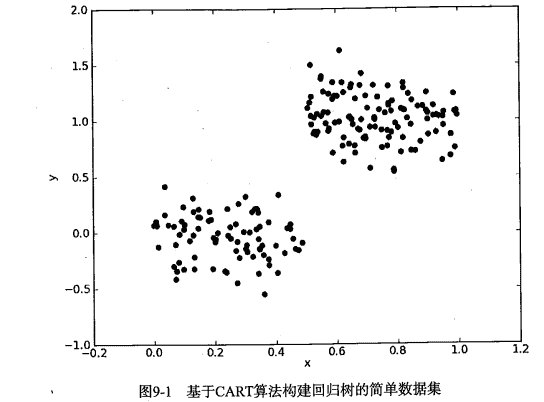
docs/ml/img/DT_海洋生物数据.png
0 → 100644
{kind=link}

1.5 KB
{kind=link}

95.9 KB
{kind=link}

101.6 KB
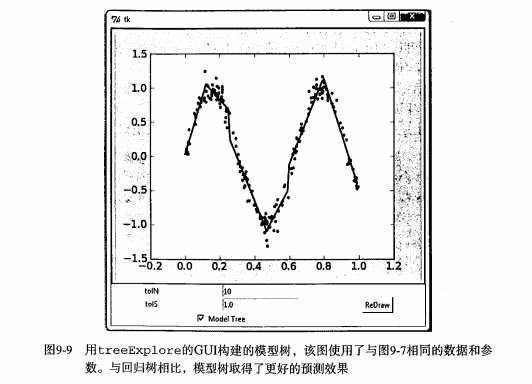
docs/ml/img/GUI更好的示例图.png
0 → 100644
{kind=link}
12.7 KB
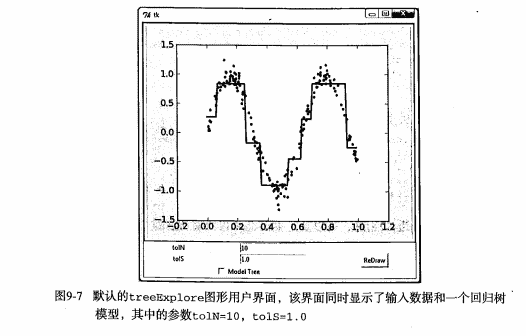
docs/ml/img/GUI示例图.png
0 → 100644
{kind=link}
10.1 KB
docs/ml/img/K-Means_首页.jpg
0 → 100644
{kind=link}

96.2 KB
docs/ml/img/LR_1.png
0 → 100644
{kind=link}
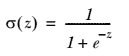
555 字节
docs/ml/img/LR_10.png
0 → 100644
{kind=link}
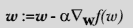
598 字节
docs/ml/img/LR_11.png
0 → 100644
{kind=link}
7.7 KB
docs/ml/img/LR_12.png
0 → 100644
{kind=link}
6.1 KB
docs/ml/img/LR_13.png
0 → 100644
{kind=link}

3.8 KB
docs/ml/img/LR_14.png
0 → 100644
{kind=link}

1.0 KB
docs/ml/img/LR_15.png
0 → 100644
{kind=link}
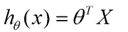
634 字节
docs/ml/img/LR_16.png
0 → 100644
{kind=link}
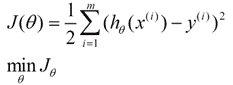
1.4 KB
docs/ml/img/LR_17.png
0 → 100644
{kind=link}

3.9 KB
docs/ml/img/LR_18.png
0 → 100644
{kind=link}
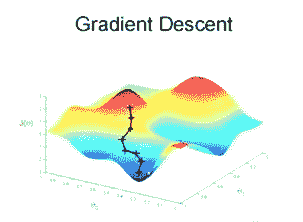
3.3 KB
docs/ml/img/LR_19.png
0 → 100644
{kind=link}
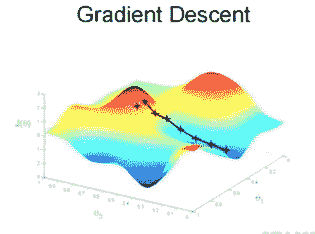
4.1 KB
docs/ml/img/LR_2.png
0 → 100644
{kind=link}
665 字节
docs/ml/img/LR_20.png
0 → 100644
{kind=link}
11.6 KB
docs/ml/img/LR_21.png
0 → 100644
{kind=link}

112.3 KB
docs/ml/img/LR_3.png
0 → 100644
{kind=link}
8.2 KB
docs/ml/img/LR_4.png
0 → 100644
{kind=link}

313 字节
docs/ml/img/LR_5.png
0 → 100644
{kind=link}
1.2 KB
docs/ml/img/LR_6.png
0 → 100644
{kind=link}
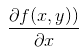
533 字节
docs/ml/img/LR_7.png
0 → 100644
{kind=link}
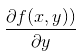
548 字节
docs/ml/img/LR_8.png
0 → 100644
{kind=link}
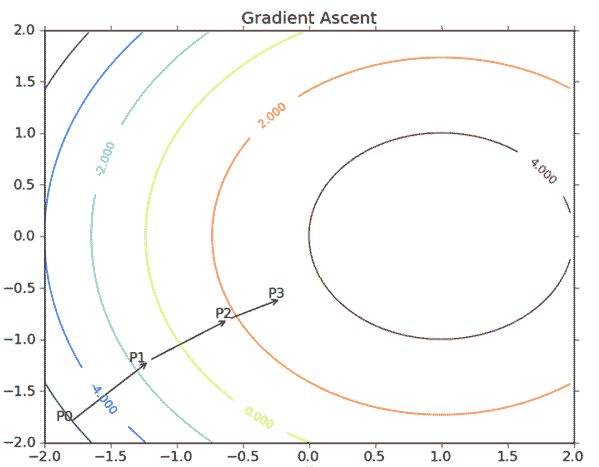
9.3 KB
docs/ml/img/LR_9.png
0 → 100644
{kind=link}
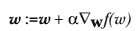
605 字节
docs/ml/img/LinearR_1.png
0 → 100644
{kind=link}
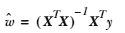
513 字节
docs/ml/img/LinearR_10.png
0 → 100644
{kind=link}
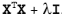
344 字节
docs/ml/img/LinearR_11.png
0 → 100644
{kind=link}
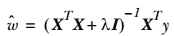
775 字节
docs/ml/img/LinearR_12.png
0 → 100644
{kind=link}
3.6 KB
docs/ml/img/LinearR_13.png
0 → 100644
{kind=link}
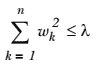
591 字节
docs/ml/img/LinearR_14.png
0 → 100644
{kind=link}
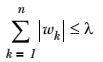
574 字节
docs/ml/img/LinearR_15.png
0 → 100644
{kind=link}
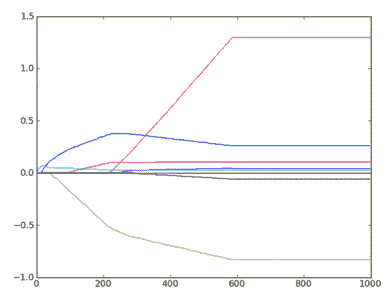
2.5 KB
docs/ml/img/LinearR_16.png
0 → 100644
{kind=link}
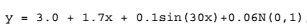
751 字节
docs/ml/img/LinearR_17.png
0 → 100644
{kind=link}

4.3 KB
docs/ml/img/LinearR_18.png
0 → 100644
{kind=link}
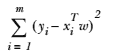
620 字节
docs/ml/img/LinearR_19.png
0 → 100644
{kind=link}
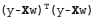
384 字节
docs/ml/img/LinearR_2.png
0 → 100644
{kind=link}
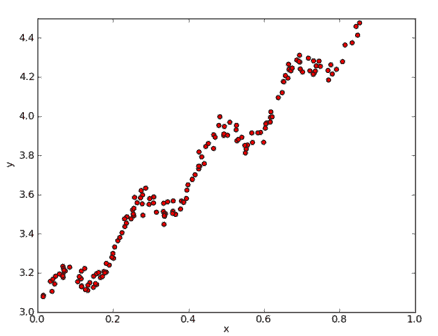
3.9 KB
docs/ml/img/LinearR_20.png
0 → 100644
{kind=link}
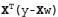
343 字节
docs/ml/img/LinearR_21.png
0 → 100644
{kind=link}
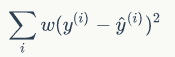
806 字节
docs/ml/img/LinearR_22.png
0 → 100644
{kind=link}

16.2 KB
docs/ml/img/LinearR_23.png
0 → 100644
{kind=link}
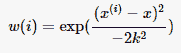
698 字节
docs/ml/img/LinearR_3.png
0 → 100644
{kind=link}
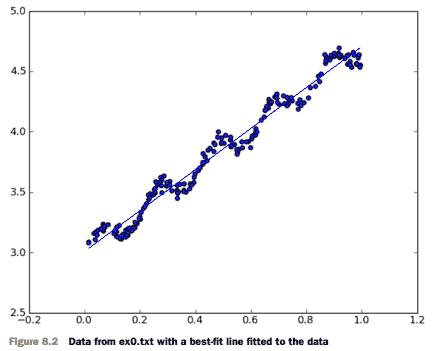
4.5 KB
docs/ml/img/LinearR_4.png
0 → 100644
{kind=link}
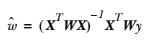
662 字节
docs/ml/img/LinearR_5.png
0 → 100644
{kind=link}
871 字节
docs/ml/img/LinearR_6.png
0 → 100644
{kind=link}
5.6 KB
docs/ml/img/LinearR_7.png
0 → 100644
{kind=link}
6.5 KB
docs/ml/img/LinearR_8.png
0 → 100644
{kind=link}
334 字节
docs/ml/img/LinearR_9.png
0 → 100644
{kind=link}
253 字节
{kind=link}

97.8 KB
{kind=link}
7.4 KB
docs/ml/img/Logistic回归首页.png
0 → 100644
{kind=link}

96.2 KB
docs/ml/img/Matplotlib绘制树形图.png
0 → 100644
{kind=link}
6.0 KB
docs/ml/img/NB_2.png
0 → 100644
{kind=link}

3.9 KB
docs/ml/img/NB_3.png
0 → 100644
{kind=link}

2.3 KB
docs/ml/img/NB_4.png
0 → 100644
{kind=link}
774 字节
docs/ml/img/NB_5.png
0 → 100644
{kind=link}
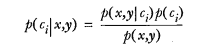
1012 字节
docs/ml/img/NB_6.png
0 → 100644
{kind=link}
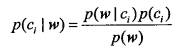
977 字节
docs/ml/img/NB_7.png
0 → 100644
{kind=link}
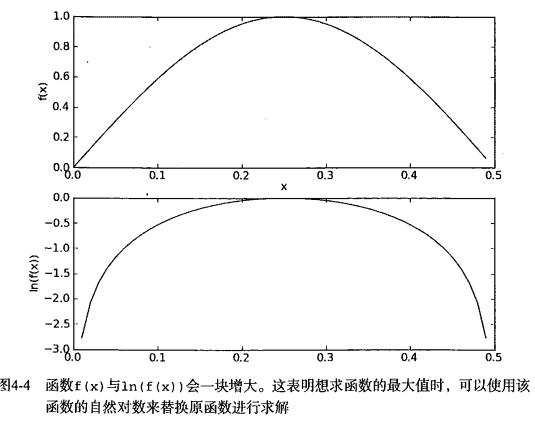
9.1 KB
{kind=link}

98.7 KB
docs/ml/img/PCA分析数据过程.jpg
0 → 100644
{kind=link}

46.2 KB
docs/ml/img/ROC曲线.png
0 → 100644
{kind=link}
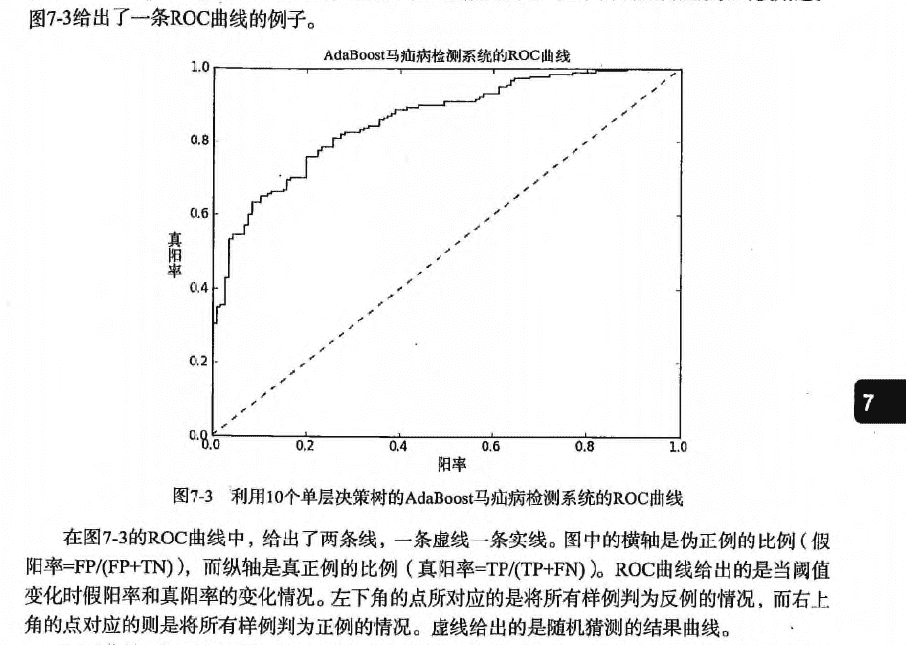
66.1 KB
docs/ml/img/RegTree_1.png
0 → 100644
{kind=link}
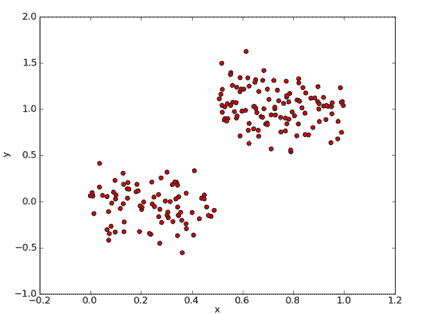
4.4 KB
docs/ml/img/RegTree_2.png
0 → 100644
{kind=link}
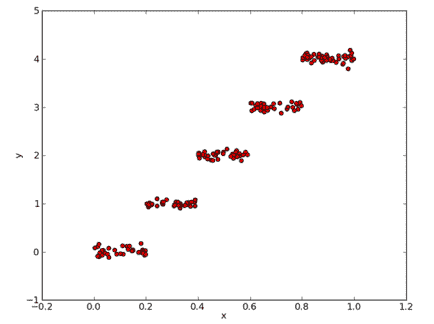
2.8 KB
docs/ml/img/RegTree_3.png
0 → 100644
{kind=link}
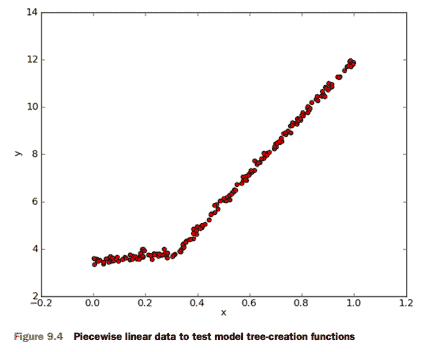
3.7 KB
docs/ml/img/RegTree_4.png
0 → 100644
{kind=link}
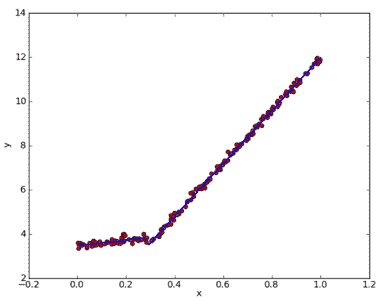
2.9 KB
docs/ml/img/RegTree_5.png
0 → 100644
{kind=link}
4.0 KB
docs/ml/img/SVD_推荐系统_主题空间案例1.jpg
0 → 100644
{kind=link}
38.5 KB
docs/ml/img/SVD公式的测试案例.jpg
0 → 100644
{kind=link}

5.1 KB
docs/ml/img/SVM_1.jpg
0 → 100644
{kind=link}

96.3 KB
{kind=link}
54.1 KB
{kind=link}
30.1 KB
{kind=link}
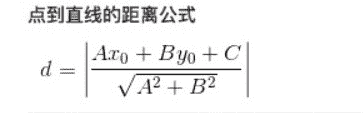
3.3 KB
{kind=link}

37.8 KB
{kind=link}

27.1 KB
{kind=link}

68.2 KB
docs/ml/img/SVM_松弛变量.jpg
0 → 100644
{kind=link}
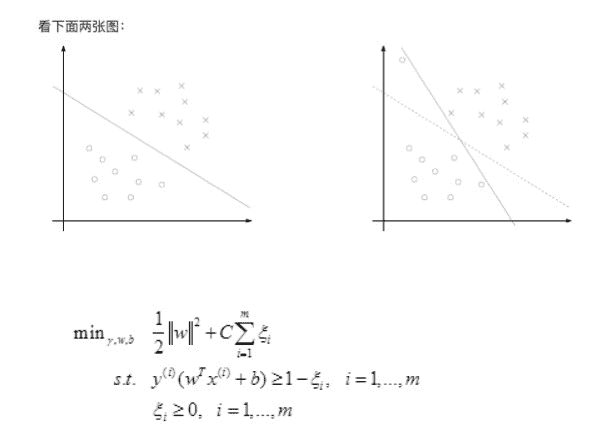
7.0 KB
docs/ml/img/Thumbs.db
0 → 100644
文件已添加
{kind=link}

98.0 KB
docs/ml/img/adaboost_alpha.png
0 → 100644
{kind=link}

58.4 KB
{kind=link}
此差异已折叠。
docs/ml/img/adaboost_headPage.jpg
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/ml/img/alpha.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/ml/img/arctan_arccot.gif
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/b.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_1.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_10.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_2.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_5.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_6.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_7.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_8.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/hu_9.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_1.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_10.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_11.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_12.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_13.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_14.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_15.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_16.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_2.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_3.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_4.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_5.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_6.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_7.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_8.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/k_9.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn-0-headpage.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn-1-movie.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_2.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_2_handWriting.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_headPage_xy.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_later_1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_later_2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_later_3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_later_4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/knn_matplotlib_2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/ml_add_1.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/ml_add_2.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/ml_algorithm.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/ml_map.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/mr_1_cluster.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/mr_headPage.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_5.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_6.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_7.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/story_8.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/supportVector.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/supportVector公式.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/svd_headPage.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/svm_2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/w.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/交易清单.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/代价函数.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/使用SVD简化数据-LSI举例.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/使用SVD简化数据-SVD公式.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/使用SVD简化数据-基于物品相似度.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/使用SVD简化数据-基于用户相似度.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/决策树-流程图.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/决策树划分数据集时的数据路径.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/决策树流程介绍图.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/利用PCA简化数据_首页.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/基于SVD.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/基于物品相似度.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/基于知识的推荐.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/局部加权线性回归效果图.png
0 → 100644
{kind=link}
此差异已折叠。
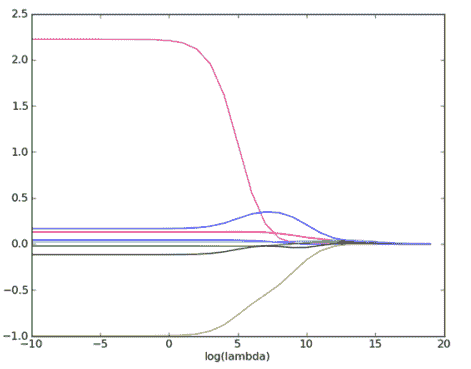
docs/ml/img/岭回归示例图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/应用PCA降维.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/所有可能的项集组合.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/拟合程度示例图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/拟合程度较好示例图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/推荐方法对比.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/数据重抽样.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/方向导数和梯度.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/朴素贝叶斯_首页.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/朴素贝叶斯示例数据分布.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/机器学习基础-选择算法.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/机器学习基础-首页.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/机器学习基础训练过程.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/松弛变量.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/树回归首页.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/梯度上升算法.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/模型树示例图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/欠拟合示例图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/欧式距离的计算方式.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/步骤1-3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/步骤4-5.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/步骤6-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/步骤6-2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/步骤7-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/步骤7-2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/测试回归树的分段常数数据集.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/熵的计算公式.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/特征重抽样.jpg
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
docs/ml/img/线性回归效果图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/贝叶斯条件概率.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/过拟合.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/过拟合图解.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/过拟合示例图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/逐步线性回归示例图.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/非频繁项集.png
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/项目数据导入.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/ml/img/预测数值型数据回归首页.png
0 → 100644
{kind=link}
此差异已折叠。