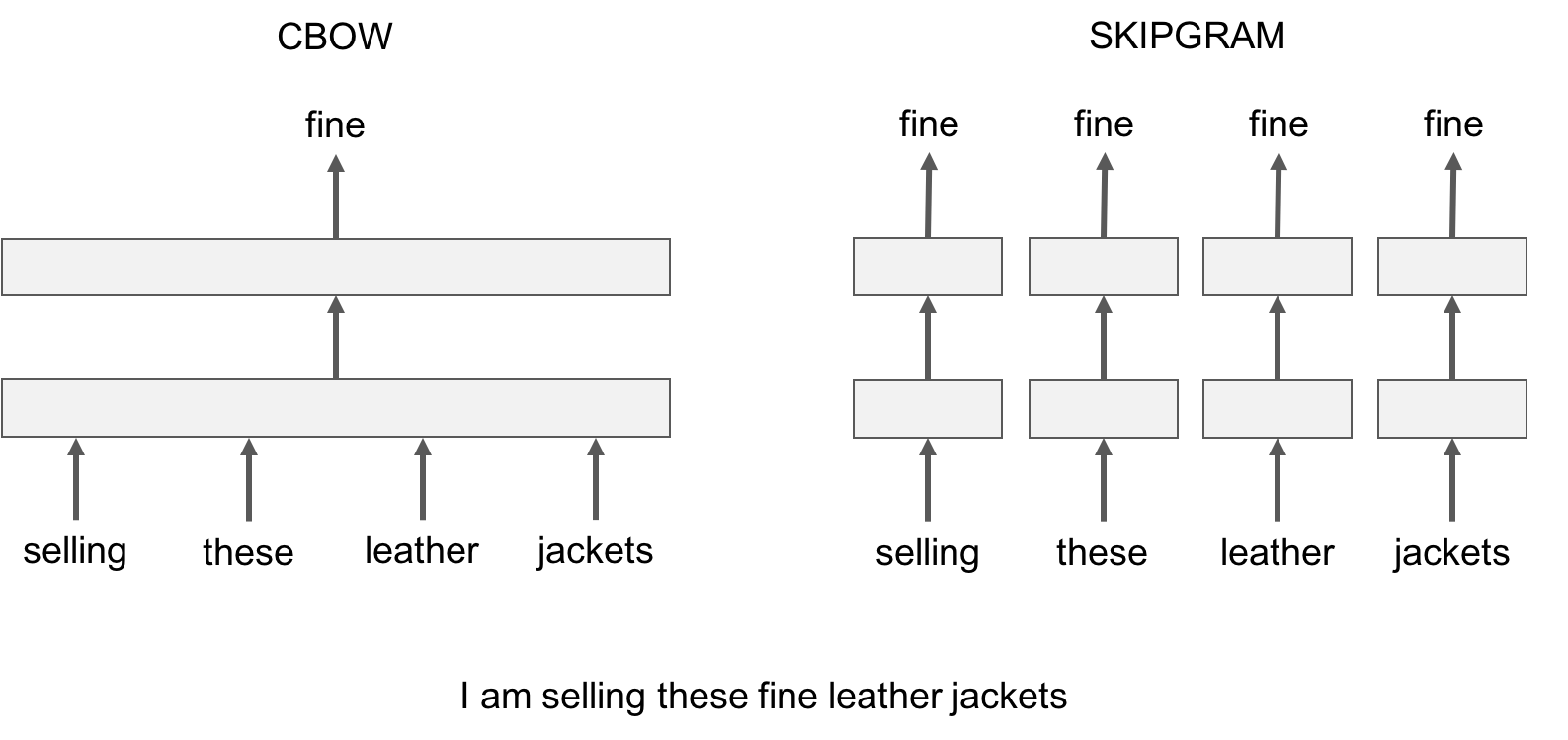
让我们用一个例子来说明这种差异:给出句子*'Poets have been mysteriously silent on the subject of cheese'*和目标单词'*silent*',skipgram 模型随机取近邻词尝试预测目标词,如'*subject*'或'*mysteriously*'。cbow模型使用目标单词固定数量的左边和右边单词,,如{*been*, *mysteriously*, *on*, *the*},并使用它们的向量和来预测目标单词。下图用另一个例子总结了这种差异。
让我们用一个例子来说明这种差异:给出句子*'Poets have been mysteriously silent on the subject of cheese'* 和目标单词 '*silent*',skipgram 模型随机取近邻词尝试预测目标词,如 '*subject*'或'*mysteriously*'。cbow 模型使用目标单词固定数量的左边和右边单词,,如 {*been*, *mysteriously*, *on*, *the*},并使用它们的向量和来预测目标单词。下图用另一个例子总结了这种差异。