第8章开头
Showing
image/chapter8/8-1.png
0 → 100644
{kind=link}

14.7 KB
image/chapter8/8-10.png
0 → 100644
{kind=link}
114.8 KB
image/chapter8/8-11.png
0 → 100644
{kind=link}
202.3 KB
image/chapter8/8-12.png
0 → 100644
{kind=link}
173.9 KB
image/chapter8/8-13.png
0 → 100644
{kind=link}
93.9 KB
image/chapter8/8-14.png
0 → 100644
{kind=link}

251.7 KB
image/chapter8/8-15.png
0 → 100644
{kind=link}
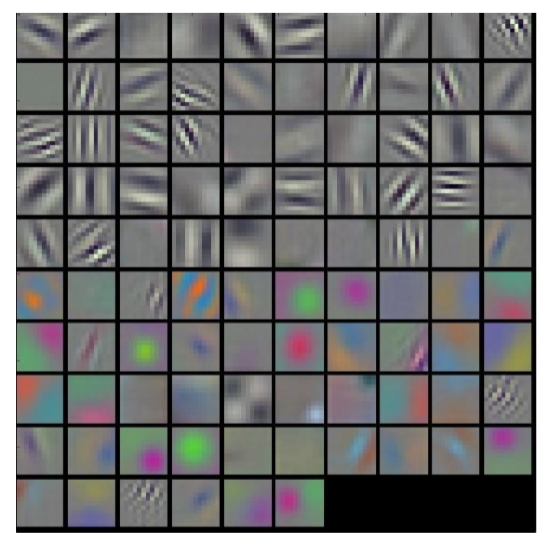
281.0 KB
image/chapter8/8-16.png
0 → 100644
{kind=link}

250.7 KB
image/chapter8/8-2.png
0 → 100644
{kind=link}
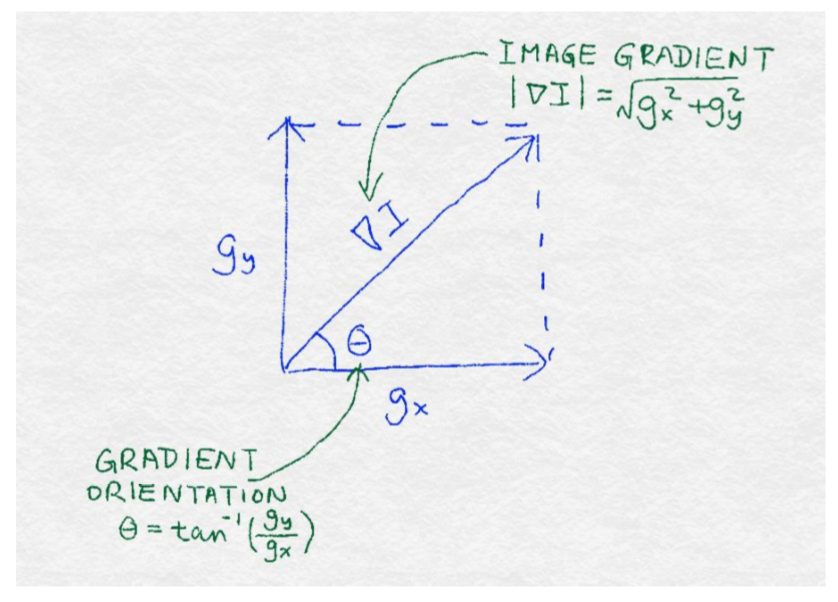
394.6 KB
image/chapter8/8-3.png
0 → 100644
{kind=link}
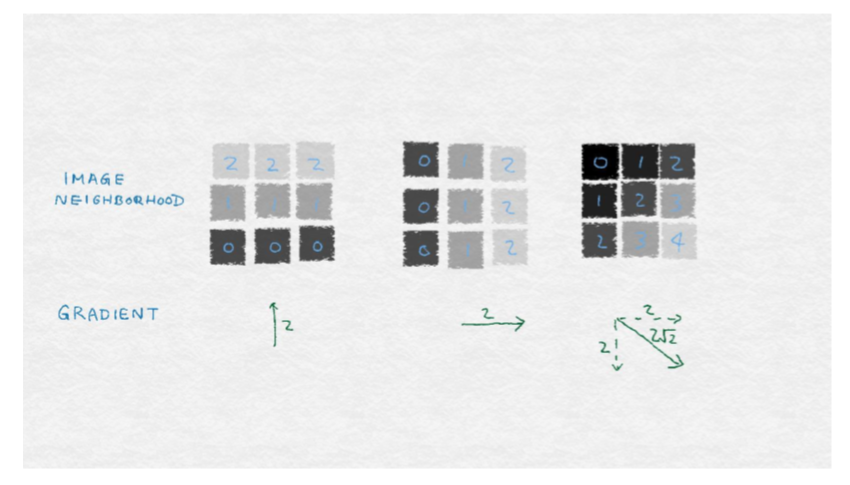
238.1 KB
image/chapter8/8-4.png
0 → 100644
{kind=link}

80.9 KB
image/chapter8/8-5.png
0 → 100644
{kind=link}
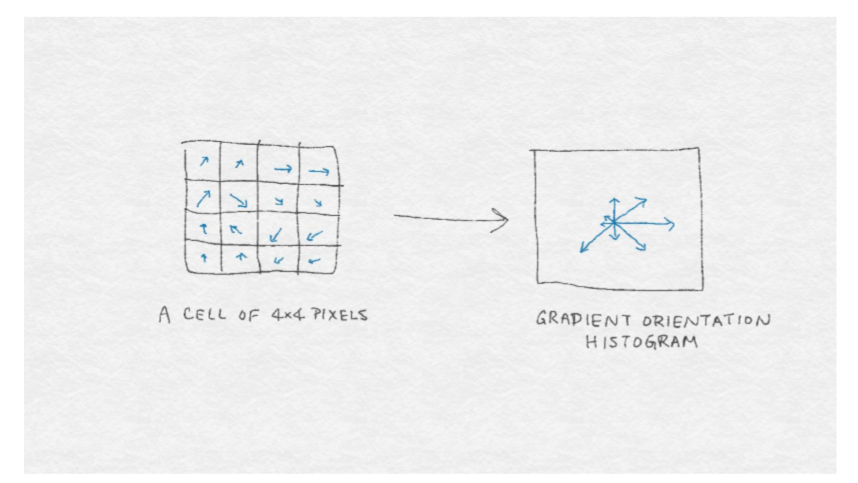
228.8 KB
image/chapter8/8-6.png
0 → 100644
{kind=link}
316.2 KB
image/chapter8/8-7.png
0 → 100644
{kind=link}
310.3 KB
image/chapter8/8-8.png
0 → 100644
{kind=link}
329.7 KB
image/chapter8/8-9.png
0 → 100644
{kind=link}
215.3 KB