ch6 pic
Showing
{kind=link}
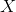
152 字节
{kind=link}
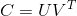
333 字节
{kind=link}
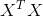
247 字节
{kind=link}
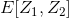
407 字节
{kind=link}
305 字节
{kind=link}
580 字节
{kind=link}
806 字节
{kind=link}
330 字节
{kind=link}
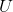
146 字节
{kind=link}
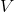
142 字节
{kind=link}
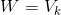
291 字节
{kind=link}
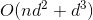
500 字节
{kind=link}

152 字节
{kind=link}
137 字节
{kind=link}
432 字节
{kind=link}
799 字节
{kind=link}
191 字节
{kind=link}
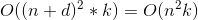
840 字节
{kind=link}
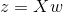
267 字节
{kind=link}
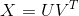
347 字节
{kind=link}
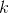
133 字节
{kind=link}
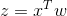
285 字节
{kind=link}

43 字节
{kind=link}
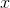
124 字节
{kind=link}

120 字节
{kind=link}
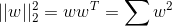
698 字节
{kind=link}
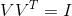
293 字节
{kind=link}

43 字节
{kind=link}
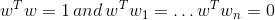
823 字节
{kind=link}
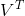
186 字节
{kind=link}
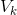
176 字节
{kind=link}
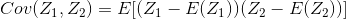
1.3 KB
{kind=link}
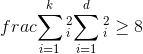
971 字节
{kind=link}
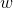
138 字节
{kind=link}
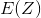
298 字节
{kind=link}

117 字节