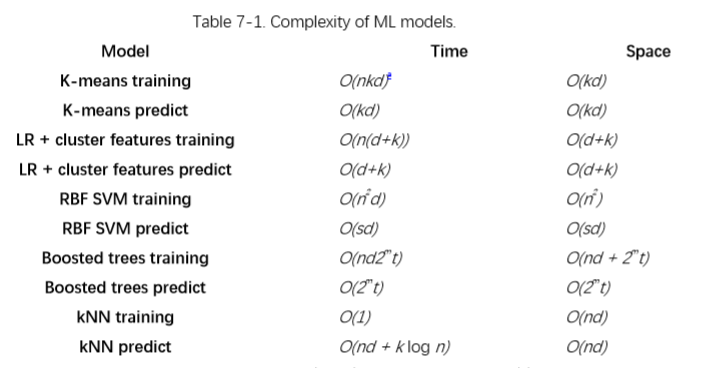
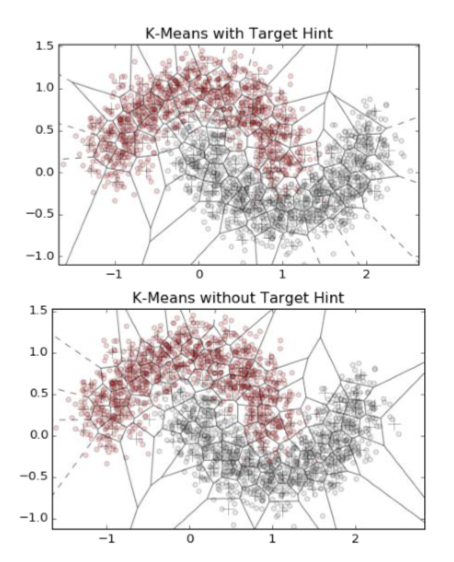
"""Transforms numeric data into k-means cluster memberships.
This transformer runs k-means on the input data and converts each data point into the id of the closest cluster. If a target variable is present, it is scaled and included as input to k-means in order to derive clusters that obey the classification boundary as well as group similar points together. """
{kind=link}
{kind=link}
{kind=link}