Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
hands-on-ml-zh
提交
93bdc811
H
hands-on-ml-zh
项目概览
OpenDocCN
/
hands-on-ml-zh
通知
13
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
H
hands-on-ml-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
93bdc811
编写于
4月 19, 2018
作者:
F
friedhelm
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
1
上级
4bff959e
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
78 addition
and
0 deletion
+78
-0
docs/7.集成学习与随机森林.md
docs/7.集成学习与随机森林.md
+78
-0
images/chapter_7/7-4.png
images/chapter_7/7-4.png
+0
-0
images/chapter_7/7-5.png
images/chapter_7/7-5.png
+0
-0
未找到文件。
docs/7.集成学习与随机森林.md
浏览文件 @
93bdc811
...
...
@@ -61,3 +61,80 @@ VotingClassifier 0.896
## Bagging 和 Pasting
换句话说,Bagging 和 Pasting 都允许在多个分类器间对训练集进行多次采样,但只有Bagging
就像之前降到的,可以通过使用不同的训练算法去得到一些不同的分类器。另一种方法就是对每一个分类器都使用相同的训练算法,但是在不同的训练集上去训练它们。有放回采样被称为
*Bagging*
(是
*bootstrap aggregating*
的缩写)。无放回采样称为粘贴
*pasting*
。
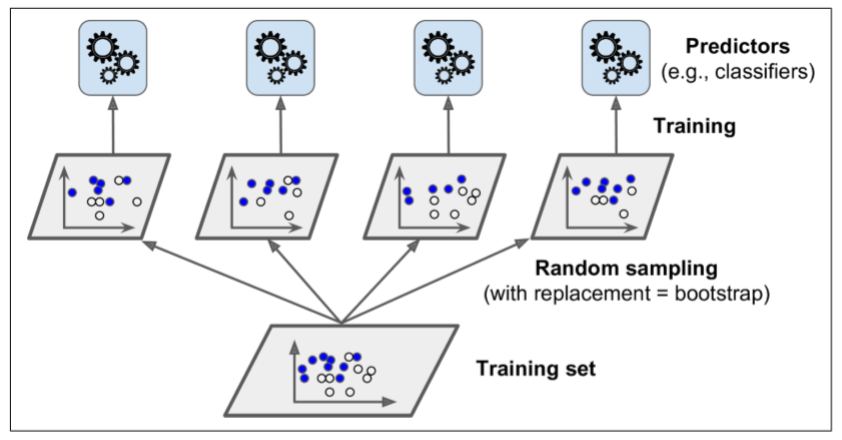
换句话说,Bagging 和 Pasting 都允许在多个分类器上对训练集进行多次采样,但只有Bagging允许对同一种分类器上对训练集进行进行多次采样。采样和训练过程如图7-4所示。

当所有的分类器被训练后,集成可以通过对所有分类器结果的简单聚合来对新的实例进行预测。聚合函数通常对分类是
*统计模式*
(例如硬投票分类器)或者对回归是平均。每一个单独的分类器在如果在原始训练集上都是高偏差,但是聚合降低了偏差和方差。通常情况下,集成的结果是有一个相似的偏差,但是对比与在原始训练集上的单一分类器来讲有更小的方差。
正如你在图7-4上所看到的,分类器可以通过不同的CPU核或其他的服务器一起被训练。相似的,分类器也可以一起被制作。这就是为什么Bagging 和 Pasting是如此流行的原因之一:它们的规模很好
## 在sklearn中的Bagging 和 Pasting
sklearn为Bagging 和 Pasting 提供了一个简单的API:
*BaggingClassifier*
类(或者对于回归可以是
*BaggingRegressor*
。接下来的代码训练了一个500个决策树分类器的集成,每一个都是在数据集上有放回采样100个训练实例下进行训练(这是Bagging的例子,如果你想尝试Pasting,就设置
*bootstrap=False*
)。
*n_jobs*
参数告诉sklearn用于训练和预测所需要CPU核的数量。(-1代表着sklearn会使用所有空闲核):
```
python
>>>
from
sklearn.ensemble
import
BaggingClassifier
>>>
from
sklearn.tree
import
DecisionTreeClassifier
>>>
bag_clf
=
BaggingClassifier
(
DecisionTreeClassifier
(),
n_estimators
=
500
,
>>>
max_samples
=
100
,
bootstrap
=
True
,
n_jobs
=-
1
)
>>>
bag_clf
.
fit
(
X_train
,
y_train
)
>>>
y_pred
=
bag_clf
.
predict
(
X_test
)
```
如果基分类器可以预测类别概率(例如它拥有
*predict_proba()*
方法),那么
*BaggingClassifier*
会自动的运行软投票,这是决策树分类器的情况。
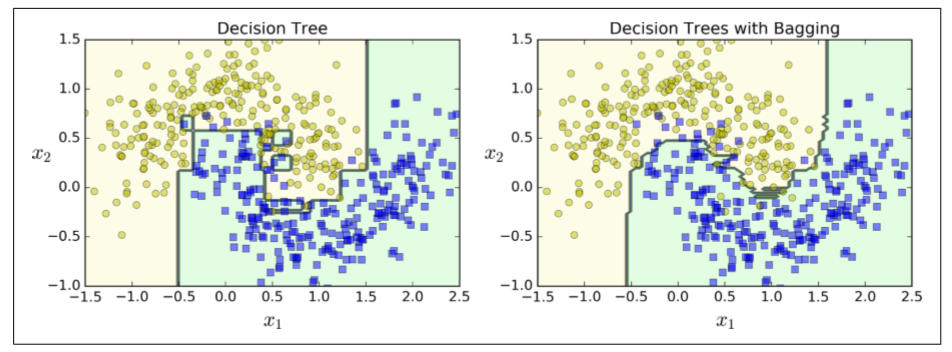
图7-5对比了单一决策树的决策边界和Bagging集成500个树的决策边界,两者都在moons数据集上训练。正如你所看到的,集成的分类比起单一决策树的分类产生情况更好:集成有一个可比较的偏差但是有一个较小的方差(它在训练集上的错误数目大致相同,但决策边界较不规则)。

Bootstrap在每个预测器被训练的子集中引入了更多的分集,所以Bagging结束时的偏差比Pasting更高,但这也意味着预测因子最终变得不相关,从而减少了集合的方差。总体而言,Bagging通常会导致更好的模型,这就解释了为什么它通常是首选的。然而,如果你有空闲时间和CPU功率,可以使用交叉验证来评估Bagging和Pasting哪一个更好。
## Out-of-Bag评价
对于Bagging来说,一些实例可能被一些分类器重复采样,但其他的有可能不会被采样。
*BaggingClassifier*
默认采样。
*BaggingClassifier*
默认是有放回的采样
*m*
个实例 (
*bootstrap=True*
),其中
*m*
是训练集的大小,这意味着平均下来只有63%的训练实例被每个分类器采样,剩下的37%个没有被采样的训练实例就叫做
*Out-of-Bag*
实例。注意对于每一个的分类器它们的37%不是相同的。
因为在训练中分类器从开没有看到过oob实例,所以它可以在这些实例上进行评估,而不需要单独的验证集或交叉验证。你可以拿出每一个分类器的 oob来评估集成本身。
在sklearn中,你可以在训练后需要创建一个
*BaggingClassifier*
来自动评估时设置
*oob_score=True*
来自动评估。接下来的代码展示了这个操作。评估结果通过变量
*oob_score_*
来显示:
```
python
>>>
bag_clf
=
BaggingClassifier
(
DecisionTreeClassifier
(),
n_estimators
=
500
,
bootstrap
=
True
,
n_jobs
=-
1
,
oob_score
=
True
)
>>>
bag_clf
.
fit
(
X_train
,
y_train
)
>>>
bag_clf
.
oob_score_
0.93066666666666664
```
根据这个 obb评估,
*BaggingClassifier*
可以再测试集上达到93.1%的准确率,让我们修改一下:
```
python
>>>
from
sklearn.metrics
import
accuracy_score
>>>
y_pred
=
bag_clf
.
predict
(
X_test
)
>>>
accuracy_score
(
y_test
,
y_pred
)
0.93600000000000005
```
我们在测试集上得到了93.6%的准确率,足够接近了!
对于每个训练实例oob决策函数也可通过
*oob_decision_function_*
变量来展示。在这种情况下(当基决策器有
*pre dict_proba()*
时)决策函数会对每个训练实例返回类别概率。例如,oob评估预测第二个训练实例有60.6%的概率属于正类(39.4%属于负类):
```
python
>>>
bag_clf
.
oob_decision_function_
array
([[
0.
,
1.
],
[
0.60588235
,
0.39411765
],[
1.
,
0.
],
...
[
1.
,
0.
],[
0.
,
1.
],[
0.48958333
,
0.51041667
]])
```
## 随机贴片与随机子空间
```
python
>>>
from
sklearn.ensemble
import
BaggingClassifier
>>>
from
sklearn.tree
import
DecisionTreeClassifier
>>>
bag_clf
=
BaggingClassifier
(
DecisionTreeClassifier
(),
n_estimators
=
500
,
>>>
max_samples
=
100
,
bootstrap
=
True
,
n_jobs
=-
1
)
>>>
bag_clf
.
fit
(
X_train
,
y_train
)
>>>
y_pred
=
bag_clf
.
predict
(
X_test
)
```

\ No newline at end of file
images/chapter_7/7-4.png
0 → 100644
浏览文件 @
93bdc811
93.9 KB
images/chapter_7/7-5.png
0 → 100644
浏览文件 @
93bdc811
183.0 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}