ch14 pic
Showing
images/chapter_14/14-1.png
0 → 100644
{kind=link}
74.4 KB
images/chapter_14/14-2.png
0 → 100644
{kind=link}
114.6 KB
images/chapter_14/14-3.png
0 → 100644
{kind=link}
53.9 KB
images/chapter_14/14-4.png
0 → 100644
{kind=link}
169.3 KB
images/chapter_14/14-5.png
0 → 100644
{kind=link}
78.3 KB
images/chapter_14/14-6.png
0 → 100644
{kind=link}
45.8 KB
images/chapter_14/14-7.png
0 → 100644
{kind=link}
102.1 KB
images/chapter_14/14-8.png
0 → 100644
{kind=link}
86.8 KB
images/chapter_14/e-14-1.png
0 → 100644
{kind=link}
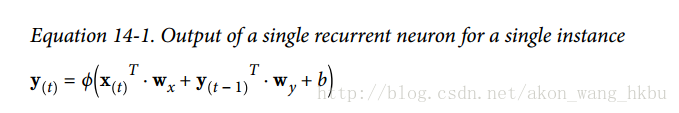
20.8 KB
images/chapter_14/e-14-2.png
0 → 100644
{kind=link}

32.3 KB
images/chapter_14/o-14-1.png
0 → 100644
{kind=link}
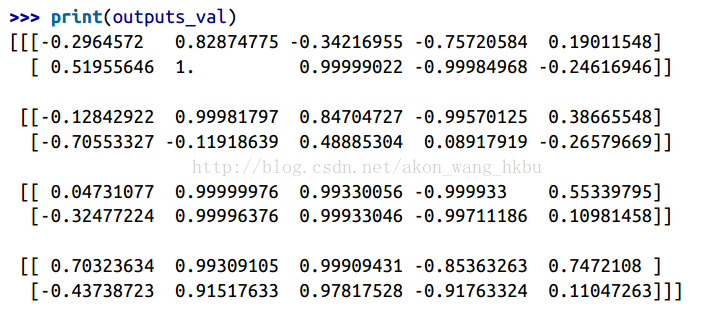
71.5 KB
images/chapter_14/o-14-2.png
0 → 100644
{kind=link}
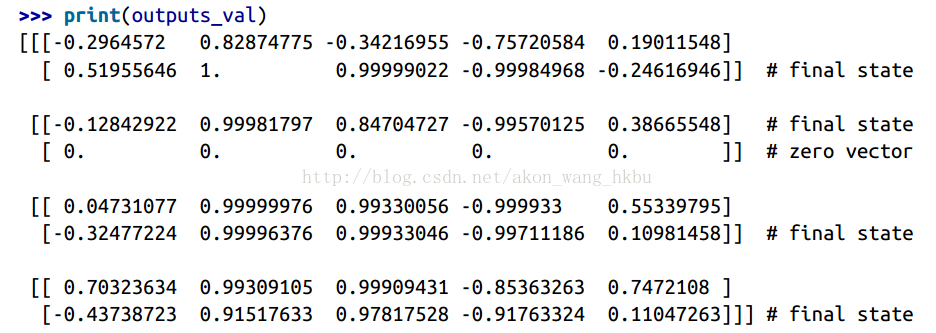
77.9 KB
images/chapter_14/o-14-3.png
0 → 100644
{kind=link}

44.1 KB
images/chapter_14/o-14-4.png
0 → 100644
{kind=link}
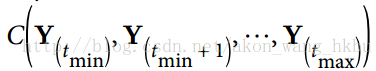
11.5 KB
images/chapter_14/o-14-5.png
0 → 100644
{kind=link}
31.6 KB
images/chapter_14/o-14-6.png
0 → 100644
{kind=link}
59.0 KB