Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
interpretable-ml-book-zh
提交
8e2b9d11
I
interpretable-ml-book-zh
项目概览
OpenDocCN
/
interpretable-ml-book-zh
通知
3
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
I
interpretable-ml-book-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
8e2b9d11
编写于
8月 14, 2019
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'master' of
https://github.com/apachecn/interpretable-ml-book-zh
上级
e6611ac2
e804f82d
变更
3
展开全部
隐藏空白更改
内联
并排
Showing
3 changed file
with
119 addition
and
126 deletion
+119
-126
docs/0.md
docs/0.md
+2
-0
docs/1.md
docs/1.md
+32
-22
docs/2.md
docs/2.md
+85
-104
未找到文件。
docs/0.md
浏览文件 @
8e2b9d11
...
...
@@ -8,6 +8,8 @@
## 前言

机器学习对于改进产品、过程和研究有很大的潜力。但是
**计算机通常不能解释他们的预测**
,这是机器学习的一个障碍。这本书是关于使机器学习模型和它们的决策可解释。
在探索了可解释性的概念之后,您将学习简单的、
**可解释的模型**
,如决策树、决策规则和线性回归。后面几章重点介绍了
**解释黑箱模型**
的一般模型不可知论方法,如特征重要性和累积局部效应,以及用沙普利值(Shapley) 和 LIME 解释个别预测。
...
...
docs/1.md
浏览文件 @
8e2b9d11
...
...
@@ -26,6 +26,8 @@ $^1$ 弗里德曼、杰罗姆、特雷弗·黑斯迪和罗伯特·提比西拉
### 2030年:瑞士医学实验室

“这绝对不是最糟糕的死法!“汤姆总结了一下,试图在负面的事情中找到一些正面的东西。他从静脉输液管上取下了泵。
“他是因为错误而死的,”莉娜补充说。
“当然是用错了吗啡泵!为我们增大了工作量!“汤姆一边抱怨一边拧下泵的后板。拆下所有的螺丝后,他把盘子举起放在一边。他把电缆插入诊断端口。
...
...
@@ -59,6 +61,8 @@ $^1$ 弗里德曼、杰罗姆、特雷弗·黑斯迪和罗伯特·提比西拉
### 2050年:新加坡的地铁站

她赶到璧山地铁站。按照她的想法,她已经在工作了。新的神经架构的测试现在应该已经完成了。她领导重新设计了政府的“个人实体纳税亲和力预测系统”,该系统预测一个人是否会向税务局隐瞒资金。她的团队想出了一个优雅的想法。如果成功,该系统不仅可以为税务局服务,还可以提供给其他系统,如反恐警报系统和商业登记处。有一天,政府甚至可以将这些预测纳入公民信任评分。公民信任评分评估一个人的可信度。这个估计会影响到每个人日常生活的每一部分,比如贷款或者要等多久才能拿到新护照。当她走下扶梯时,她想象着她的团队系统与公民信任评分系统的整合会是怎样的。
她经常在不降低行走速度的情况下用手擦拭 RFID 阅读器。她的思绪被占据了,但是感官期望和现实的不一致在她的大脑中敲响了警钟。
...
...
@@ -85,6 +89,8 @@ $^1$ 弗里德曼、杰罗姆、特雷弗·黑斯迪和罗伯特·提比西拉
### 612年(火星定居后):火星博物馆
![img]I(https://christophm.github.io/interpretable-ml-book/images/burnt-earth.jpg)
“历史很无聊,”Xola 低声对她的朋友说。Xola,一个蓝头发的女孩,正懒洋洋地用左手追着一架投影仪在房间里嗡嗡作响。“历史很重要,”老师看着女孩们,用一种沮丧的声音说。Xola 脸红了。她没想到老师会听到了她说话。
“Xola,你刚学到了什么?”老师问她。“古人用尽了地球上所有的资源,然后死了?“她仔细地问。“不,他们让气候变热,不是人,而是电脑和机器。“这是行星地球,而不是地球行星,”另一个叫林·塞拉的女孩点头表示同意。带着一丝骄傲,老师微笑着点了点头。“你们都是对的。你知道为什么会这样吗?因为人们目光短浅,贪婪?“Xola问。“人们无法停止他们的机器!”林脱口而出。
...
...
@@ -127,55 +133,59 @@ $^1$ 弗里德曼、杰罗姆、特雷弗·黑斯迪和罗伯特·提比西拉
*拥抱熵。*
“黑暗的记忆,”老师说,打破了房间里的沉默。“它将上载到你的图书馆中。你的家庭作业下个星期交。”Xola
叹了口气。她设法抓住了一只小无人机。无人机从中央处理器和引擎发出的声音很温暖。Xola
喜欢它温暖她的手。
“黑暗的记忆,”老师说,打破了房间里的沉默。“它将上载到你的图书馆中。你的家庭作业下个星期交。”Xola
叹了口气。她设法抓住了一只小无人机。无人机从中央处理器和引擎发出的声音很温暖。Xola
喜欢它温暖她的手。
## 1.2 什么是机器学习?
机器学习是计算机用来根据数据作出和改进预测或行为的一套方法。
例如,为了预测房屋的价值,计算机将从过去的房屋销售中学习模式。这本书
集中在监督机器学习上,它涵盖了所有的预测问题,其中我们有一个数据集,我们已经知道感兴趣的结果(如过去的房价),并希望学习预测新数据的结果。例如,从监督学习中排除的是群集任务(=无监督学习),在这些任务中,我们没有感兴趣的特定结果,但希望找到数据点的群集。此外,诸如强化学习之类的事情也被排除在外,在这种情况下,代理通过在一个环境中(如玩俄罗斯方块的计算机)的行为来学习优化某种奖励。监督学习的目标是学习一个预测模型,将数据特征(如房屋大小、位置、楼层类型等)映射到输出(如房价)。如果输出是分类的,则任务称为分类,如果输出是数值的,则称为回归。机器学习算法通过估计参数(如权重)或学习结构(如树)来学习模型。该算法由一个最小化的分数或损失函数指导。在房屋价值示例中,机器将估计房屋价格和预测价格之间的差额
最小化。然后,可以使用经过充分训练的机器学习模型来预测新实例。
例如,为了预测房屋的价值,计算机将从过去的房屋销售中学习模式。这本书
关注点在监督机器学习上,它涵盖了所有的预测问题,其中我们有一个数据集,我们已经知道感兴趣的结果(如过去的房价),并希望学习预测新数据的结果。例如,聚类任务(=无监督学习)就不在监督学习范畴中,在这些任务中,我们没有特定关注的结果,但希望找到数据点的簇(中心点)。此外,诸如强化学习之类的事情也被排除,在这种情况下,智能体通过在一个环境中(如玩俄罗斯方块的计算机)的行为来学习优化某种奖励。监督学习的目标是学习一个预测模型,将数据特征(如房屋大小、位置、楼层类型等)映射到输出(如房价)。如果输出是类别,则任务称为分类,如果输出是数值,则称为回归。机器学习算法通过估计参数(如权重)或学习结构(如树)来学习模型。该算法由一个最小化的分数或损失函数指导。在房屋价值示例中,机器将估计房屋价格和预测价格之间的差值进行
最小化。然后,可以使用经过充分训练的机器学习模型来预测新实例。
房价估算、产品推荐、路标检测、信用违约预测和欺诈检测:所有这些例子都有共同点,可以通过机器学习来解决。任务不同,但方法相同:
第一步:数据采集。越多越好。数据必须包含要预测的结果以及要从中进行预测的其他信息。对于街道标志检测器(“图像中有街道标志吗?
”“),您将收集街道图像并标记街道标志是否可见。对于信用违约预测者,您需要实际贷款的过去
数据、客户是否拖欠贷款的信息以及有助于您做出预测的数据,例如收入、过去信用违约等。对于自动房屋价值评估程序,您可以从过去的房屋销售中收集数据和有关房地产的信息,如大小、位置等。
第一步:数据采集。越多越好。数据必须包含要预测的结果以及要从中进行预测的其他信息。对于街道标志检测器(“图像中有街道标志吗?
“),您将收集街道图像并标记是否存在街道标志。对于信用违约的预测,您需要过去实际贷款的
数据、客户是否拖欠贷款的信息以及有助于您做出预测的数据,例如收入、过去信用违约等。对于自动房屋价值评估程序,您可以从过去的房屋销售中收集数据和有关房地产的信息,如大小、位置等。
第二步:将这些信息输入机器学习算法,生成信号检测器模型、信用评级模型或房屋价值估计器。
步骤3:将模型与新数据一起使用。将模型集成到产品或流程中,例如自动驾驶汽车、信贷申请流程或房地产市场网站。
第三步:将新数据输入模型。将模型集成到产品或流程中,例如自动驾驶汽车、信贷申请流程或房地产市场网站。
机器在许多任务上都超过人类,例如下棋(或最近的Go)或天气预测。即使机器和人一样好,或者在任务上略微逊色,在速度、再现性和缩放方面仍然有很大的优势。一个一旦实现的机器学习模型可以比人类更快地完成一项任务,可靠地提供一致的结果,并且可以无限地复制。在另一台机器上复制机器学习模型既快又廉价。训练一个人完成一项任务可能需要几十年(尤其是当他们年轻时),而且成本很高。使用机器学习的一个主要缺点是,关于数据和机器解决的任务的思路被隐藏在愈加复杂的模型中。你需要数以百万计的参数来描述一个深层的神经网络,而没有办法完全理解这个模型。其他模型,如随机森林,由数百个决策树组成,它们“投票”预测。为了理解这个决定是如何做出的,你必须查看数百棵树中每棵树的投票和结构。不管你有多聪明或者你的记忆能力有多好,这都是行不通的。即使每个模型都可以被解释,但性能最好的模型通常是无法解释的多个模型(也称为集合)的集成。如果只关注性能,您将自动获得越来越多不透明的模型。只需看一看
[
Kaggle.com
](
http://blog.kaggle.com/
)
机器学习竞赛平台对获胜者的采访:胜出的模型大多是模型的集成,或是非常复杂的模型,如集成树或深层神经网络。
## 1.3 术语
机器在许多任务上都超过人类,例如下棋(或最近的下棋)或预测天气。即使机器和人一样好,或者在任务上有点差,在速度、再现性和缩放方面仍然有很大的优势。一个一旦实现的机器学习模型可以比人类更快地完成一项任务,可靠地提供一致的结果,并且可以无限地复制。在另一台机器上复制机器学习模型既快又便宜。训练一个人完成一项任务可能需要几十年(尤其是当他们年轻时),而且代价很高。使用机器学习的一个主要缺点是,机器解决的数据和任务的见解隐藏在越来越复杂的模型中。你需要数以百万计的数字来描述一个深层的神经网络,而没有办法完全理解这个模型。其他模型,如随机森林,由数百个决策树组成,它们“投票”预测。为了理解这个决定是如何做出的,你必须查看数百棵树中每一棵树的投票和结构。不管你有多聪明或者你的工作记忆有多好,这都是行不通的。即使每个模型都可以被解释,但性能最好的模型通常是无法解释的多个模型(也称为集合)的混合。如果只关注性能,您将自动获得越来越多不透明的模型。看一看:胜出的模型大多是模型的集合,或是非常复杂的模型,如增强树或深层神经网络。
为避免歧义引起混淆,本书中使用的术语定义如下:
1.
3术语
**算法**
是机器为达到特定目标
[
$^2$
](
https://christophm.github.io/interpretable-ml-book/#fn2%20class=
)
而遵循的一组规则。可以将算法视为定义输入、输出以及从输入到输出所需的所有步骤的说明。烹饪食谱是一种算法,其中成分是输入,熟食是输出,准备和烹饪步骤是算法指令。
为避免歧义造成混淆,本书中使用的术语定义如下:
**机器学习**
是一套方法,允许计算机从数据中学习,以做出和改进预测(例如癌症、每周销售、信用违约)。机器学习是从“正常编程”到“间接编程”的一种范式转换,所有指令都必须明确地提供给计算机,而“间接编程”是通过提供数据来实现的。
算法是机器为达到特定目标而遵循的一组规则。可以将算法视为定义输入、输出以及从输入到输出所需的所有步骤的配方。烹饪食谱是一种算法,其中成分是输入,熟食是输出,准备和烹饪步骤是算法指令。
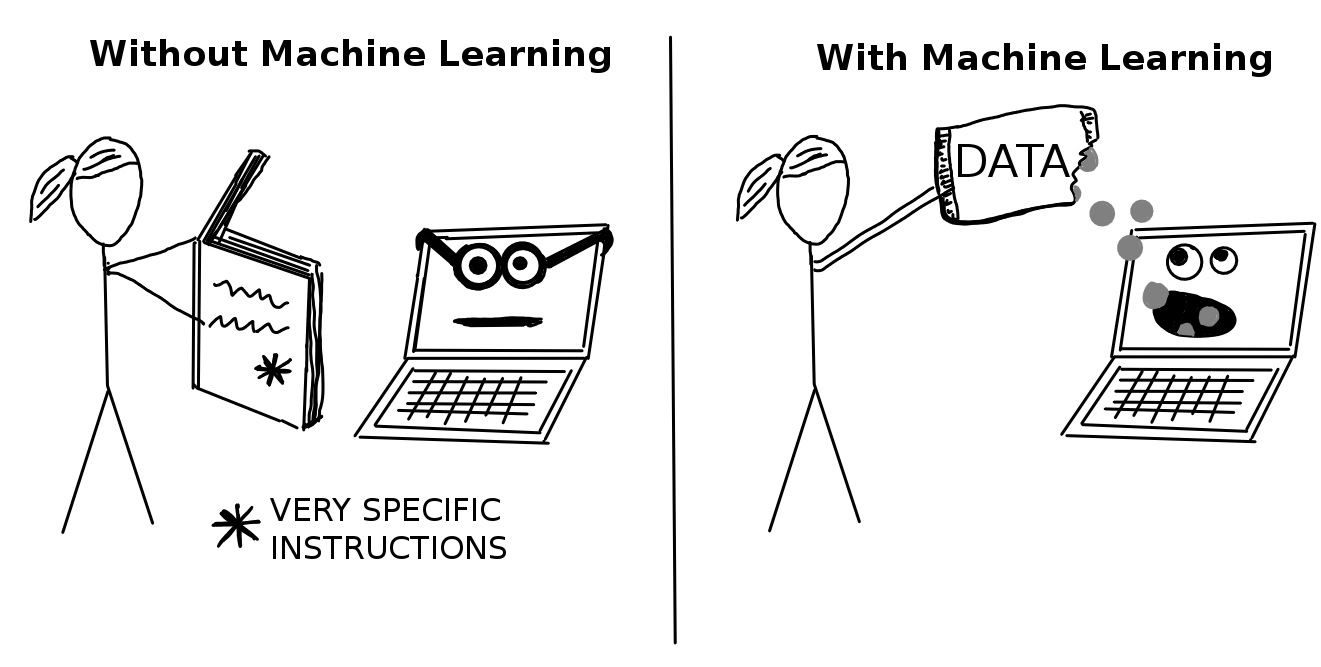
机器学习是一套方法,允许计算机从数据中学习,以做出和改进预测(例如癌症、每周销售、信用违约)。机器学习是从“正常编程”到“间接编程”的一种范式转换,所有指令都必须明确地提供给计算机,而“间接编程”是通过提供数据来实现的
。
**学习者**
或
**机器学习算法**
是用来从数据中学习机器学习模型的程序。另一个名字是“诱导器”(例如“树诱导器”)
。
学习者或机器学习算法是用来从数据学习机器学习模型的程序。另一个名字是“诱导器”(例如“树诱导器”)
。
**机器学习模型**
是将输入映射到预测的学习程序。这可以是线性模型或神经网络的一组权重。“模型”这个不太具体的词的其他名称是“预测器”,或者——取决于任务——“分类器”或者“回归模型”。在公式中,经过训练的机器学习模型称为 $(
\h
at{f})$ 或 $(
\h
at{f}(x))$
。
机器学习模型是将输入映射到预测的学习程序。这可以是线性模型或神经网络的一组权重。“模型”这个不太具体的词的其他名称是“预测器”,或者——取决于任务——“分类器”或者“回归模型”。在公式中,经过训练的机器学习模型称为
\(\h
at f
\)
或
\(\h
at f(x))。
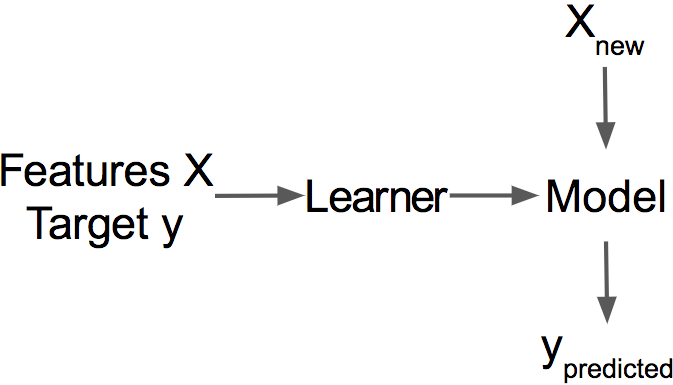
图1.1:学习者从标记的
培训
数据学习模型。该模型用于预测。
图1.1:学习者从标记的
训练
数据学习模型。该模型用于预测。
黑盒模型是一个不揭示其内部机制的系统。在机器学习中,“黑匣子”描述了通过查看参数(例如神经网络)无法理解的模型。黑盒的对立面有时被称为白盒,在本书中被称为可解释性,
将机器学习模型视为黑盒,即使它们不是。
**黑盒模型**
是一个不揭示其内部机制的系统。在机器学习中,“黑匣子”描述了通过查看参数(例如神经网络)却无法理解的模型。黑盒的对立面有时被称为
**白盒**
,在本书中被称为
[
可解释性模型
](
https://christophm.github.io/interpretable-ml-book/simple.html#simple
)
,用于解释模型的
[
不可知方法
](
https://christophm.github.io/interpretable-ml-book/agnostic.html#agnostic
)
将机器学习模型视为黑盒,即使它们不是。
可解释机器学习是指使机器学习系统的行为和预测对人类可理解的方法和模型。

数据集是一个表,其中包含机器从中学习的数据。数据集包含要预测的功能和目标。当用于诱导模型时,数据集称为训练数据
。
**可解释机器学习**
是指使机器学习系统的行为和预测对人类可理解的方法和模型
。
实例是数据集中的一行。“instance”的其他名称是:(data)point,example,observation。实例由功能值
\(
x^(i)
\)
和目标结果(如果已知)组成
。
**数据集**
是一个表格,其中包含机器从中学习的数据。数据集包含要预测的特征和目标。当用于训练模型时,数据集称为训练数据
。
这些特征是用于预测或分类的输入。功能是数据集中的列。在整本书中,人们都认为特征是可以解释的,这意味着很容易理解它们的含义,比如某一天的温度或一个人的身高。特征的可解释性是一个很大的假设。但是,如果很难理解输入特性,那么更难理解模型的功能。对于单个实例,具有所有特性的矩阵称为x和
\(
x^(i)
\)
。所有实例的单个功能的向量是
\(
x_j),而功能j和实例i的值是
\(
x^(i)_j)
。
**实例**
是数据集中的一行。“instance”的其他名称是:(数据)点,样本,观测对象。实例由特征值 $(x^{i})$ 和目标结果 $(y_i)$(如果已知)组成
。
目标是机器学会预测的信息。在数学公式中,对于单个实例,目标通常称为y或(y_i)
。
这些
**特征**
是用于对输入进行预测或分类的。特征是数据集中的列。在整本书中,人们都认为特征是可解释的,这意味着很容易理解它们的含义,比如某一天的温度或一个人的身高。特征的可解释性是一个很大的假设。但是,如果很难理解输入特征,那么更难理解模型的行为。对于单个实例,具有所有特征的矩阵称为 $X$ 和 $(x^{i})$ 。所有实例的单个特征向量是 $(x_j)$,而特征 $j$ 和实例 $i$ 的值是 $(x^i_j)$
。
机器学习任务是一个具有特征和目标的数据集的组合。根据目标的类型,任务可以是分类、回归、生存分析、聚类或异常值检测
。
**目标**
是机器学会预测的信息。在数学公式中,对于单个实例,目标通常称为 $y$ 或 $(y_i)$
。
预测是机器学习模型根据给定的特性“猜测”目标值应该是什么。在本书中,模型预测用
\(\h
at f(x^(i))或
\(\h
at y)表示
。
**机器学习任务**
是一个具有特征和目标的数据集的组合。根据目标的类型,任务可以是分类、回归、生存分析、聚类或异常值检测
。

**预测**
是机器学习模型根据给定的特征“猜测”目标值应该是什么。在本书中,模型预测用 $(
\h
at{f}(x^i))$ 或 $
\h
at{y}$ 表示。
1。“算法定义”。(2017年)。
2.
“算法的定义”。 https://www.merriam-webster.com/dictionary/algorithm(2017年)
docs/2.md
浏览文件 @
8e2b9d11
此差异已折叠。
点击以展开。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录