[add] 添加 prometheus operator文章
Showing
deploymentdemo/deploy-svc.yaml
0 → 100644
docs/57.AlertManager的使用.md
0 → 100644
此差异已折叠。
docs/58.Prometheus Operator.md
0 → 100644
此差异已折叠。
{kind=link}
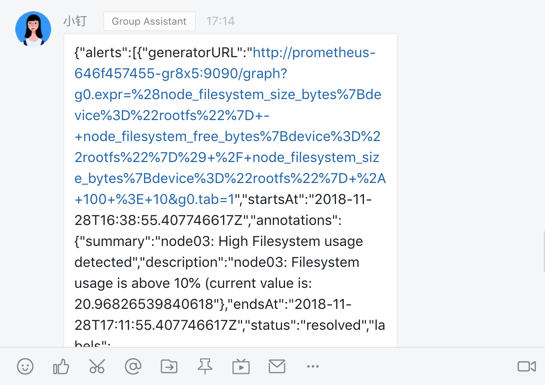
118.1 KB
{kind=link}
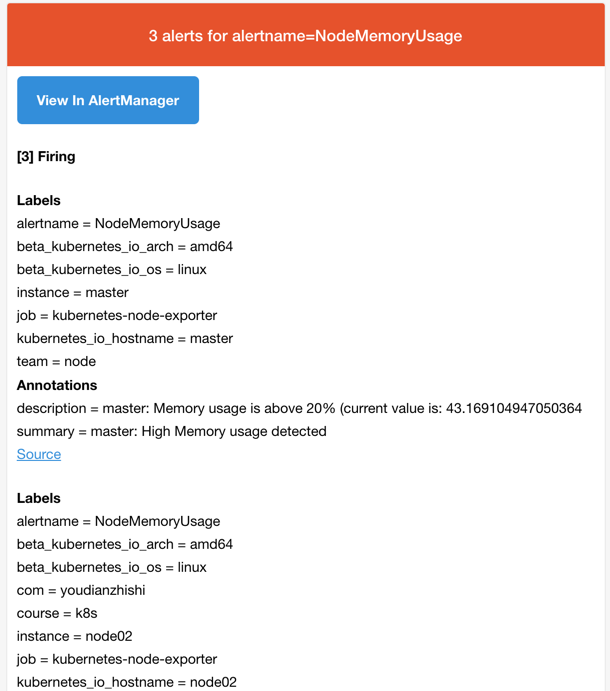
100.1 KB
{kind=link}
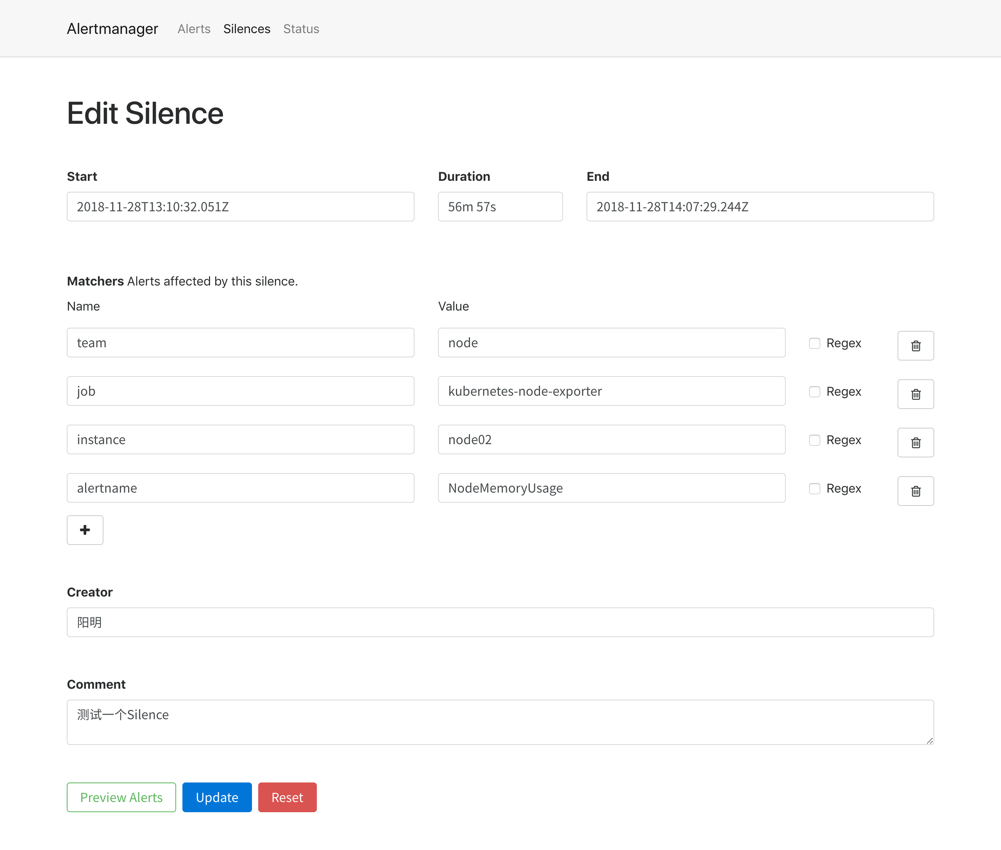
95.7 KB
{kind=link}
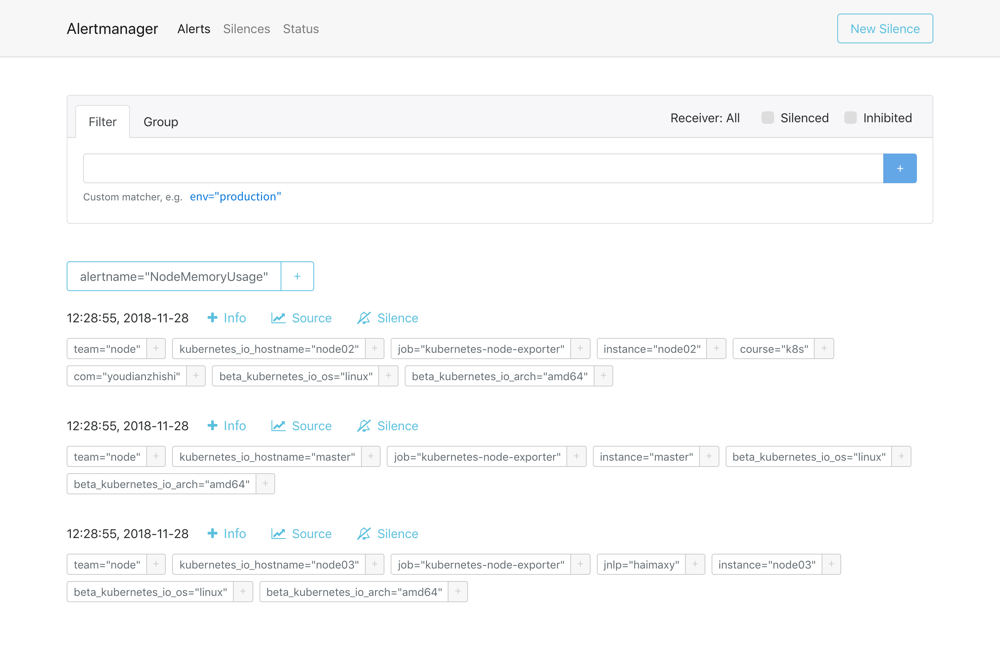
132.9 KB
docs/images/prometheus-alerts.png
0 → 100644
{kind=link}
168.4 KB
{kind=link}
162.9 KB
{kind=link}
147.6 KB
{kind=link}
87.6 KB
{kind=link}
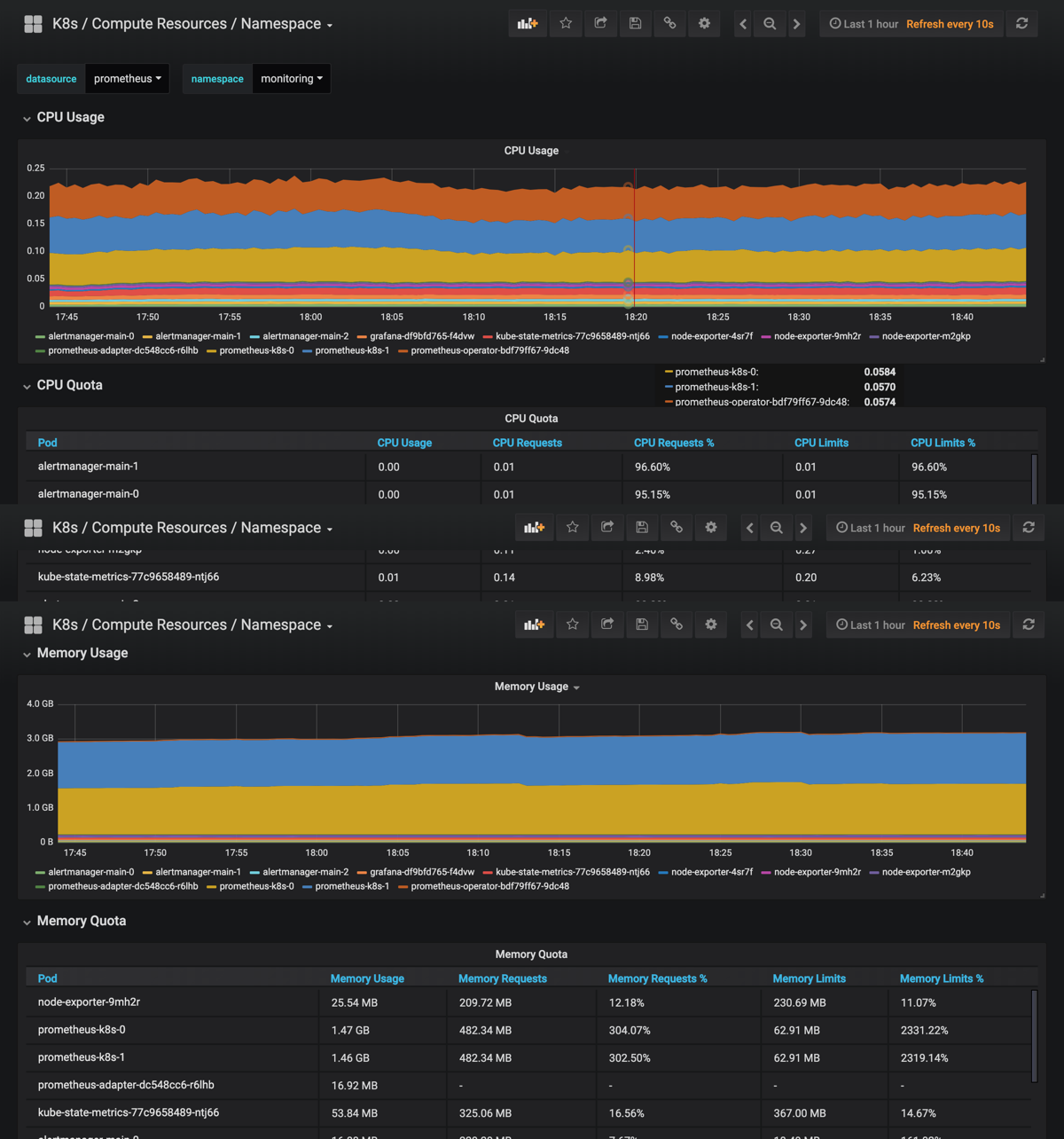
532.5 KB
{kind=link}

64.1 KB
{kind=link}

49.7 KB
{kind=link}
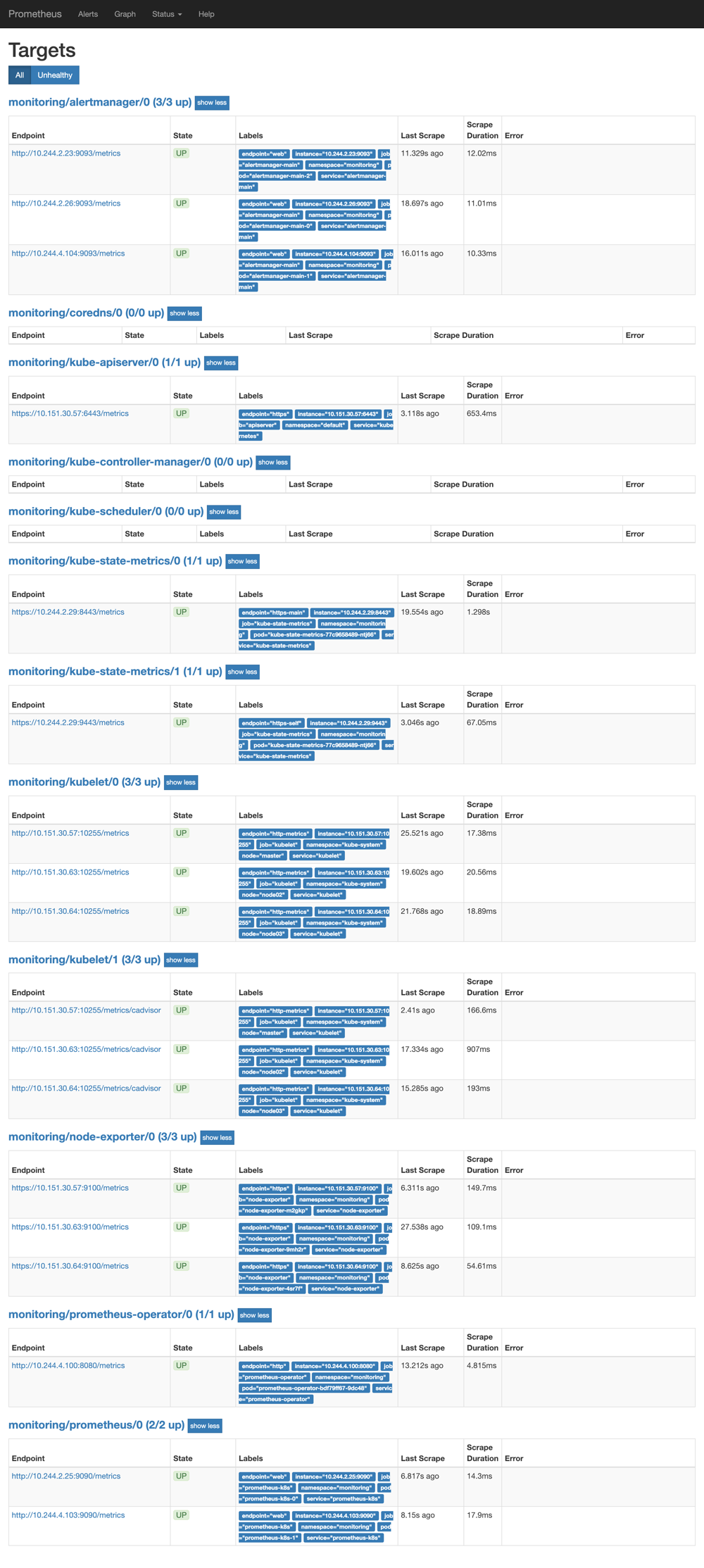
719.9 KB
prome/dingtalk-hook.yaml
0 → 100644