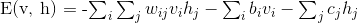RBM 尝试使用特定图形模型最大化数据的可能性(the likelihood of the data)。所使用的参数学习算法( [Stochastic Maximum Likelihood](#sml) (随机最大似然))防止特征表示偏离输入数据,这使得它们能学习到有趣的特征,但使得该模型对于小数据集不太有用且通常对于密度估计无效。
>* [Restricted Boltzmann Machine features for digit classification](https://scikit-learn.org/stable/auto_examples/neural_networks/plot_rbm_logistic_classification.html#sphx-glr-auto-examples-neural-networks-plot-rbm-logistic-classification-py)
> **示例**:
>
> * [Restricted Boltzmann Machine features for digit classification](https://scikit-learn.org/stable/auto_examples/neural_networks/plot_rbm_logistic_classification.html#sphx-glr-auto-examples-neural-networks-plot-rbm-logistic-classification-py)
>* [“A fast learning algorithm for deep belief nets”](http://www.cs.toronto.edu/~hinton/absps/fastnc.pdf) G. Hinton, S. Osindero, Y.-W. Teh, 2006
>* [“Training Restricted Boltzmann Machines using Approximations to the Likelihood Gradient”](http://www.cs.toronto.edu/~tijmen/pcd/pcd.pdf) T. Tieleman, 2008

{kind=link}