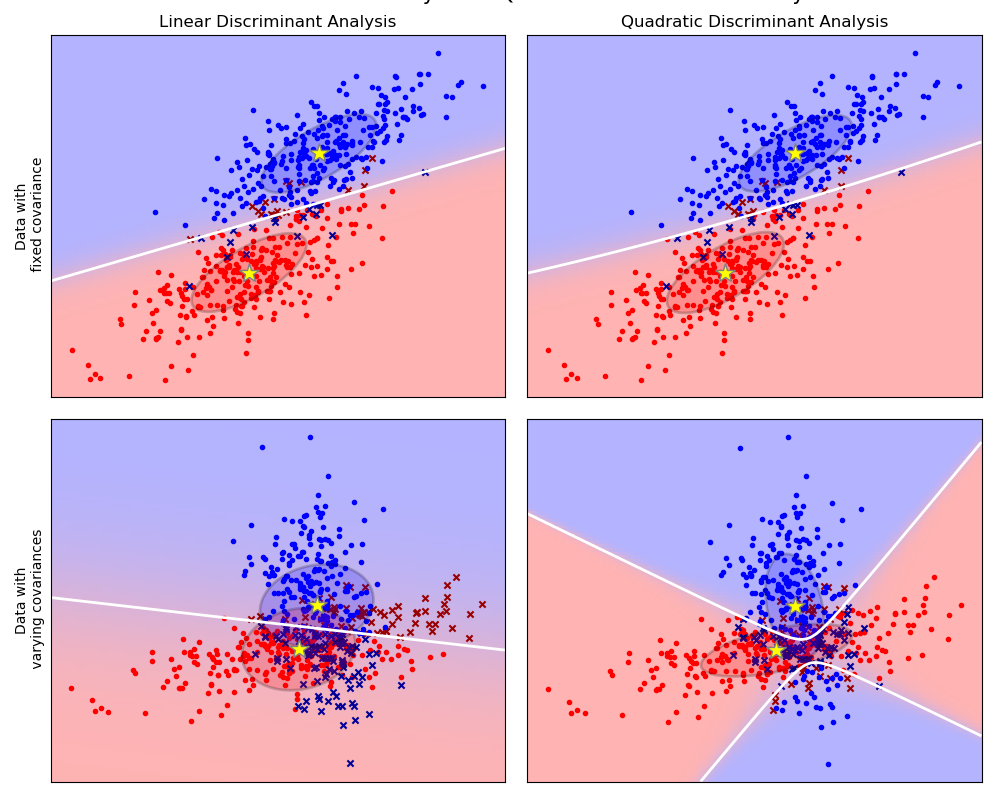
以上这些图像展示了 Linear Discriminant Analysis (线性判别分析)以及 Quadratic Discriminant Analysis (二次判别分析)的决策边界。其中,最后一行表明了线性判别分析只能学习线性边界, 而二次判别分析则可以学习二次边界,因此它相对而言更加灵活。
以上这些图像展示了 Linear Discriminant Analysis (线性判别分析)以及 Quadratic Discriminant Analysis (二次判别分析)的决策边界。其中,最后一行表明了线性判别分析只能学习线性边界, 而二次判别分析则可以学习二次边界,因此它相对而言更加灵活。
示例:
> 示例:
>* [Linear and Quadratic Discriminant Analysis with covariance ellipsoid](https://scikit-learn.org/stable/auto_examples/classification/plot_lda_qda.html): LDA和QDA在特定数据上的对比
[Linear and Quadratic Discriminant Analysis with covariance ellipsoid](../auto_examples/classification/plot_lda_qda.html#sphx-glr-auto-examples-classification-plot-lda-qda-py): LDA和QDA在特定数据上的对比
‘eigen’(特征) solver 是基于 class scatter (类散度)与 class scatter ratio (类内离散率)之间的优化。 它可以被用于 classification (分类)以及 transform (转换),此外它还同时支持收缩。然而,该解决方案需要计算协方差矩阵,因此它可能不适用于具有大量特征的情况。
Examples:
[Normal and Shrinkage Linear Discriminant Analysis for classification](../auto_examples/classification/plot_lda.html#sphx-glr-auto-examples-classification-plot-lda-py): Comparison of LDA classifiers with and without shrinkage.
References:
`eigen`(特征) solver 是基于 class scatter (类散度)与 class scatter ratio (类内离散率)之间的优化。 它可以被用于 classification (分类)以及 transform (转换),此外它还同时支持收缩。然而,该解决方案需要计算协方差矩阵,因此它可能不适用于具有大量特征的情况。
| [3] | _([1](#id4), [2](#id5))_ “The Elements of Statistical Learning”, Hastie T., Tibshirani R., Friedman J., Section 4.3, p.106-119, 2008. |
> 示例:
>
>* [Normal and Shrinkage Linear Discriminant Analysis for classification](https://scikit-learn.org/stable/auto_examples/classification/plot_lda.html#sphx-glr-auto-examples-classification-plot-lda-py): Comparison of LDA classifiers with and without shrinkage.
| [4] | Ledoit O, Wolf M. Honey, I Shrunk the Sample Covariance Matrix. The Journal of Portfolio Management 30(4), 110-119, 2004. |
>参考文献:
\ No newline at end of file
> * [3] “The Elements of Statistical Learning”, Hastie T., Tibshirani R., Friedman J., Section 4.3, p.106-119, 2008.
> * [4] Ledoit O, Wolf M. Honey, I Shrunk the Sample Covariance Matrix. The Journal of Portfolio Management 30(4), 110-119, 2004.
{kind=link}