Merge pull request #8 from liuyixi520/master
Update. 10.md-14.md
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/img/b1b2.png
0 → 100644
{kind=link}
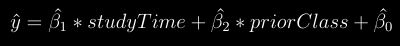
7.3 KB
docs/img/bayes.png
0 → 100644
{kind=link}

5.6 KB
docs/img/bf.png
0 → 100644
{kind=link}
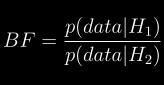
5.3 KB
docs/img/bhat.png
0 → 100644
{kind=link}
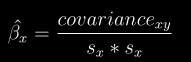
4.5 KB
docs/img/bw.png
0 → 100644
{kind=link}

18.1 KB
docs/img/chi.png
0 → 100644
{kind=link}

7.8 KB
docs/img/ci.png
0 → 100644
{kind=link}

3.5 KB
docs/img/cix.png
0 → 100644
{kind=link}

3.3 KB
docs/img/cov_my.png
0 → 100644
{kind=link}
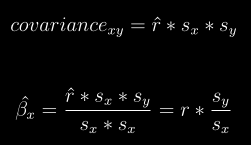
8.1 KB
docs/img/dx12.png
0 → 100644
{kind=link}
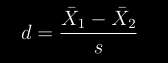
2.3 KB
docs/img/free.png
0 → 100644
{kind=link}
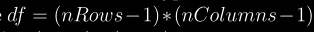
5.7 KB
docs/img/gini.png
0 → 100644
{kind=link}
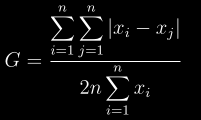
6.2 KB
docs/img/linear.png
0 → 100644
{kind=link}
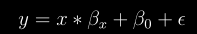
2.8 KB
docs/img/ms1.png
0 → 100644
{kind=link}
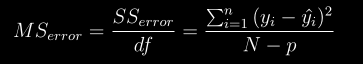
7.0 KB
docs/img/odds.png
0 → 100644
{kind=link}
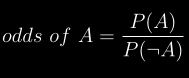
4.6 KB
docs/img/paradox.png
0 → 100644
{kind=link}

29.2 KB
docs/img/pet.png
0 → 100644
{kind=link}
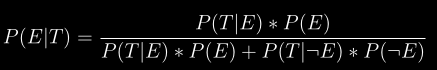
7.9 KB
docs/img/power.png
0 → 100644
{kind=link}
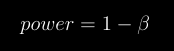
2.3 KB
docs/img/r22.png
0 → 100644
{kind=link}
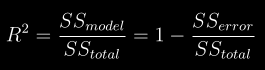
5.0 KB
docs/img/res1.png
0 → 100644
{kind=link}

4.9 KB
docs/img/rhat.png
0 → 100644
{kind=link}
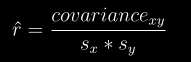
4.0 KB
docs/img/s2.png
0 → 100644
{kind=link}
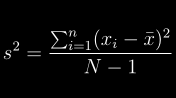
4.0 KB
docs/img/sbw.png
0 → 100644
{kind=link}

32.3 KB
docs/img/search.png
0 → 100644
{kind=link}
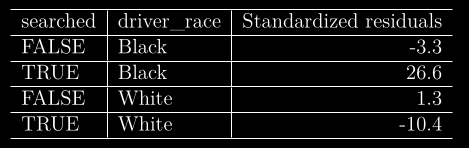
19.5 KB
docs/img/ss2.png
0 → 100644
{kind=link}

3.6 KB
docs/img/sse1.png
0 → 100644
{kind=link}
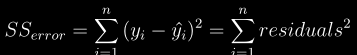
6.9 KB
docs/img/stand.png
0 → 100644
{kind=link}
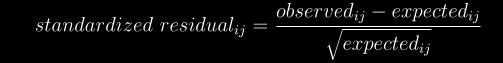
10.0 KB
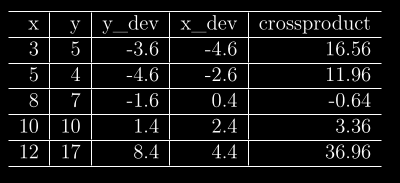
docs/img/table1.png
0 → 100644
{kind=link}
19.1 KB
docs/img/tnps.png
0 → 100644
{kind=link}
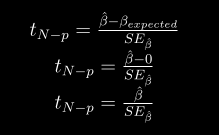
7.5 KB
docs/img/tr.png
0 → 100644
{kind=link}
3.1 KB