Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
think-comp-2e-zh
提交
129e357c
T
think-comp-2e-zh
项目概览
OpenDocCN
/
think-comp-2e-zh
8 个月 前同步成功
通知
0
Star
16
Fork
7
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
think-comp-2e-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
129e357c
编写于
4月 10, 2018
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
7.
上级
51c105c8
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
120 addition
and
0 deletion
+120
-0
7.md
7.md
+120
-0
img/7-6.png
img/7-6.png
+0
-0
img/7-7.png
img/7-7.png
+0
-0
未找到文件。
7.md
浏览文件 @
129e357c
...
...
@@ -207,3 +207,123 @@ kernel = np.array([[0, 1, 0],
图 7.5:渗流模型的前三个步骤,其中
`n=10`
和
`p=0.5`
图?显示了
`n = 10`
和
`p = 0.5`
的渗流模型的前几个步骤。 非多孔细胞为白色,多孔细胞为浅色,湿细胞为深色。
## 7.4 相变
现在让我们测试 CA 是否包含渗流簇。
```
py
def
test_perc
(
perc
):
num_wet
=
perc
.
num_wet
()
num_steps
=
0
while
True
:
perc
.
step
()
num_steps
+=
1
if
perc
.
bottom_row_wet
():
return
True
,
num_steps
new_num_wet
=
perc
.
num_wet
()
if
new_num_wet
==
num_wet
:
return
False
,
num_steps
num_wet
=
new_num_wet
```
`test_perc`
接受
`Percolation`
对象作为参数。 每次循环中,它都会使 CA 前进一个时间步骤。 它检查底部那行,看看有没有湿的细胞;如果有,它返回
`True`
,表示存在渗透簇,以及
`num_steps`
,它是到达底部所需的时间步数。
在每个时间步骤中,它还计算湿细胞的数量并检查自上一步以来数量是否增加。 如果没有,我们已经到达了固定点,而没有找到一个渗流簇,所以我们返回
`False`
。
为了估计渗流簇的概率,我们生成许多随机初始状态并测试它们:
```
py
def
estimate_prob_percolating
(
p
=
0.5
,
n
=
100
,
iters
=
100
):
count
=
0
for
i
in
range
(
iters
):
perc
=
Percolation
(
n
,
p
=
p
)
flag
,
_
=
test_perc
(
perc
)
if
flag
:
count
+=
1
return
count
/
iters
```
`estimate_prob_percolating`
使用给定的
`p`
和
`n`
值生成 100 个 CA,并调用
`test_perc`
来查看其中有多少个具有渗流簇。 返回值是拥有的 CA 的比例。
当
`p = 0.55`
时,渗滤簇的概率接近于 0。
`p = 0.60`
时,它约为 70%,而在
`p = 0.65`
时,它接近于 1。这种快速转变表明
`p`
的临界值接近 0.6。
我们可以更精确地使用随机游走来估计临界值。 从
`p`
的初始值开始,我们构造一个
`Percolation`
对象并检查它是否具有渗透簇。 如果是这样,
`p`
可能太高,所以我们减少它。 如果不是,
`p`
可能太低,所以我们增加它。
这里是代码:
```
py
def
find_critical
(
p
=
0.6
,
n
=
100
,
iters
=
100
):
ps
=
[
p
]
for
i
in
range
(
iters
):
perc
=
Percolation
(
n
=
n
,
p
=
p
)
flag
,
_
=
test_perc
(
perc
)
if
flag
:
p
-=
0.005
else
:
p
+=
0.005
ps
.
append
(
p
)
return
ps
```
`find_critical`
以
`p`
的给定值开始并上下调整,返回值的列表。 当
`n = 100`
时,
`ps`
的平均值约为 0.59,对于从 50 到 400 的
`n`
值,这个临界值似乎是一样的。
临界值附近的行为的快速变化称为相变,类似于物理系统中的相变,例如水在冰点处从液体变为固体的方式。
在处于或接近临界点时,各种各样的系统展示了一组共同的行为和特征。这些行为被统称为临界现象。 在下一节中,我们将探究其中的一个:分形几何。
## 7.5 分形
为了理解分形,我们必须从维度开始。
对于简单的几何对象,维度根据缩放行为而定义。 例如,如果正方形的边长为
`l`
,则其面积为
`l ** 2`
。 指数 2 表示正方形是二维的。 同样,如果立方体的边长为
`l`
,则其体积为
`l ** 3`
,这表示立方体是三维的。
更一般来说,我们可以通过测量一个对象的“尺寸”(通过一些定义),将对象的维度估计为线性度量的函数。
例如,我将通过测量一维元胞自动机的面积(“开”细胞的总数),将它的维度估计为行数的函数。

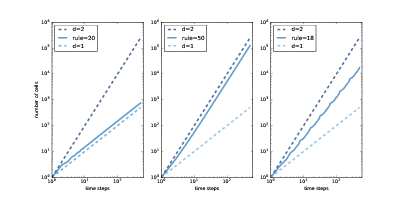
图 7.6:32 个时间步之后,规则为 20,50 和 18 的一维 CA。
图?展示了三个一维 CA,就像我们在第?节中看到的那样。 规则 20(左)产生一组看似线性的细胞,所以我们预计它是一维的。 规则 50(中)产生类似于三角形的东西,所以我们预计它是二维的。 规则 18(右)也产生类似三角形的东西,但密度不均匀,所以其缩放行为并不明显。
我将用以下函数来估计这些 CA 的维度,该函数计算每个时间步之后的细胞数。 它返回一个元组列表,其中每个元组包含
`i`
和
`i ** 2`
,用于比较,以及细胞总数。
```
py
def
count_cells
(
rule
,
n
=
500
):
ca
=
Cell1D
(
rule
,
n
)
ca
.
start_single
()
res
=
[]
for
i
in
range
(
1
,
n
):
cells
=
np
.
sum
(
ca
.
array
)
res
.
append
((
i
,
i
**
2
,
cells
))
ca
.
step
()
return
res
```

图 7.7:规则 20,50 和 18 的“开”细胞的数量与时间步数。
图?展示以双对数刻度绘制的结果。
在每幅图中,顶部虚线表示
`y = i ** 2`
。 两边取对数,我们得到
`logy = 2logi`
。 由于该数字在双对数刻度上,因此直线的斜率为2。
同样,底部的虚线表示
`y = i`
。 在双对数刻度上,直线的斜率为 1。
规则 20(左)每两个时间步骤产生三个细胞,所以
`i`
步后的细胞总数为
`y = 1.5 i`
。 两边取对数,我们得到
`logy = log1.5 + logi`
,所以在双对数刻度上,我们期待一条斜率为 1 的线。实际上,线的估计的斜率为 1.01。
规则 50(中)在第
`i`
个时间步骤中产生
`i + 1`
个新细胞,因此
`i`
步之后的细胞总数为
`y = i ** 2 + i`
。 如果我们忽略第二项并取两边的对数,我们有
`logy ~ 2 logi`
,所以当
`i`
变大时,我们预计看到一条斜率为 2 的线。事实上,估计的斜率为 1.97。
最后,对于规则 18(右),估计的斜率大约是 1.57,这显然不是 1,2 或任何其他整数。 这表明规则 18 生成的图案具有“分数维度”;也就是说,它是一个分形。
img/7-6.png
0 → 100644
浏览文件 @
129e357c
10.4 KB
img/7-7.png
0 → 100644
浏览文件 @
129e357c
8.3 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}