Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
think-comp-2e-zh
提交
bd76a582
T
think-comp-2e-zh
项目概览
OpenDocCN
/
think-comp-2e-zh
8 个月 前同步成功
通知
0
Star
16
Fork
7
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
think-comp-2e-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
bd76a582
编写于
11月 01, 2017
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
3.7
上级
e8316470
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
75 addition
and
0 deletion
+75
-0
3.md
3.md
+75
-0
img/3-3.png
img/3-3.png
+0
-0
未找到文件。
3.md
浏览文件 @
bd76a582
...
...
@@ -240,3 +240,78 @@ def characteristic_path_length(G):
这个例子中,所有三个节点都互相连接,所以平均长度为 1。
## 3.7 WS 实验

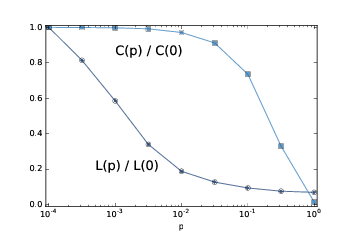
> 图 3.3:WS 图的群聚系数`C`和特征路径长度`L`,其中`n=1000, k=10`,`p`是一个范围。
现在我们准备复制 WS 实验,它表明对于一系列
`p`
值,WS 图具有像正则图像那样的高群聚性,像随机图一样的短路径长度。
我将从
`run_one_graph`
开始,它接受
`n`
,
`k`
和
`p`
;它生成具有给定参数的 WS图,并计算平均路径长度
`mpl`
和群聚系数
`cc`
:
```
py
def
run_one_graph
(
n
,
k
,
p
):
ws
=
make_ws_graph
(
n
,
k
,
p
)
mpl
=
characteristic_path_length
(
ws
)
cc
=
clustering_coefficient
(
ws
)
print
(
mpl
,
cc
)
return
mpl
,
cc
```
sssss
Watts 和 Strogatz 用
`n = 1000`
和
`k = 10`
进行实验。使用这些参数,
`run_one_graph`
在我的电脑上需要大约一秒钟;大部分时间用于计算平均路径长度。
现在我们需要为范围内的
`p`
计算这些值。我将再次使用 NumPy 函数
`logspace`
来计算
`ps`
:
```
py
ps
=
np
.
logspace
(
-
4
,
0
,
9
)
```
对于每个
`p`
的值,我生成了 3 个随机图,并且我们将结果平均。这里是运行实验的函数:
```
py
def
run_experiment
(
ps
,
n
=
1000
,
k
=
10
,
iters
=
3
):
res
=
{}
for
p
in
ps
:
print
(
p
)
res
[
p
]
=
[]
for
_
in
range
(
iters
):
res
[
p
].
append
(
run_one_graph
(
n
,
k
,
p
))
return
res
```
结果是个字典,将每个
`p`
值映射为
`(mpl, cc)`
偶对的列表。
最后一步就是聚合结果:
```
py
L
=
[]
C
=
[]
for
p
,
t
in
sorted
(
res
.
items
()):
mpls
,
ccs
=
zip
(
*
t
)
mpl
=
np
.
mean
(
mpls
)
cc
=
np
.
mean
(
ccs
)
L
.
append
(
mpl
)
C
.
append
(
cc
)
```
每次循环时,我们取得一个
`p`
值和一个
`(mpl, cc)`
偶对的列表。 我们使用
`zip`
来提取两个列表,
`mpls`
和
`ccs`
,然后计算它们的均值并将它们添加到
`L`
和
`C`
,这是路径长度和群聚系数的列表。
为了在相同的轴上绘制
`L`
和
`C`
,我们通过除以第一个元素,将它们标准化:
```
py
L
=
np
.
array
(
L
)
/
L
[
0
]
C
=
np
.
array
(
C
)
/
C
[
0
]
```
图(?)展示了结果。 随着
`p`
的增加,平均路径长度迅速下降,因为即使少量随机重新布线的边,也提供了图区域之间的捷径,它们在格中相距很远。另一方面,删除局部链接降低了群聚系数,但是要慢得多。
因此,存在较宽范围的
`p`
,其中 WS 图具有小世界图的性质,高群聚度和短路径长度。
这就是为什么 Watts 和 Strogatz 提出了 WS 图,作为展示小世界现象的,现实世界网络的模型。
img/3-3.png
0 → 100644
浏览文件 @
bd76a582
5.9 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}