Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
think-dast-zh
提交
7ab86d9c
T
think-dast-zh
项目概览
OpenDocCN
/
think-dast-zh
8 个月 前同步成功
通知
0
Star
26
Fork
13
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
think-dast-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
7ab86d9c
编写于
9月 04, 2017
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
ch6
上级
2f1cd3b0
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
85 addition
and
1 deletion
+85
-1
6.md
6.md
+85
-1
img/6-1.jpg
img/6-1.jpg
+0
-0
img/6-2.jpg
img/6-2.jpg
+0
-0
img/6-3.jpg
img/6-3.jpg
+0
-0
未找到文件。
6.md
浏览文件 @
7ab86d9c
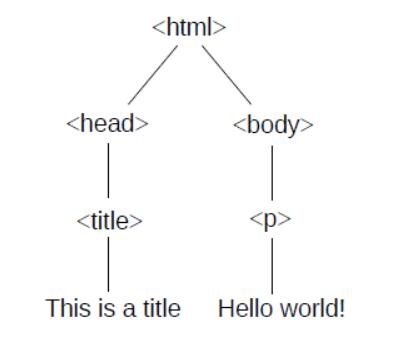
# 第六章 树的遍历
> 原文:[Chapter 6 Tree traversal](http://greenteapress.com/thinkdast/html/thinkdast007.html)
> 译者:[飞龙](https://github.com/wizardforcel)
> 协议:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
> 自豪地采用[谷歌翻译](https://translate.google.cn/)
本章将介绍一个 Web 搜索引擎,我们将在本书其余部分开发它。我描述了搜索引擎的元素,并介绍了第一个应用程序,一个从维基百科下载和解析页面的 Web 爬行器。本章还介绍了深度优先搜索的递归实现,以及迭代实现,它使用 Java
`Deque`
实现“后入先出”的栈。
## 6.1 搜索引擎
...
...
@@ -146,4 +154,80 @@ private static void recursiveDFS(Node node) {
在这个例子中,我们在遍历子节点之前打印每个
`TextNode`
的内容,所以这是一个“前序”遍历的例子。你可以在
<http://thinkdast.com/treetrav>
上了解“前序”,“后序”和“中序”遍历。对于此应用程序,遍历顺序并不重要。
通过进行递归调用,
`recursiveDFS`
使用调用堆栈(
<http://thinkdast.com/callstack>
)来跟踪子节点并以正确的顺序处理它们。作为替代,我们可以使用栈数据结构自己跟踪节点;如果我们这样做,我们可以避免递归并迭代遍历树。
通过进行递归调用,
`recursiveDFS`
使用调用栈(
<http://thinkdast.com/callstack>
)来跟踪子节点并以正确的顺序处理它们。作为替代,我们可以使用栈数据结构自己跟踪节点;如果我们这样做,我们可以避免递归并迭代遍历树。
## 6.6 Java 中的栈
在我解释 DFS 的迭代版本之前,我将解释栈数据结构。我们将从栈的一般概念开始,我将使用小写
`s`
指代“栈”。然后我们将讨论两个 Java
`interfaces`
,它们定义了栈的方法:
`Stack`
和
`Deque`
。
栈是与列表类似的数据结构:它是维护元素顺序的集合。栈和列表之间的主要区别是栈提供的方法较少。在通常的惯例中,它提供:
`push`
:它将一个元素添加到栈顶。
`pop`
:它从栈中删除并返回最顶部的元素。
`peek`
:它返回最顶部的元素而不修改栈。
`isEmpty`
:表示栈是否为空。
因为
`pop`
总是返回最顶部的元素,栈也称为 LIFO,代表“后入先出”。栈的替代品是“队列”,它返回的元素顺序和添加顺序相同;即“先入先出(FIFO)。
为什么栈和队列是有用的,可能不是很明显:它们不提供任何列表没有的功能;实际上它们提供的功能更少。那么为什么不使用列表的一切?有两个原因:
+
如果你将自己限制于一小部分方法 - 也就是小型 API - 你的代码将更加易读,更不容易出错。例如,如果使用列表来表示栈,则可能会以错误的顺序删除元素。使用栈 API,这种错误在字面上是不可能的。避免错误的最佳方法是使它们不可能。
+
如果一个数据结构提供了小型 API,那么它更容易实现。例如,实现栈的简单方法是单链表。当我们压入一个元素时,我们将它添加到列表的开头;当我们弹出一个元素时,我们在开头删除它。对于链表,在开头添加和删除是常数时间的操作,因此这个实现是高效的。相反,大型 API 更难实现高效。
为了在 Java 中实现栈,你有三个选项:
+
继续使用
`ArrayList`
或
`LinkedList`
。如果使用
`ArrayList`
,请务必从最后添加和删除,这是一个常数时间的操作。并且小心不要在错误的地方添加元素,或以错误的顺序删除它们。
+
Java 提供了一个
`Stack`
类,它提供了一组标准的栈方法。但是这个类是 Java 的一个旧部分:它与 Java 集合框架不兼容,后者之后才出现。
+
最好的选择可能是使用
`Deque`
接口的一个实现,如
`ArrayDeque`
。
`Deque`
代表“双向队列”;它应该被发音为“deck”,但有些人叫它“deek”。在 Java 中,
`Deque`
接口提供
`push`
,
`pop`
,
`peek`
和
`isEmpty`
,因此你可以将
`Deque`
用作栈。它提供了其他方法,你可以阅读
<http://thinkdast.com/deque>
,但现在我们不会使用它们。
## 6.7 迭代式 DFS
这里是 DFS 的迭代版本,它使用
`ArrayDeque`
来表示
`Node`
对象的栈。
```
java
private
static
void
iterativeDFS
(
Node
root
)
{
Deque
<
Node
>
stack
=
new
ArrayDeque
<
Node
>();
stack
.
push
(
root
);
while
(!
stack
.
isEmpty
())
{
Node
node
=
stack
.
pop
();
if
(
node
instanceof
TextNode
)
{
System
.
out
.
print
(
node
);
}
List
<
Node
>
nodes
=
new
ArrayList
<
Node
>(
node
.
childNodes
());
Collections
.
reverse
(
nodes
);
for
(
Node
child:
nodes
)
{
stack
.
push
(
child
);
}
}
}
```
参数
`root`
是我们想要遍历的树的根节点,所以我们首先创建栈并将根节点压入它。
循环持续到栈为空。每次迭代,它会从栈中弹出
`Node`
。如果它得到
`TextNode`
,它打印内容。然后它把子节点们压栈。为了以正确的顺序处理子节点,我们必须以相反的顺序将它们压栈; 我们通过将子节点复制成一个
`ArrayList`
,原地反转元素,然后遍历反转的
`ArrayList`
。
DFS 的迭代版本的一个优点是,更容易实现为 Java
`Iterator`
;你会在下一章看到如何实现。
但是首先,有一个
`Deque`
接口的最后的注意事项:除了
`ArrayDeque`
,Java 提供另一个
`Deque`
的实现,我们的老朋友
`LinkedList`
。
`LinkedList`
实现两个接口,
`List`
和
`Deque`
(还有
`Queue`
)。你得到哪个接口,取决于你如何使用它。例如,如果将
`LinkedList`
对象赋给
`Deque`
变量,如下所示:
```
java
Deqeue
<
Node
>
deque
=
new
LinkedList
<
Node
>();
```
你可以使用
`Deque`
接口中的方法,但不是所有
`List`
中的方法。如果你将其赋给
`List`
变量,像这样:
```
java
List
<
Node
>
deque
=
new
LinkedList
<
Node
>();
```
你可以使用
`List`
接口中的方法,但不是所有
`Deque`
中的方法。并且如果像这样赋值:
```
java
LinkedList
<
Node
>
deque
=
new
LinkedList
<
Node
>();
```
你可以使用所有方法,但是混合了来自不同接口的方法。你的代码会更不可读,并且更易于出错。
img/6-1.jpg
0 → 100644
浏览文件 @
7ab86d9c
8.1 KB
img/6-2.jpg
0 → 100644
浏览文件 @
7ab86d9c
63.8 KB
img/6-3.jpg
0 → 100644
浏览文件 @
7ab86d9c
14.9 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}