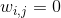Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
hands-on-ml-zh
提交
1e22bc36
H
hands-on-ml-zh
项目概览
OpenDocCN
/
hands-on-ml-zh
通知
13
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
H
hands-on-ml-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
1e22bc36
编写于
6月 10, 2018
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
ch8 tex
上级
5b67ebd6
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
2 addition
and
2 deletion
+2
-2
README.md
README.md
+1
-1
docs/8.降维.md
docs/8.降维.md
+1
-1
images/tex-095a09304bbece2585736594cca6bdbf.gif
images/tex-095a09304bbece2585736594cca6bdbf.gif
+0
-0
未找到文件。
README.md
浏览文件 @
1e22bc36
...
...
@@ -55,7 +55,7 @@
| 五、支持向量机 |
[
@QiaoXie
](
https://github.com/QiaoXie
)
|
[
@飞龙
](
https://github.com/wizardforcel
)
[
@PeterHo
]
(https://github.com/PeterHo)
[
@yanmengk
](
https://github.com/yanmengk
)
|
| 六、决策树 |
[
*@Lisanaaa*
](
https://github.com/Lisanaaa
)
|
| 七、集成学习和随机森林 |
[
@friedhelm739
](
https://github.com/friedhelm739
)
|
[
@飞龙
](
https://github.com/wizardforcel
)
[
@PeterHo
]
(https://github.com/PeterHo)
[
@yanmengk
](
https://github.com/yanmengk
)
|
| 八、降维 |
[
@loveSnowBest
](
https://github.com/zehuichen123
)
|
[
@飞龙
](
https://github.com/wizardforcel
)
[
@PeterHo
]
(https://github.com/PeterHo) |
| 八、降维 |
[
@loveSnowBest
](
https://github.com/zehuichen123
)
|
[
@飞龙
](
https://github.com/wizardforcel
)
[
@PeterHo
]
(https://github.com/PeterHo)
[
@yanmengk
](
https://github.com/yanmengk
)
|
|
**第二部分 神经网络与深度学习**
| - |
| 九、启动并运行TensorFlow |
[
@akonwang
](
https://github.com/wangxupeng
)
[
@WilsonQu
]
(https://github.com/WilsonQu) |
[
@Lisanaaa
](
https://github.com/Lisanaaa
)
[
@飞龙
]
(https://github.com/wizardforcel) |
| 十、人工神经网络介绍 |
[
@akonwang
](
https://github.com/wangxupeng
)
[
@friedhelm739
]
(https://github.com/friedhelm739) |
[
@飞龙
](
https://github.com/wizardforcel
)
|
...
...
docs/8.降维.md
浏览文件 @
1e22bc36
...
...
@@ -338,7 +338,7 @@ X_reduced=lle.fit_transform(X)
图 8-12 使用 LLE 展开瑞士卷
这是LLE的工作原理:首先,对于每个训练实例
$x^{(i)}$,该算法识别其最近的
`k`
个邻居(在前面的代码中
`k = 10`
中),然后尝试将 $x^{(i)}$ 重构为这些邻居的线性函数。更具体地,找到权重 $w_{i,j}$ 从而使 $x^{(i)}$ 和 $
\s
um_{j=1}^{m}w_{i,j} x^{(j)}$ 之间的平方距离尽可能的小,假设如果 $x^{(j)}$ 不是 $x^{(i)}$ 的
`k`
个最近邻时 $w_{i,j}=0$。因此,LLE 的第一步是方程 8-4 中描述的约束优化问题,其中
`W`
是包含所有权重 $w_{i,j}$ 的权重矩阵。第二个约束简单地对每个训练实例 $x^{(i)}$
的权重进行归一化。
这是LLE的工作原理:首先,对于每个训练实例
!
[
x^{(i)}
](
../images/tex-e8fa5b806940d1b4d0059fba40646506.gif
)
,该算法识别其最近的
`k`
个邻居(在前面的代码中
`k = 10`
中),然后尝试将 !
[
x^{(i)}
](
../images/tex-e8fa5b806940d1b4d0059fba40646506.gif
)
重构为这些邻居的线性函数。更具体地,找到权重 !
[
w_{i,j}
](
../images/tex-e32c5b6b54ce1398ae1134e7688631ad.gif
)
从而使 !
[
x^{(i)}
](
../images/tex-e8fa5b806940d1b4d0059fba40646506.gif
)
和 !
[
\sum_{j=1}^{m}w_{i,j} x^{(j)}
](
../images/tex-3a4d978e6657d768ca9a800d0e1a8130.gif
)
之间的平方距离尽可能的小,假设如果 !
[
x^{(j)}
](
../images/tex-b7762ca6ebcdab26862a6cd2ff27ac16.gif
)
不是 !
[
x^{(i)}
](
../images/tex-e8fa5b806940d1b4d0059fba40646506.gif
)
的
`k`
个最近邻时 !
[
w_{i,j}=0
](
../images/tex-095a09304bbece2585736594cca6bdbf.gif
)
。因此,LLE 的第一步是方程 8-4 中描述的约束优化问题,其中
`W`
是包含所有权重 !
[
w_{i,j}
](
../images/tex-e32c5b6b54ce1398ae1134e7688631ad.gif
)
的权重矩阵。第二个约束简单地对每个训练实例 !
[
x^{(i)}
](
../images/tex-e8fa5b806940d1b4d0059fba40646506.gif
)
的权重进行归一化。
公式 8-4 LLE 第一步:对局部关系进行线性建模
...
...
images/tex-095a09304bbece2585736594cca6bdbf.gif
0 → 100644
浏览文件 @
1e22bc36
290 字节
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}