初始化3.0.0版本
Showing
Dockerfile
已删除
100644 → 0
此差异已折叠。
bin/init_es_template.sh
0 → 100644
bin/shutdown.sh
0 → 100644
bin/standalone-deploy.sh
0 → 100644
bin/startup.sh
0 → 100644
文件已删除
container/helm/Chart.lock
已删除
100644 → 0
container/helm/Chart.yaml
已删除
100644 → 0
文件已删除
container/helm/values.yaml
已删除
100644 → 0
distribution/bin/shutdown.sh
已删除
100644 → 0
distribution/bin/startup.sh
已删除
100644 → 0
此差异已折叠。
distribution/pom.xml
已删除
100644 → 0
distribution/readme.md
已删除
100644 → 0
distribution/release-km.xml
已删除
100755 → 0
docs/assets/KnowStreamingLogo.png
0 → 100644
{kind=link}

40.8 KB
{kind=link}

73.3 KB
{kind=link}
7.4 KB
{kind=link}
183.3 KB
docs/assets/readme/WeChat.png
0 → 100644
{kind=link}

50.2 KB
docs/assets/readme/ZSXQ.jpg
0 → 100644
{kind=link}

95.8 KB
{kind=link}
270.0 KB
{kind=link}
785.2 KB
{kind=link}
2.5 MB
{kind=link}
69.4 KB
{kind=link}
588.9 KB
{kind=link}
651.6 KB
{kind=link}
511.3 KB
{kind=link}
671.9 KB
{kind=link}
599.8 KB
{kind=link}
227.7 KB
docs/dev_guide/use_mysql_8.md
已删除
100644 → 0
docs/dev_guide/健康巡检.md
0 → 100644
此差异已折叠。
docs/dev_guide/免登录调用接口.md
0 → 100644
docs/dev_guide/周期任务说明文档.md
已删除
100644 → 0
此差异已折叠。
docs/dev_guide/多版本兼容方案.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/dev_guide/指标说明.md
0 → 100644
此差异已折叠。
docs/dev_guide/本地源码启动手册.md
0 → 100644
此差异已折叠。
docs/dev_guide/登录系统对接.md
0 → 100644
此差异已折叠。
docs/dev_guide/解决连接JMX失败.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/install_guide/单机部署手册.md
0 → 100644
此差异已折叠。
docs/install_guide/源码编译打包手册.md
0 → 100644
此差异已折叠。
docs/install_guide/版本升级手册.md
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
260.9 KB
{kind=link}
239.5 KB
{kind=link}
195.3 KB
{kind=link}
124.2 KB
{kind=link}
105.4 KB
{kind=link}
94.2 KB
{kind=link}
181.0 KB
{kind=link}
65.0 KB
{kind=link}
166.3 KB
{kind=link}
29.5 KB
{kind=link}
78.1 KB
{kind=link}
48.4 KB
{kind=link}
54.6 KB
{kind=link}

15.9 KB
{kind=link}
296.9 KB
{kind=link}
189.0 KB
{kind=link}
173.1 KB
{kind=link}
197.3 KB
{kind=link}
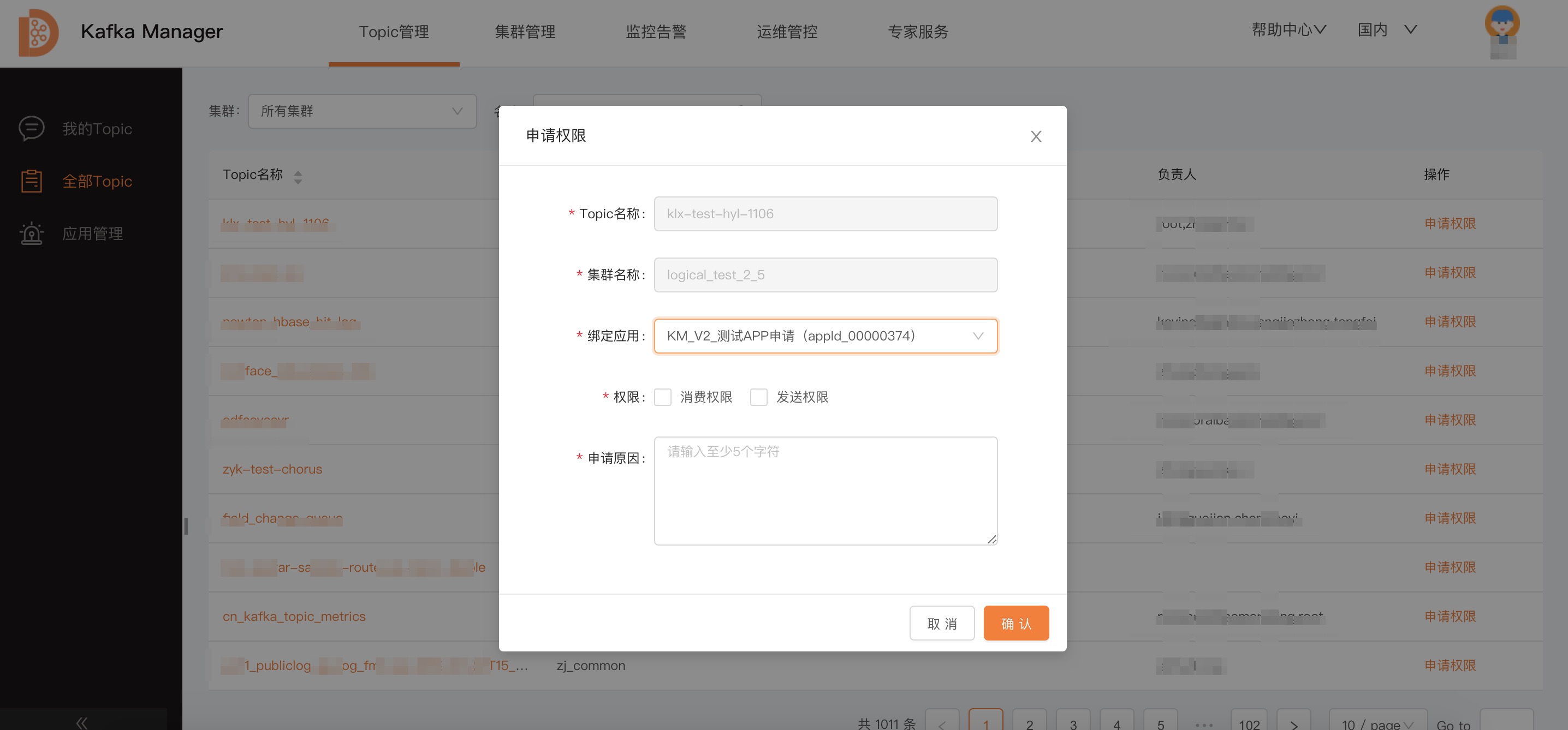
244.1 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/user_guide/新旧对比手册.md
0 → 100644
此差异已折叠。
docs/user_guide/用户使用手册.md
0 → 100644
此差异已折叠。
docs/开源版与商业版特性对比.md
已删除
100644 → 0
此差异已折叠。
kafka-manager-common/pom.xml
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
kafka-manager-console/pom.xml
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
kafka-manager-core/pom.xml
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
kafka-manager-dao/pom.xml
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。