- 27 7月, 2020 2 次提交
-
-
由 HyukjinKwon 提交于
### What changes were proposed in this pull request? This PR removes the manual port of `heapq3.py` introduced from SPARK-3073. The main reason of this was to support Python 2.6 and 2.7 because Python 2's `heapq.merge()` doesn't not support `key` and `reverse`. See - https://docs.python.org/2/library/heapq.html#heapq.merge in Python 2 - https://docs.python.org/3.8/library/heapq.html#heapq.merge in Python 3 Since we dropped the Python 2 at SPARK-32138, we can remove this away. ### Why are the changes needed? To remove unnecessary codes. Also, we can leverage bug fixes made in Python 3.x at `heapq`. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Existing tests should cover. I locally ran and verified: ```bash ./python/run-tests --python-executable=python3 --testname="pyspark.tests.test_shuffle" ./python/run-tests --python-executable=python3 --testname="pyspark.shuffle ExternalSorter" ./python/run-tests --python-executable=python3 --testname="pyspark.tests.test_rdd RDDTests.test_external_group_by_key" ``` Closes #29229 from HyukjinKwon/SPARK-32435. Authored-by: NHyukjinKwon <gurwls223@apache.org> Signed-off-by: NHyukjinKwon <gurwls223@apache.org>
-
由 HyukjinKwon 提交于
### What changes were proposed in this pull request? This PR proposes to redesign the PySpark documentation. I made a demo site to make it easier to review: https://hyukjin-spark.readthedocs.io/en/stable/reference/index.html. Here is the initial draft for the final PySpark docs shape: https://hyukjin-spark.readthedocs.io/en/latest/index.html. In more details, this PR proposes: 1. Use [pydata_sphinx_theme](https://github.com/pandas-dev/pydata-sphinx-theme) theme - [pandas](https://pandas.pydata.org/docs/) and [Koalas](https://koalas.readthedocs.io/en/latest/) use this theme. The CSS overwrite is ported from Koalas. The colours in the CSS were actually chosen by designers to use in Spark. 2. Use the Sphinx option to separate `source` and `build` directories as the documentation pages will likely grow. 3. Port current API documentation into the new style. It mimics Koalas and pandas to use the theme most effectively. One disadvantage of this approach is that you should list up APIs or classes; however, I think this isn't a big issue in PySpark since we're being conservative on adding APIs. I also intentionally listed classes only instead of functions in ML and MLlib to make it relatively easier to manage. ### Why are the changes needed? Often I hear the complaints, from the users, that current PySpark documentation is pretty messy to read - https://spark.apache.org/docs/latest/api/python/index.html compared other projects such as [pandas](https://pandas.pydata.org/docs/) and [Koalas](https://koalas.readthedocs.io/en/latest/). It would be nicer if we can make it more organised instead of just listing all classes, methods and attributes to make it easier to navigate. Also, the documentation has been there from almost the very first version of PySpark. Maybe it's time to update it. ### Does this PR introduce _any_ user-facing change? Yes, PySpark API documentation will be redesigned. ### How was this patch tested? Manually tested, and the demo site was made to show. Closes #29188 from HyukjinKwon/SPARK-32179. Authored-by: NHyukjinKwon <gurwls223@apache.org> Signed-off-by: NHyukjinKwon <gurwls223@apache.org>
-
- 17 7月, 2020 1 次提交
-
-
由 HyukjinKwon 提交于
### What changes were proposed in this pull request? This PR aims to upgrade PySpark's embedded cloudpickle to the latest cloudpickle v1.5.0 (See https://github.com/cloudpipe/cloudpickle/blob/v1.5.0/cloudpickle/cloudpickle.py) ### Why are the changes needed? There are many bug fixes. For example, the bug described in the JIRA: dill unpickling fails because they define `types.ClassType`, which is undefined in dill. This results in the following error: ``` Traceback (most recent call last): File "/usr/local/lib/python3.6/site-packages/apache_beam/internal/pickler.py", line 279, in loads return dill.loads(s) File "/usr/local/lib/python3.6/site-packages/dill/_dill.py", line 317, in loads return load(file, ignore) File "/usr/local/lib/python3.6/site-packages/dill/_dill.py", line 305, in load obj = pik.load() File "/usr/local/lib/python3.6/site-packages/dill/_dill.py", line 577, in _load_type return _reverse_typemap[name] KeyError: 'ClassType' ``` See also https://github.com/cloudpipe/cloudpickle/issues/82. This was fixed for cloudpickle 1.3.0+ (https://github.com/cloudpipe/cloudpickle/pull/337), but PySpark's cloudpickle.py doesn't have this change yet. More notably, now it supports C pickle implementation with Python 3.8 which hugely improve performance. This is already adopted in another project such as Ray. ### Does this PR introduce _any_ user-facing change? Yes, as described above, the bug fixes. Internally, users also could leverage the fast cloudpickle backed by C pickle. ### How was this patch tested? Jenkins will test it out. Closes #29114 from HyukjinKwon/SPARK-32094. Authored-by: NHyukjinKwon <gurwls223@apache.org> Signed-off-by: NHyukjinKwon <gurwls223@apache.org>
-
- 04 11月, 2019 1 次提交
-
-
由 Sean Owen 提交于
### What changes were proposed in this pull request? Update the version of dropwizard metrics that Spark uses for metrics to 4.1.x, from 3.2.x. ### Why are the changes needed? This helps JDK 9+ support, per for example https://github.com/dropwizard/metrics/pull/1236 ### Does this PR introduce any user-facing change? No, although downstream users with custom metrics may be affected. ### How was this patch tested? Existing tests. Closes #26332 from srowen/SPARK-29674. Authored-by: NSean Owen <sean.owen@databricks.com> Signed-off-by: NDongjoon Hyun <dhyun@apple.com>
-
- 08 10月, 2019 1 次提交
-
-
由 gengjiaan 提交于
### What changes were proposed in this pull request? The `LICENSE` file exists a minor issue has an incorrect path. This PR will fix it. ### Why are the changes needed? This is a minor bug. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Exists UT. Closes #26050 from beliefer/resolve-minor-license-issue. Authored-by: Ngengjiaan <gengjiaan@360.cn> Signed-off-by: NHyukjinKwon <gurwls223@apache.org>
-
- 02 5月, 2019 1 次提交
-
-
由 sangramga 提交于
## What changes were proposed in this pull request? Add a non-intrusive button for python API documentation, which will remove ">>>" prompts and outputs of code - for easier copying of code. For example: The below code-snippet in the document is difficult to copy due to ">>>" prompts ``` >>> l = [('Alice', 1)] >>> spark.createDataFrame(l).collect() [Row(_1='Alice', _2=1)] ``` Becomes this - After the copybutton in the corner of of code-block is pressed - which is easier to copy ``` l = [('Alice', 1)] spark.createDataFrame(l).collect() ``` 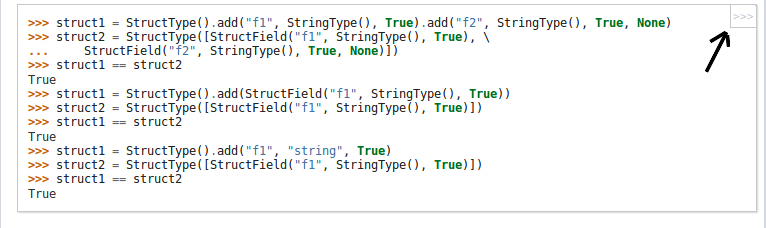 ## File changes Made changes to python/docs/conf.py and copybutton.js - thus only modifying sphinx frontend and no changes were made to the documentation itself- Build process for documentation remains the same. copybutton.js -> This JS snippet was taken from the official python.org documentation site. ## How was this patch tested? NA Closes #24456 from sangramga/copybutton. Authored-by: Nsangramga <sangramga@gmail.com> Signed-off-by: NSean Owen <sean.owen@databricks.com>
-
- 01 7月, 2018 1 次提交
-
-
由 Sean Owen 提交于
Whew, lots of work to track down again all the license requirements, but this ought to be a pretty good pass. Below, find a writeup on how I approached it for future reference. - LICENSE and NOTICE and licenses/ now reflect the *source* release - LICENSE-binary and NOTICE-binary and licenses-binary now reflect the binary release - Recreated all the license info from scratch - Added notes about how this was constructed for next time - License-oriented info was moved from NOTICE to LICENSE, esp. for Cat B deps - Some seemingly superfluous or stale license info was removed, especially for test-scope deps - Updated release script to put binary-oriented versions in binary releases ---- # Principles ASF projects distribute source and binary code under the Apache License 2.0. However these project distributions frequently include copies of source or binary code from third parties, under possibly other license terms. This triggers conditions of those licenses, which essentially amount to including license information in a LICENSE and/or NOTICE file, and including copies of license texts (here, in a directory called `license/`). See http://www.apache.org/dev/licensing-howto.html and https://www.apache.org/legal/resolved.html#required-third-party-notices # In Spark Spark produces source releases, and also binary releases of that code. Spark source code may contain source from third parties, possibly modified. This is true in Scala, Java, Python and R, and in the UI's JavaScript and CSS files. These must be handled appropriately per above in a LICENSE and NOTICE file created for the source release. Separately, the binary releases may contain binary code from third parties. This is very much true for Scala and Java, as Spark produces an 'assembly' binary release which includes all transitive binary dependencies of this part of Spark. With perhaps the exception of py4j, this doesn't occur in the same way for Python or R because of the way these ecosystems work. (Note that the JS and CSS for the UI will be in both 'source' and 'binary' releases.) These must also be handled in a separate LICENSE and NOTICE file for the binary release. # Binary Release License ## Transitive Maven Dependencies We'll first tackle the binary release, and that almost entirely means assessing the transitive dependencies of the Scala/Java backbone of Spark. Run `project-info-reports:dependencies` with essentially all profiles: a set that would bring in all different possible transitive dependencies. However, don't activate any of the '-lgpl' profiles as these would bring in LGPL-licensed dependencies that are explicitly excluded from Spark binary releases. ``` mvn -Phadoop-2.7 -Pyarn -Phive -Pmesos -Pkubernetes -Pflume -Pkinesis-asl -Pdocker-integration-tests -Phive-thriftserver -Pkafka-0-8 -Ddependency.locations.enabled=false project-info-reports:dependencies ``` Open `assembly/target/site/dependencies.html`. Find "Project Transitive Dependencies", and find "compile" and "runtime" (if exists). This is a list of all the dependencies that Spark is going to ship in its binary "assembly" distro and therefore whose licenses need to be appropriately considered in LICENSE and NOTICE. Copy this table into a spreadsheet for easy management. Next job is to fill in some blanks, as a few projects will not have clearly declared their licenses in a POM. Sort by license. This is a good time to verify all the dependencies are at least Cat A/B licenses, and not Cat X! http://www.apache.org/legal/resolved.html ### Apache License 2 The Apache License 2 variants are typically easiest to deal with as they will not require you to modify LICENSE, nor add to license/. It's still good form to list the ALv2 dependencies in LICENSE for completeness, but optional. They may require you to propagate bits from NOTICE. It's tedious to track down all the NOTICE files and evaluate what if anything needs to be copied to NOTICE. Fortunately, this can be made easier as the assembly module can be temporarily modified to produce a NOTICE file that concatenates all NOTICE files bundled with transitive dependencies. First change the packaging of `assembly/spark-assembly_2.11/pom.xml` to `<packaging>jar</packaging>`. Next add this stanza somewhere in the body of the same POM file: ``` <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <configuration> <shadedArtifactAttached>false</shadedArtifactAttached> <artifactSet> <includes> <include>*:*</include> </includes> </artifactSet> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ApacheNoticeResourceTransformer"/> </transformers> </configuration> </execution> </executions> </plugin> ``` Finally execute `mvn ... package` with all of the same `-P` profile flags as above. In the JAR file at `assembly/target/spark-assembly_2.11....jar` you'll find a file `META-INF/NOTICE` that concatenates all NOTICE files bundled with transitive dependencies. This should be the starting point for the binary release's NOTICE file. Some elements in the file are from Spark itself, like: ``` Spark Project Assembly Copyright 2018 The Apache Software Foundation Spark Project Core Copyright 2018 The Apache Software Foundation ``` These can be removed. Remove elements of the combined NOTICE file that aren't relevant to Spark. It's actually rare that we are sure that some element is completely irrelevant to Spark, because each transitive dependency includes all its transitive dependencies. So there may be nothing that can be done here. Of course, some projects may not publish NOTICE in their Maven artifacts. Ideally, search for the NOTICE file of projects that don't seem to have produced any text in NOTICE, but, there is some argument that projects that don't produce a NOTICE in their Maven artifacts don't entail an obligation on projects that depend solely on their Maven artifacts. ### Other Licenses Next are "Cat A" permissively licensed (BSD 2-Clause, BSD 3-Clause, MIT) components. List the components grouped by their license type in LICENSE. Then add the text of the license to licenses/. For example if you list "foo bar" as a BSD-licensed dependency, add its license text as licenses/LICENSE-foo-bar.txt. Public domain and similar works are treated like permissively licensed dependencies. And the same goes for all Cat B licenses too, like CDDL. However these additional require at least a URL pointer to the project's page. Use the artifact hyperlink in your spreadsheet if possible; if non-existent or doesn't resolve, do your best to determine a URL for the project's source. ### Shaded third-party dependencies Some third party dependencies actually copy in other dependencies rather than depend on them as Maven artifacts. This means they don't show up in the process above. These can be quite hard to track down, but are rare. A key example is reflectasm, embedded in kryo. ### Examples module The above _almost_ considers everything bundled in a Spark binary release. The main assembly won't include examples. The same must be done for dependencies marked as 'compile' for the examples module. See `examples/target/site/dependencies.html`. At the time of this writing however this just adds one dependency: `scopt`. ### provided scope Above we considered just compile and runtime scope dependencies, which makes sense as they are the ones that are packaged. However, for complicated reasons (shading), a few components that Spark does bundle are not marked as compile dependencies in the assembly. Therefore it's also necessary to consider 'provided' dependencies from `assembly/target/site/dependencies.html` actually! Right now that's just Jetty and JPMML artifacts. ## Python, R Don't forget that Py4J is also distributed in the binary release, actually. There should be no other R, Python code in the binary release. That's it. ## Sense checking Compare the contents of `jars/`, `examples/jars/` and `python/lib` from a recent binary release to see if anything appears there that doesn't seem to have been covered above. These additional components will have to be handled manually, but should be few or none of this type. # Source Release License While there are relatively fewer third-party source artifacts included as source code, there is no automated way to detect it, really. It requires some degree of manual auditing. Most third party source comes from included JS and CSS files. At the time of this writing, some places to look or consider: `build/sbt-launch-lib.bash`, `python/lib`, third party source in `python/pyspark` like `heapq3.py`, `docs/js/vendor`, and `core/src/main/resources/org/apache/spark/ui/static`. The principles are the same as above. Remember some JS files copy in other JS files! Look out for Modernizr. # One More Thing: JS and CSS in Binary Release Now that you've got a handle on source licenses, recall that all the JS and CSS source code will *also* be part of the binary release. Copy that info from source to binary license files accordingly. Author: Sean Owen <srowen@gmail.com> Closes #21640 from srowen/SPARK-24654.
-
- 26 6月, 2018 1 次提交
-
-
由 DB Tsai 提交于
## What changes were proposed in this pull request? Scala is upgraded to `2.11.12` and `2.12.6`. We used `loadFIles()` in `ILoop` as a hook to initialize the Spark before REPL sees any files in Scala `2.11.8`. However, it was a hack, and it was not intended to be a public API, so it was removed in Scala `2.11.12`. From the discussion in Scala community, https://github.com/scala/bug/issues/10913 , we can use `initializeSynchronous` to initialize Spark instead. This PR implements the Spark initialization there. However, in Scala `2.11.12`'s `ILoop.scala`, in function `def startup()`, the first thing it calls is `printWelcome()`. As a result, Scala will call `printWelcome()` and `splash` before calling `initializeSynchronous`. Thus, the Spark shell will allow users to type commends first, and then show the Spark UI URL. It's working, but it will change the Spark Shell interface as the following. ```scala ➜ apache-spark git:(scala-2.11.12) ✗ ./bin/spark-shell Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0-SNAPSHOT /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161) Type in expressions to have them evaluated. Type :help for more information. scala> Spark context Web UI available at http://192.168.1.169:4040 Spark context available as 'sc' (master = local[*], app id = local-1528180279528). Spark session available as 'spark'. scala> ``` It seems there is no easy way to inject the Spark initialization code in the proper place as Scala doesn't provide a hook. Maybe som-snytt can comment on this. The following command is used to update the dep files. ```scala ./dev/test-dependencies.sh --replace-manifest ``` ## How was this patch tested? Existing tests Author: DB Tsai <d_tsai@apple.com> Closes #21495 from dbtsai/scala-2.11.12.
-
- 15 6月, 2018 1 次提交
-
-
由 mcheah 提交于
## What changes were proposed in this pull request? Previously, the scheduler backend was maintaining state in many places, not only for reading state but also writing to it. For example, state had to be managed in both the watch and in the executor allocator runnable. Furthermore, one had to keep track of multiple hash tables. We can do better here by: 1. Consolidating the places where we manage state. Here, we take inspiration from traditional Kubernetes controllers. These controllers tend to follow a level-triggered mechanism. This means that the controller will continuously monitor the API server via watches and polling, and on periodic passes, the controller will reconcile the current state of the cluster with the desired state. We implement this by introducing the concept of a pod snapshot, which is a given state of the executors in the Kubernetes cluster. We operate periodically on snapshots. To prevent overloading the API server with polling requests to get the state of the cluster (particularly for executor allocation where we want to be checking frequently to get executors to launch without unbearably bad latency), we use watches to populate snapshots by applying observed events to a previous snapshot to get a new snapshot. Whenever we do poll the cluster, the polled state replaces any existing snapshot - this ensures eventual consistency and mirroring of the cluster, as is desired in a level triggered architecture. 2. Storing less specialized in-memory state in general. Previously we were creating hash tables to represent the state of executors. Instead, it's easier to represent state solely by the snapshots. ## How was this patch tested? Integration tests should test there's no regressions end to end. Unit tests to be updated, in particular focusing on different orderings of events, particularly accounting for when events come in unexpected ordering. Author: mcheah <mcheah@palantir.com> Closes #21366 from mccheah/event-queue-driven-scheduling.
-
- 10 5月, 2018 1 次提交
-
-
由 Marcelo Vanzin 提交于
-
- 01 11月, 2017 1 次提交
-
-
由 Sital Kedia 提交于
## What changes were proposed in this pull request? Using zstd compression for Spark jobs spilling 100s of TBs of data, we could reduce the amount of data written to disk by as much as 50%. This translates to significant latency gain because of reduced disk io operations. There is a degradation CPU time by 2 - 5% because of zstd compression overhead, but for jobs which are bottlenecked by disk IO, this hit can be taken. ## Benchmark Please note that this benchmark is using real world compute heavy production workload spilling TBs of data to disk | | zstd performance as compred to LZ4 | | ------------- | -----:| | spill/shuffle bytes | -48% | | cpu time | + 3% | | cpu reservation time | -40%| | latency | -40% | ## How was this patch tested? Tested by running few jobs spilling large amount of data on the cluster and amount of intermediate data written to disk reduced by as much as 50%. Author: Sital Kedia <skedia@fb.com> Closes #18805 from sitalkedia/skedia/upstream_zstd.
-
- 06 7月, 2017 1 次提交
-
-
由 Dongjoon Hyun 提交于
## What changes were proposed in this pull request? This PR aims to bump Py4J in order to fix the following float/double bug. Py4J 0.10.5 fixes this (https://github.com/bartdag/py4j/issues/272) and the latest Py4J is 0.10.6. **BEFORE** ``` >>> df = spark.range(1) >>> df.select(df['id'] + 17.133574204226083).show() +--------------------+ |(id + 17.1335742042)| +--------------------+ | 17.1335742042| +--------------------+ ``` **AFTER** ``` >>> df = spark.range(1) >>> df.select(df['id'] + 17.133574204226083).show() +-------------------------+ |(id + 17.133574204226083)| +-------------------------+ | 17.133574204226083| +-------------------------+ ``` ## How was this patch tested? Manual. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #18546 from dongjoon-hyun/SPARK-21278.
-
- 19 5月, 2017 1 次提交
-
-
由 liuzhaokun 提交于
[https://issues.apache.org/jira/browse/SPARK-20759](https://issues.apache.org/jira/browse/SPARK-20759) SCALA_VERSION in _config.yml is 2.11.7, but 2.11.8 in pom.xml. So I think SCALA_VERSION in _config.yml should be consistent with pom.xml. Author: liuzhaokun <liu.zhaokun@zte.com.cn> Closes #17992 from liu-zhaokun/new.
-
- 26 4月, 2017 1 次提交
-
-
由 Yanbo Liang 提交于
## What changes were proposed in this pull request? Upgrade breeze version to 0.13.1, which fixed some critical bugs of L-BFGS-B. ## How was this patch tested? Existing unit tests. Author: Yanbo Liang <ybliang8@gmail.com> Closes #17746 from yanboliang/spark-20449.
-
- 21 10月, 2016 1 次提交
-
-
由 Jagadeesan 提交于
## What changes were proposed in this pull request? 1) Upgrade the Py4J version on the Java side 2) Update the py4j src zip file we bundle with Spark ## How was this patch tested? Existing doctests & unit tests pass Author: Jagadeesan <as2@us.ibm.com> Closes #15514 from jagadeesanas2/SPARK-17960.
-
- 25 8月, 2016 1 次提交
-
-
由 Sean Owen 提交于
[SPARK-16781][PYSPARK] java launched by PySpark as gateway may not be the same java used in the spark environment ## What changes were proposed in this pull request? Update to py4j 0.10.3 to enable JAVA_HOME support ## How was this patch tested? Pyspark tests Author: Sean Owen <sowen@cloudera.com> Closes #14748 from srowen/SPARK-16781.
-
- 05 6月, 2016 1 次提交
-
-
由 Sean Owen 提交于
## What changes were proposed in this pull request? Per conversation on dev list, add missing modernizr license. Specify "2014 and onwards" in copyright statement. ## How was this patch tested? (none required) Author: Sean Owen <sowen@cloudera.com> Closes #13510 from srowen/ModernizrLicense.
-
- 13 5月, 2016 1 次提交
-
-
由 Holden Karau 提交于
## What changes were proposed in this pull request? This upgrades to Py4J 0.10.1 which reduces syscal overhead in Java gateway ( see https://github.com/bartdag/py4j/issues/201 ). Related https://issues.apache.org/jira/browse/SPARK-6728 . ## How was this patch tested? Existing doctests & unit tests pass Author: Holden Karau <holden@us.ibm.com> Closes #13064 from holdenk/SPARK-15061-upgrade-to-py4j-0.10.1.
-
- 09 4月, 2016 1 次提交
-
-
由 Josh Rosen 提交于
This patch upgrades Chill to 0.8.0 and Kryo to 3.0.3. While we'll likely need to bump these dependencies again before Spark 2.0 (due to SPARK-14221 / https://github.com/twitter/chill/issues/252), I wanted to get the bulk of the Kryo 2 -> Kryo 3 migration done now in order to figure out whether there are any unexpected surprises. Author: Josh Rosen <joshrosen@databricks.com> Closes #12076 from JoshRosen/kryo3.
-
- 29 3月, 2016 1 次提交
-
-
由 Herman van Hovell 提交于
### What changes were proposed in this pull request? The current ANTLR3 parser is quite complex to maintain and suffers from code blow-ups. This PR introduces a new parser that is based on ANTLR4. This parser is based on the [Presto's SQL parser](https://github.com/facebook/presto/blob/master/presto-parser/src/main/antlr4/com/facebook/presto/sql/parser/SqlBase.g4). The current implementation can parse and create Catalyst and SQL plans. Large parts of the HiveQl DDL and some of the DML functionality is currently missing, the plan is to add this in follow-up PRs. This PR is a work in progress, and work needs to be done in the following area's: - [x] Error handling should be improved. - [x] Documentation should be improved. - [x] Multi-Insert needs to be tested. - [ ] Naming and package locations. ### How was this patch tested? Catalyst and SQL unit tests. Author: Herman van Hovell <hvanhovell@questtec.nl> Closes #11557 from hvanhovell/ngParser.
-
- 15 3月, 2016 1 次提交
-
-
由 Josh Rosen 提交于
This patch upgrades Py4J from 0.9.1 to 0.9.2 in order to include a patch which modifies Py4J to use the current thread's ContextClassLoader when performing reflection / class loading. This is necessary in order to fix [SPARK-5185](https://issues.apache.org/jira/browse/SPARK-5185), a longstanding issue affecting the use of `--jars` and `--packages` in PySpark. In order to demonstrate that the fix works, I removed the workarounds which were added as part of [SPARK-6027](https://issues.apache.org/jira/browse/SPARK-6027) / #4779 and other patches. Py4J diff: https://github.com/bartdag/py4j/compare/0.9.1...0.9.2 /cc zsxwing tdas davies brkyvz Author: Josh Rosen <joshrosen@databricks.com> Closes #11687 from JoshRosen/py4j-0.9.2.
-
- 09 3月, 2016 1 次提交
-
-
由 Sean Owen 提交于
## What changes were proposed in this pull request? Remove last usage of jblas, in tests ## How was this patch tested? Jenkins tests -- the same ones that are being modified. Author: Sean Owen <sowen@cloudera.com> Closes #11560 from srowen/SPARK-13715.
-
- 10 2月, 2016 1 次提交
-
-
由 Luciano Resende 提交于
Author: Luciano Resende <lresende@apache.org> Closes #11092 from lresende/SPARK-13189.
-
- 30 1月, 2016 1 次提交
-
-
由 zhuol 提交于
[SPARK-10873] Support column sort and search for History Server using jQuery DataTable and REST API. Before this commit, the history server was generated hard-coded html and can not support search, also, the sorting was disabled if there is any application that has more than one attempt. Supporting search and sort (over all applications rather than the 20 entries in the current page) in any case will greatly improve user experience. 1. Create the historypage-template.html for displaying application information in datables. 2. historypage.js uses jQuery to access the data from /api/v1/applications REST API, and use DataTable to display each application's information. For application that has more than one attempt, the RowsGroup is used to merge such entries while at the same time supporting sort and search. 3. "duration" and "lastUpdated" rest API are added to application's "attempts". 4. External javascirpt and css files for datatables, RowsGroup and jquery plugins are added with licenses clarified. Snapshots for how it looks like now: History page view:  Search:  Sort by started time:  Author: zhuol <zhuol@yahoo-inc.com> Closes #10648 from zhuoliu/10873.
-
- 13 1月, 2016 1 次提交
-
-
由 Shixiong Zhu 提交于
- [x] Upgrade Py4J to 0.9.1 - [x] SPARK-12657: Revert SPARK-12617 - [x] SPARK-12658: Revert SPARK-12511 - Still keep the change that only reading checkpoint once. This is a manual change and worth to take a look carefully. https://github.com/zsxwing/spark/commit/bfd4b5c040eb29394c3132af3c670b1a7272457c - [x] Verify no leak any more after reverting our workarounds Author: Shixiong Zhu <shixiong@databricks.com> Closes #10692 from zsxwing/py4j-0.9.1.
-
- 05 12月, 2015 1 次提交
-
-
由 Sean Owen 提交于
Update JPMML pmml-model to 1.2.7 Author: Sean Owen <sowen@cloudera.com> Closes #9972 from srowen/SPARK-11988.
-
- 05 11月, 2015 1 次提交
-
-
由 Josh Rosen 提交于
Spark should build against Scala 2.10.5, since that includes a fix for Scaladoc that will fix doc snapshot publishing: https://issues.scala-lang.org/browse/SI-8479 Author: Josh Rosen <joshrosen@databricks.com> Closes #9450 from JoshRosen/upgrade-to-scala-2.10.5.
-
- 21 10月, 2015 1 次提交
-
-
由 Holden Karau 提交于
Upgrade to Py4j0.9 Author: Holden Karau <holden@pigscanfly.ca> Author: Holden Karau <holden@us.ibm.com> Closes #8615 from holdenk/SPARK-10447-upgrade-pyspark-to-py4j0.9.
-
- 29 9月, 2015 1 次提交
-
-
由 Sean Owen 提交于
In the course of https://issues.apache.org/jira/browse/LEGAL-226 it came to light that the guidance at http://www.apache.org/dev/licensing-howto.html#permissive-deps means that permissively-licensed dependencies has a different interpretation than we (er, I) had been operating under. "pointer ... to the license within the source tree" specifically means a copy of the license within Spark's distribution, whereas at the moment, Spark's LICENSE has a pointer to the project's license in the other project's source tree. The remedy is simply to inline all such license references (i.e. BSD/MIT licenses) or include their text in "licenses" subdirectory and point to that. Along the way, we can also treat other BSD/MIT licenses, whose text has been inlined into LICENSE, in the same way. The LICENSE file can continue to provide a helpful list of BSD/MIT licensed projects and a pointer to their sites. This would be over and above including license text in the distro, which is the essential thing. Author: Sean Owen <sowen@cloudera.com> Closes #8919 from srowen/SPARK-10833.
-
- 30 6月, 2015 1 次提交
-
-
由 Josh Rosen 提交于
This patch excludes `hadoop-client`'s dependency on `mockito-all`. As of #7061, Spark depends on `mockito-core` instead of `mockito-all`, so the dependency from Hadoop was leading to test compilation failures for some of the Hadoop 2 SBT builds. Author: Josh Rosen <joshrosen@databricks.com> Closes #7090 from JoshRosen/SPARK-8709 and squashes the following commits: e190122 [Josh Rosen] [SPARK-8709] Exclude hadoop-client's mockito-all dependency.
-
- 28 6月, 2015 1 次提交
-
-
由 Josh Rosen 提交于
Spark's tests currently depend on `mockito-all`, which bundles Hamcrest and Objenesis classes. Instead, it should depend on `mockito-core`, which declares those libraries as Maven dependencies. This is necessary in order to fix a dependency conflict that leads to a NoSuchMethodError when using certain Hamcrest matchers. See https://github.com/mockito/mockito/wiki/Declaring-mockito-dependency for more details. Author: Josh Rosen <joshrosen@databricks.com> Closes #7061 from JoshRosen/mockito-core-instead-of-all and squashes the following commits: 70eccbe [Josh Rosen] Depend on mockito-core instead of mockito-all.
-
- 19 6月, 2015 1 次提交
-
-
由 Josh Rosen 提交于
This patch uses [AnchorJS](https://bryanbraun.github.io/anchorjs/) to show deep anchor links when hovering over headers in the Spark documentation. For example:  This makes it easier for users to link to specific sections of the documentation. I also removed some dead Javascript which isn't used in our current docs (it was introduced for the old AMPCamp training, but isn't used anymore). Author: Josh Rosen <joshrosen@databricks.com> Closes #6808 from JoshRosen/SPARK-8353 and squashes the following commits: e59d8a7 [Josh Rosen] Suppress underline on hover f518b6a [Josh Rosen] Turn on for all headers, since we use H1s in a bunch of places a9fec01 [Josh Rosen] Add anchor links when hovering over headers; remove some dead JS code
-
- 01 6月, 2015 1 次提交
-
-
由 zsxwing 提交于
Add license for dagre-d3 and graphlib-dot Author: zsxwing <zsxwing@gmail.com> Closes #6539 from zsxwing/LICENSE and squashes the following commits: 82b0475 [zsxwing] Add license for dagre-d3 and graphlib-dot
-
- 17 5月, 2015 1 次提交
-
-
由 Matthew Brandyberry 提交于
jblas 1.2.4 includes native library support for PPC64LE. Author: Matthew Brandyberry <mbrandy@us.ibm.com> Closes #6199 from mtbrandy/jblas-1.2.4 and squashes the following commits: 9df9301 [Matthew Brandyberry] [BUILD] update jblas dependency version to 1.2.4
-
- 09 5月, 2015 1 次提交
-
-
由 Kousuke Saruta 提交于
When we use Spark on YARN and have AllJobPage via ResourceManager's proxy, the link URL in objects which represent each job on timeline view is wrong. In timeline-view.js, the link is generated as follows. ``` window.location.href = "job/?id=" + getJobId(this); ``` This assumes the URL displayed on the web browser ends with "jobs/" but when we access AllJobPage via the proxy, the url displayed does not end with "jobs/" The proxy doesn't return status code 301 or 302 so the url displayed still indicates the base url, not "/jobs" even though displaying AllJobPages.  Author: Kousuke Saruta <sarutak@oss.nttdata.co.jp> Closes #5947 from sarutak/fix-link-in-timeline and squashes the following commits: aaf40e1 [Kousuke Saruta] Added Copyright for vis.js 01bee7b [Kousuke Saruta] Fixed timeline-view.js in order to get correct href
-
- 06 5月, 2015 1 次提交
-
-
由 zsxwing 提交于
This is the initial work of SPARK-6939. Not yet ready for code review. Here are the screenshots:   TODOs: - [x] Display more information on mouse hover - [x] Align the timeline and distribution graphs - [x] Clean up the codes Author: zsxwing <zsxwing@gmail.com> Closes #5533 from zsxwing/SPARK-6939 and squashes the following commits: 9f7cd19 [zsxwing] Merge branch 'master' into SPARK-6939 deacc3f [zsxwing] Remove unused import cd03424 [zsxwing] Fix .rat-excludes 70cc87d [zsxwing] Streaming Scheduling Delay => Scheduling Delay d457277 [zsxwing] Fix UIUtils in BatchPage b3f303e [zsxwing] Add comments for unclear classes and methods ff0bff8 [zsxwing] Make InputDStream.name private[streaming] cc392c5 [zsxwing] Merge branch 'master' into SPARK-6939 e275e23 [zsxwing] Move time related methods to Streaming's UIUtils d5d86f6 [zsxwing] Fix incorrect lastErrorTime 3be4b7a [zsxwing] Use InputInfo b50fa32 [zsxwing] Jump to the batch page when clicking a point in the timeline graphs 203605d [zsxwing] Merge branch 'master' into SPARK-6939 74307cf [zsxwing] Reuse the data for histogram graphs to reduce the page size 2586916 [zsxwing] Merge branch 'master' into SPARK-6939 70d8533 [zsxwing] Remove BatchInfo.numRecords and a few renames 7bbdc0a [zsxwing] Hide the receiver sub table if no receiver a2972e9 [zsxwing] Add some ui tests for StreamingPage fd03ad0 [zsxwing] Add a test to verify no memory leak 4a8f886 [zsxwing] Merge branch 'master' into SPARK-6939 18607a1 [zsxwing] Merge branch 'master' into SPARK-6939 d0b0aec [zsxwing] Clean up the codes a459f49 [zsxwing] Add a dash line to processing time graphs 8e4363c [zsxwing] Prepare for the demo c81a1ee [zsxwing] Change time unit in the graphs automatically 4c0b43f [zsxwing] Update Streaming UI 04c7500 [zsxwing] Make the server and client use the same timezone fed8219 [zsxwing] Move the x axis at the top and show a better tooltip c23ce10 [zsxwing] Make two graphs close d78672a [zsxwing] Make the X axis use the same range 881c907 [zsxwing] Use histogram for distribution 5688702 [zsxwing] Fix the unit test ddf741a [zsxwing] Fix the unit test ad93295 [zsxwing] Remove unnecessary codes a0458f9 [zsxwing] Clean the codes b82ed1e [zsxwing] Update the graphs as per comments dd653a1 [zsxwing] Add timeline and histogram graphs for streaming statistics
-
- 30 4月, 2015 1 次提交
-
-
由 Vincenzo Selvaggio 提交于
See PDF attached to the JIRA issue 1406. The contribution is my original work and I license the work to the project under the project's open source license. Author: Vincenzo Selvaggio <vselvaggio@hotmail.it> Author: Xiangrui Meng <meng@databricks.com> Author: selvinsource <vselvaggio@hotmail.it> Closes #3062 from selvinsource/mllib_pmml_model_export_SPARK-1406 and squashes the following commits: 852aac6 [Vincenzo Selvaggio] [SPARK-1406] Update JPMML version to 1.1.15 in LICENSE file 085cf42 [Vincenzo Selvaggio] [SPARK-1406] Added Double Min and Max Fixed scala style 30165c4 [Vincenzo Selvaggio] [SPARK-1406] Fixed extreme cases for logit 7a5e0ec [Vincenzo Selvaggio] [SPARK-1406] Binary classification for SVM and Logistic Regression cfcb596 [Vincenzo Selvaggio] [SPARK-1406] Throw IllegalArgumentException when exporting a multinomial logistic regression 25dce33 [Vincenzo Selvaggio] [SPARK-1406] Update code to latest pmml model dea98ca [Vincenzo Selvaggio] [SPARK-1406] Exclude transitive dependency for pmml model 66b7c12 [Vincenzo Selvaggio] [SPARK-1406] Updated pmml model lib to 1.1.15, latest Java 6 compatible a0a55f7 [Vincenzo Selvaggio] Merge pull request #2 from mengxr/SPARK-1406 3c22f79 [Xiangrui Meng] more code style e2313df [Vincenzo Selvaggio] Merge pull request #1 from mengxr/SPARK-1406 472d757 [Xiangrui Meng] fix code style 1676e15 [Vincenzo Selvaggio] fixed scala issue e2ffae8 [Vincenzo Selvaggio] fixed scala style b8823b0 [Vincenzo Selvaggio] Merge remote-tracking branch 'upstream/master' into mllib_pmml_model_export_SPARK-1406 b25bbf7 [Vincenzo Selvaggio] [SPARK-1406] Added export of pmml to distributed file system using the spark context 7a949d0 [Vincenzo Selvaggio] [SPARK-1406] Fixed scala style f46c75c [Vincenzo Selvaggio] [SPARK-1406] Added PMMLExportable to supported models 7b33b4e [Vincenzo Selvaggio] [SPARK-1406] Added a PMMLExportable interface Restructured code in a new package mllib.pmml Supported models implements the new PMMLExportable interface: LogisticRegression, SVM, KMeansModel, LinearRegression, RidgeRegression, Lasso d559ec5 [Vincenzo Selvaggio] Merge remote-tracking branch 'upstream/master' into mllib_pmml_model_export_SPARK-1406 8fe12bb [Vincenzo Selvaggio] [SPARK-1406] Adjusted logistic regression export description and target categories 03bc3a5 [Vincenzo Selvaggio] added logistic regression da2ec11 [Vincenzo Selvaggio] [SPARK-1406] added linear SVM PMML export 82f2131 [Vincenzo Selvaggio] Merge remote-tracking branch 'upstream/master' into mllib_pmml_model_export_SPARK-1406 19adf29 [Vincenzo Selvaggio] [SPARK-1406] Fixed scala style 1faf985 [Vincenzo Selvaggio] [SPARK-1406] Added target field to the regression model for completeness Adjusted unit test to deal with this change 3ae8ae5 [Vincenzo Selvaggio] [SPARK-1406] Adjusted imported order according to the guidelines c67ce81 [Vincenzo Selvaggio] Merge remote-tracking branch 'upstream/master' into mllib_pmml_model_export_SPARK-1406 78515ec [Vincenzo Selvaggio] [SPARK-1406] added pmml export for LinearRegressionModel, RidgeRegressionModel and LassoModel e29dfb9 [Vincenzo Selvaggio] removed version, by default is set to 4.2 (latest from jpmml) removed copyright ae8b993 [Vincenzo Selvaggio] updated some commented tests to use the new ModelExporter object reordered the imports df8a89e [Vincenzo Selvaggio] added pmml version to pmml model changed the copyright to spark a1b4dc3 [Vincenzo Selvaggio] updated imports 834ca44 [Vincenzo Selvaggio] reordered the import accordingly to the guidelines 349a76b [Vincenzo Selvaggio] new helper object to serialize the models to pmml format c3ef9b8 [Vincenzo Selvaggio] set it to private 6357b98 [Vincenzo Selvaggio] set it to private e1eb251 [Vincenzo Selvaggio] removed serialization part, this will be part of the ModelExporter helper object aba5ee1 [Vincenzo Selvaggio] fixed cluster export cd6c07c [Vincenzo Selvaggio] fixed scala style to run tests f75b988 [Vincenzo Selvaggio] Merge remote-tracking branch 'origin/master' into mllib_pmml_model_export_SPARK-1406 07a29bf [selvinsource] Update LICENSE 8841439 [Vincenzo Selvaggio] adjust scala style in order to compile 1433b11 [Vincenzo Selvaggio] complete suite tests 8e71b8d [Vincenzo Selvaggio] kmeans pmml export implementation 9bc494f [Vincenzo Selvaggio] added scala suite tests added saveLocalFile to ModelExport trait 226e184 [Vincenzo Selvaggio] added javadoc and export model type in case there is a need to support other types of export (not just PMML) a0e3679 [Vincenzo Selvaggio] export and pmml export traits kmeans test implementation
-
- 01 3月, 2015 1 次提交
-
-
由 Evan Yu 提交于
Fix TimSort bug which causes a ArrayOutOfBoundsException. Using the proposed fix here http://envisage-project.eu/proving-android-java-and-python-sorting-algorithm-is-broken-and-how-to-fix-it/ Author: Evan Yu <ehotou@gmail.com> Closes #4804 from hotou/SPARK-5984 and squashes the following commits: 3421b6c [Evan Yu] SPARK-5984: Add info to LICENSE e61c6b8 [Evan Yu] SPARK-5984: Fix license and document 6ccc280 [Evan Yu] SPARK-5984: Add License header to file e06c0d2 [Evan Yu] SPARK-5984: Add License header to file 4d95f75 [Evan Yu] SPARK-5984: Fix TimSort bug causes ArrayOutOfBoundsException 479a106 [Evan Yu] SPARK-5984: Fix TimSort bug causes ArrayOutOfBoundsException
-
- 09 12月, 2014 1 次提交
-
-
由 Sean Owen 提交于
My original 'fix' didn't fix at all. Now, there's a unit test to check whether it works. Of the two options to really fix it -- copy the `Map` to a `java.util.HashMap`, or copy and modify Scala's implementation in `Wrappers.MapWrapper`, I went with the latter. Author: Sean Owen <sowen@cloudera.com> Closes #3587 from srowen/SPARK-3926 and squashes the following commits: 8586bb9 [Sean Owen] Remove unneeded no-arg constructor, and add additional note about copied code in LICENSE 7bb0e66 [Sean Owen] Make SerializableMapWrapper actually serialize, and add unit test
-
- 06 11月, 2014 1 次提交
-
-
由 Aaron Davidson 提交于
Does three things: (1) Adds SASL to ExternalShuffleClient, (2) puts SecurityManager in BlockManager's constructor, and (3) adds unit test. Author: Aaron Davidson <aaron@databricks.com> Closes #3108 from aarondav/sasl-client and squashes the following commits: 48b622d [Aaron Davidson] Screw it, let's just get LimitedInputStream 3543b70 [Aaron Davidson] Back out of pom change due to unknown test issue? b58518a [Aaron Davidson] ByteStreams.limit() not available :( cbe451a [Aaron Davidson] Address comments 2bf2908 [Aaron Davidson] [SPARK-4242] [Core] Add SASL to external shuffle service
-