docs: add hystrix-semphore-isolation, fix #12
- Add hystrix-semphore-isolation.md - Update RabbitMQ, fix #12 - Fix typo
Showing
{kind=link}
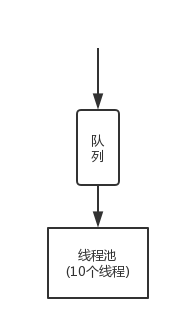
5.1 KB
img/hystrix-thread-pool-queue.png
0 → 100644
{kind=link}
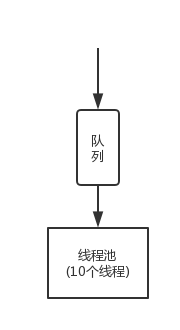
5.1 KB
从无法访问的项目Fork
- Add hystrix-semphore-isolation.md - Update RabbitMQ, fix #12 - Fix typo
5.1 KB
5.1 KB