Finish Automata
Showing
Automata/README.md
0 → 100644
Automata/imgs/Question3.png
0 → 100644
{kind=link}

118.3 KB
Automata/imgs/Question4.png
0 → 100644
{kind=link}
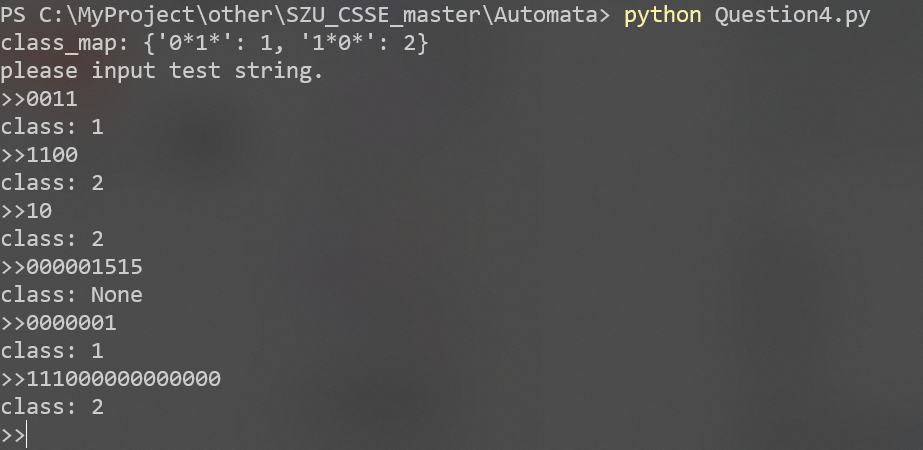
321.4 KB
Automata/imgs/closure.png
0 → 100644
{kind=link}
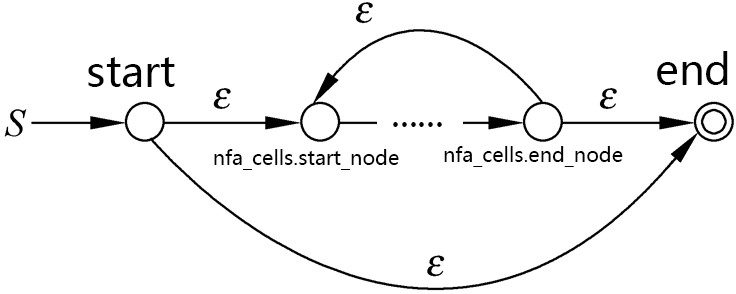
39.1 KB
Automata/imgs/connect.png
0 → 100644
{kind=link}

32.0 KB
Automata/imgs/example.png
0 → 100644
{kind=link}

99.5 KB
Automata/imgs/or.png
0 → 100644
{kind=link}

37.2 KB
Automata/imgs/term.png
0 → 100644
{kind=link}
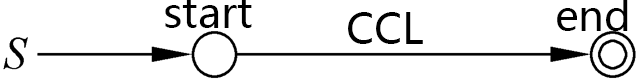
22.7 KB
Automata/solution.md
已删除
100644 → 0