大数据。
Showing
BigData/CDH.md
0 → 100644
BigData/Spark-Info.md
0 → 100644
BigData/Spark-VS-Flink.md
0 → 100644
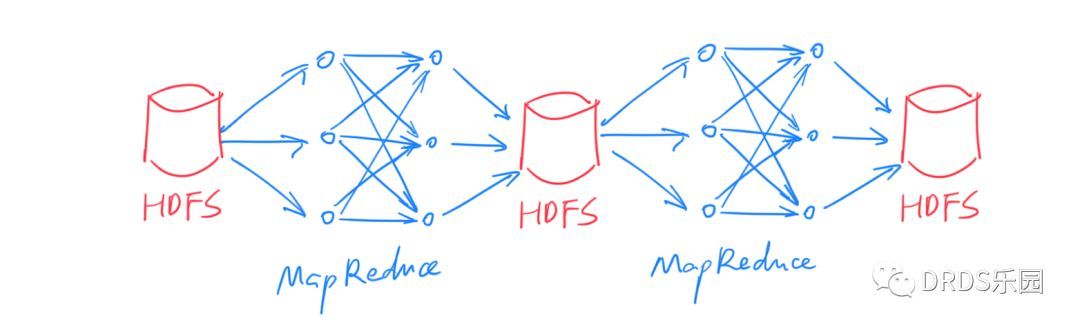
BigData/img/map-reduce.jpeg
0 → 100644
{kind=link}
34.2 KB
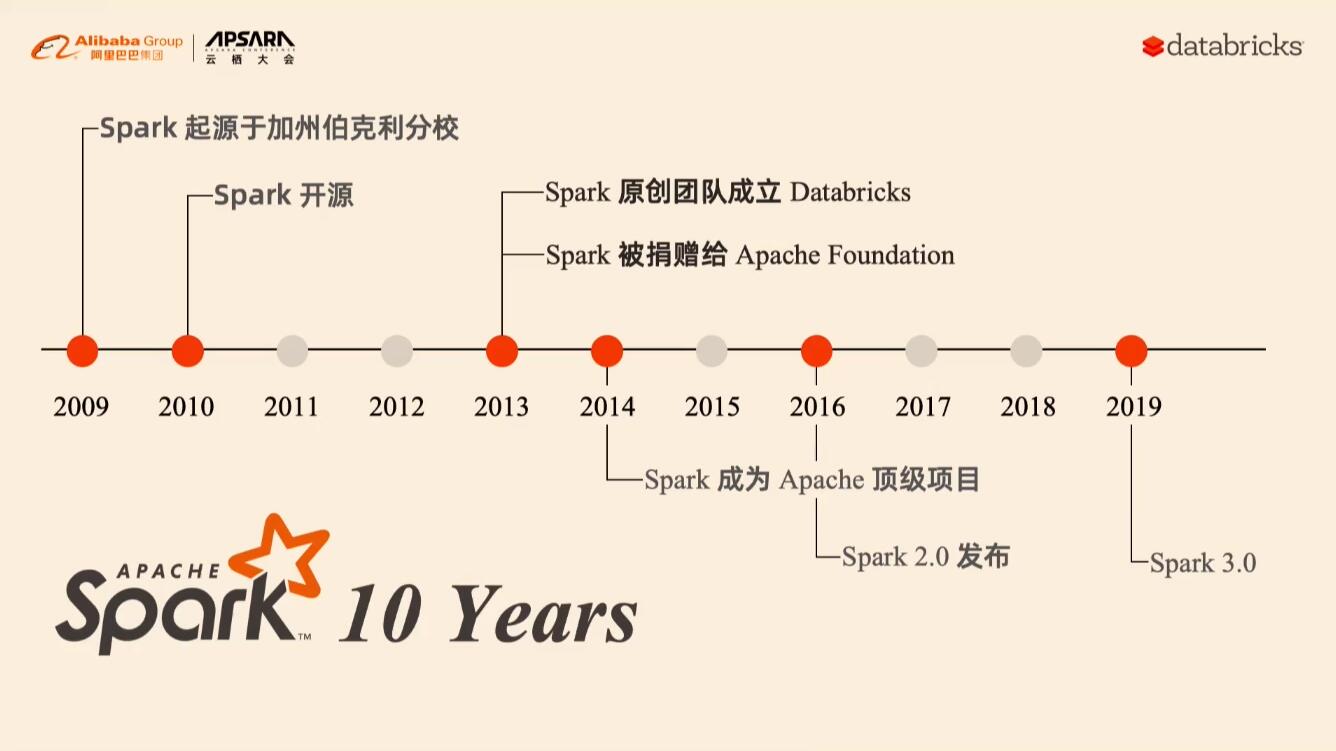
BigData/img/spark-a.jpg
0 → 100644
{kind=link}
50.4 KB
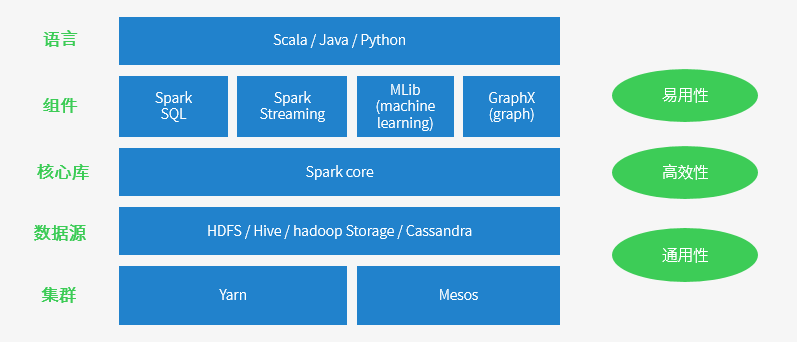
BigData/img/spark-a1.png
0 → 100644
{kind=link}
25.4 KB
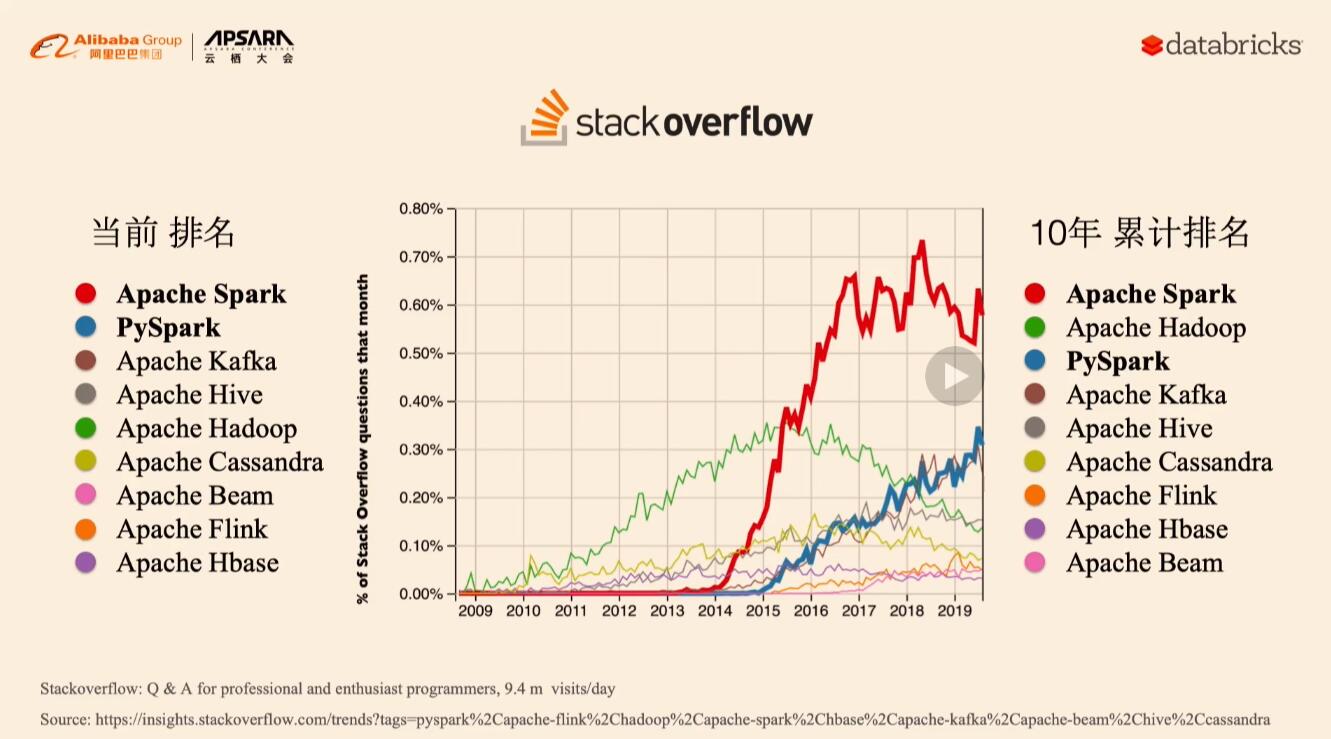
BigData/img/spark-b.jpg
0 → 100644
{kind=link}
90.6 KB
BigData/img/spark-c.jpg
0 → 100644
{kind=link}
58.0 KB
BigData/img/spark-d-3.0.jpg
0 → 100644
{kind=link}

50.0 KB
BigData/img/spark-rdd-2.jpeg
0 → 100644
{kind=link}
23.3 KB
BigData/img/spark-rdd.jpeg
0 → 100644
{kind=link}
17.1 KB
BigData/img/spark-sql-1.jpeg
0 → 100644
{kind=link}
29.7 KB
BigData/img/spark-sql-2.jpeg
0 → 100644
{kind=link}
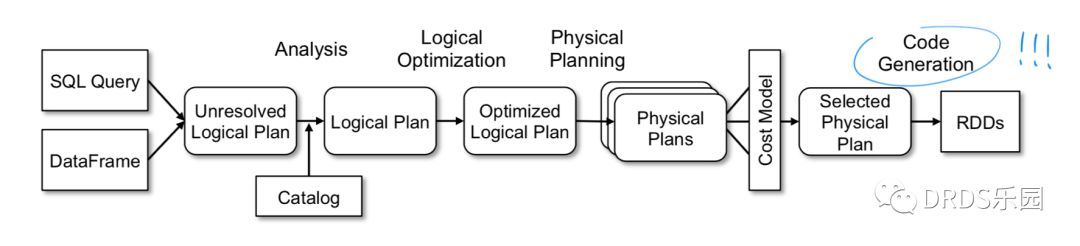
32.1 KB
BigData/img/spark-straming-1.jpeg
0 → 100644
{kind=link}

31.3 KB
BigData/img/spark-straming-2.jpeg
0 → 100644
{kind=link}
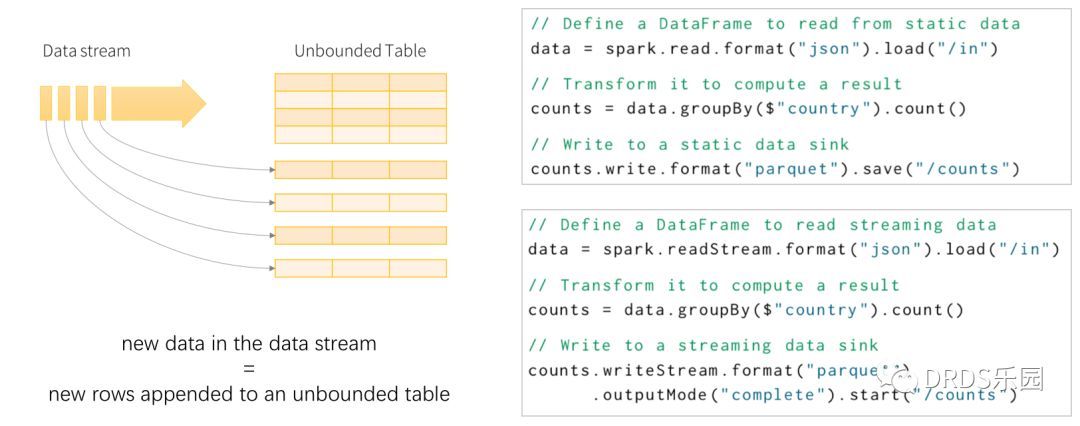
59.6 KB
{kind=link}

10.8 KB
{kind=link}
17.7 KB
{kind=link}
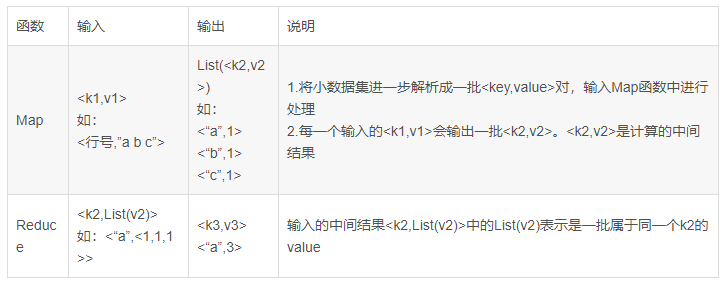
22.6 KB
{kind=link}
91.1 KB
{kind=link}
86.6 KB
{kind=link}
84.8 KB
{kind=link}
76.4 KB
BigData/什么是Hadoop为什么是Spark.md
0 → 100644
MachineLearning/Audio.md
0 → 100644
articles/天文地理.md
0 → 100644
articles/技术债.md
0 → 100644