update documents (#740)
* update english documents * refactor zk client * update documents * update zkclient * update zkclient * update documents * add architecture-design * change i18n * update i18n * update english documents * add architecture-design * update english documents * update en-US documents * add architecture-design * update demo site
Showing
docs/en_US/1.0.4-release.md
0 → 100644
docs/en_US/1.0.5-release.md
0 → 100644
docs/en_US/SUMMARY.md
0 → 100644
文件已移动
docs/en_US/book.json
0 → 100644
文件已移动
{kind=link}
37.2 KB
docs/en_US/images/complement.png
0 → 100644
{kind=link}
358.8 KB
{kind=link}
508.8 KB
{kind=link}
548.9 KB
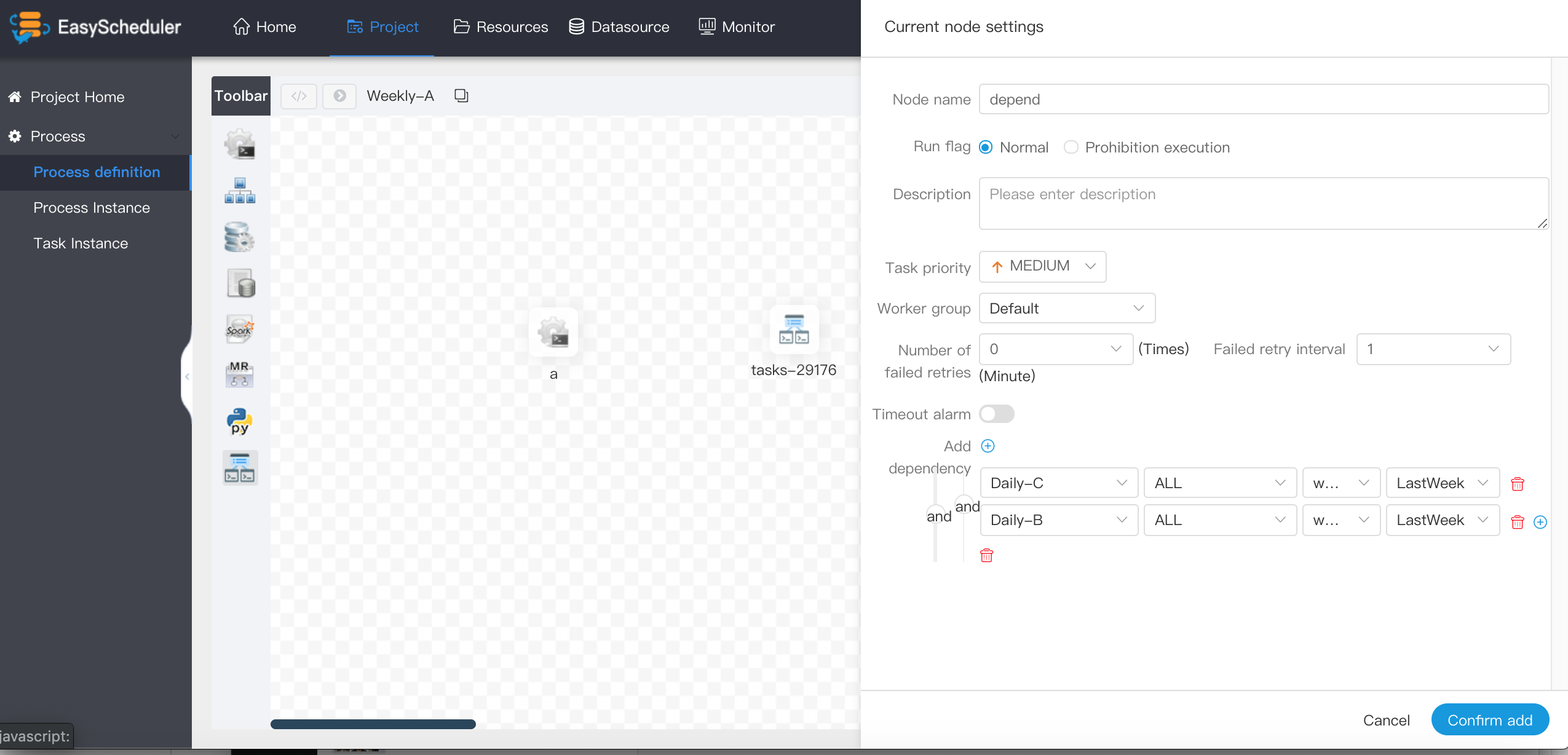
docs/en_US/images/depend-week.png
0 → 100644
{kind=link}
503.5 KB
{kind=link}
287.2 KB
{kind=link}
82.7 KB
{kind=link}
331.6 KB
docs/en_US/images/timing.png
0 → 100644
{kind=link}
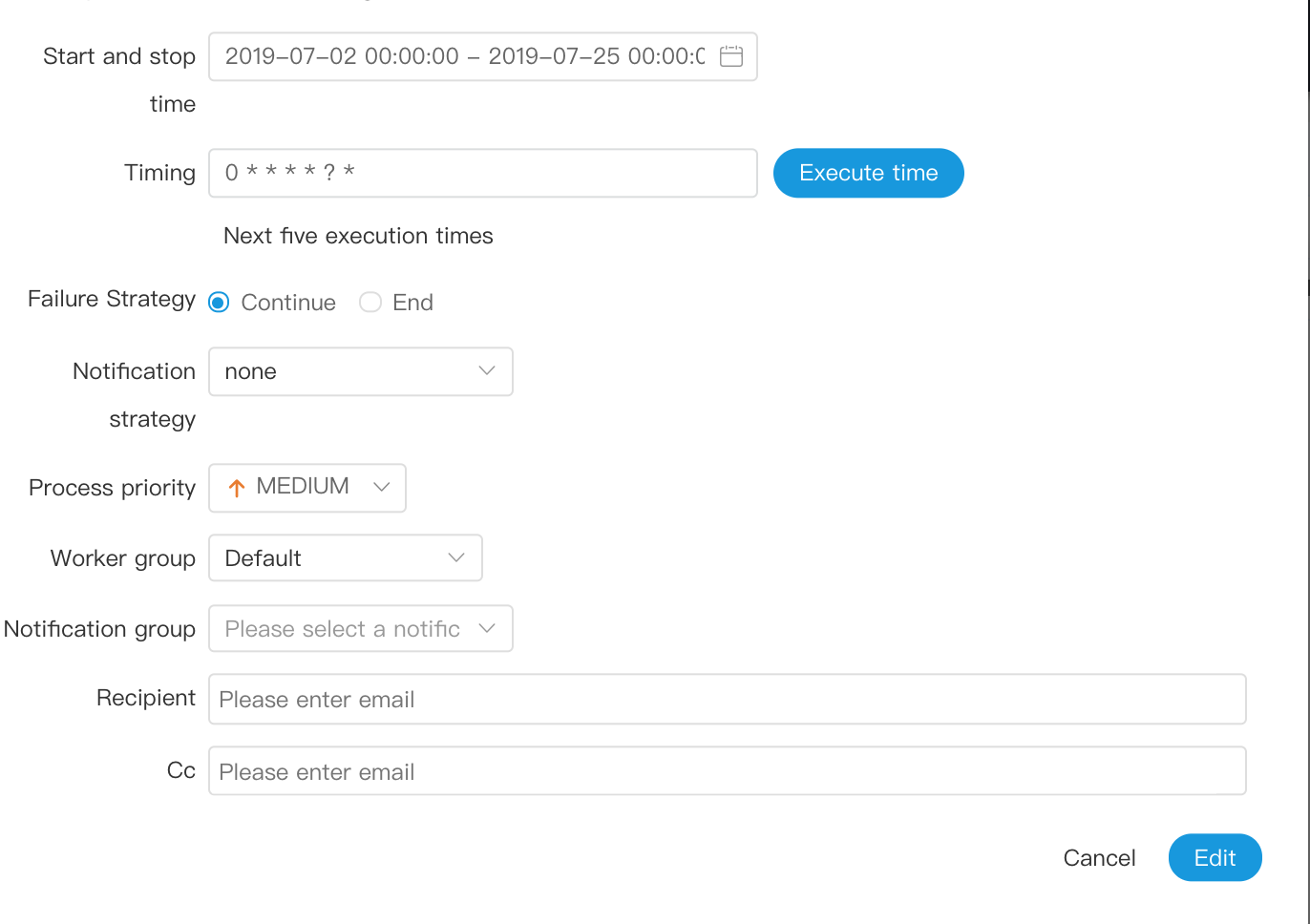
101.3 KB