[refractor]图片迁移
Showing
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
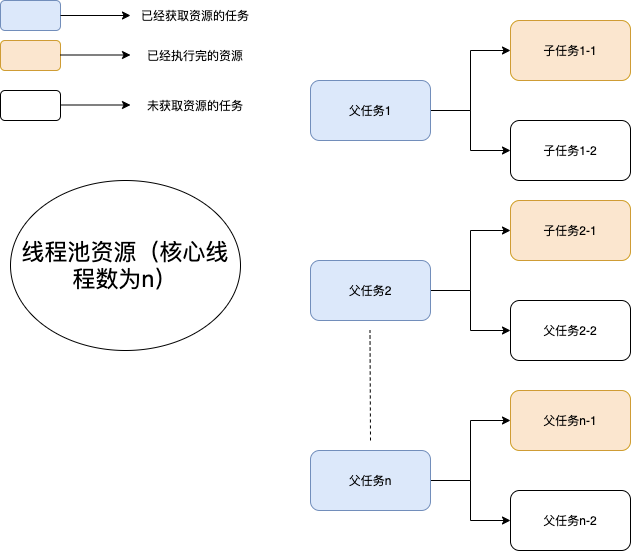
40.5 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}

116.3 KB
{kind=link}

127.9 KB
{kind=link}

75.9 KB
{kind=link}

107.1 KB
{kind=link}
553.6 KB
{kind=link}
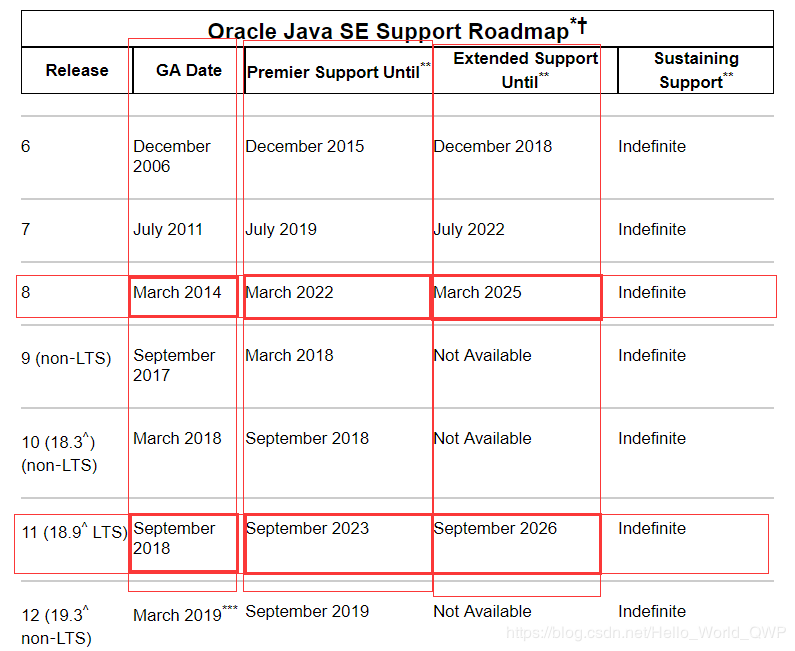
56.6 KB
{kind=link}

85.3 KB
{kind=link}
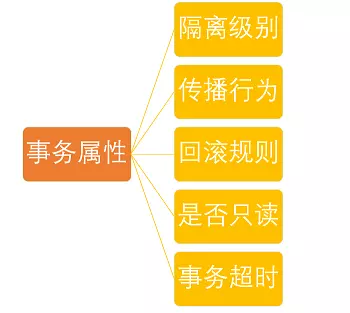
77.7 KB
{kind=link}

137.7 KB
{kind=link}
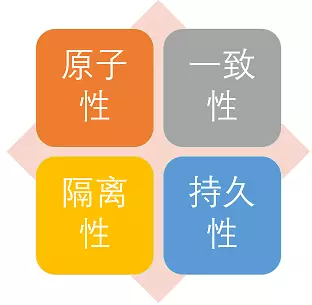
59.3 KB
{kind=link}

262.1 KB
{kind=link}
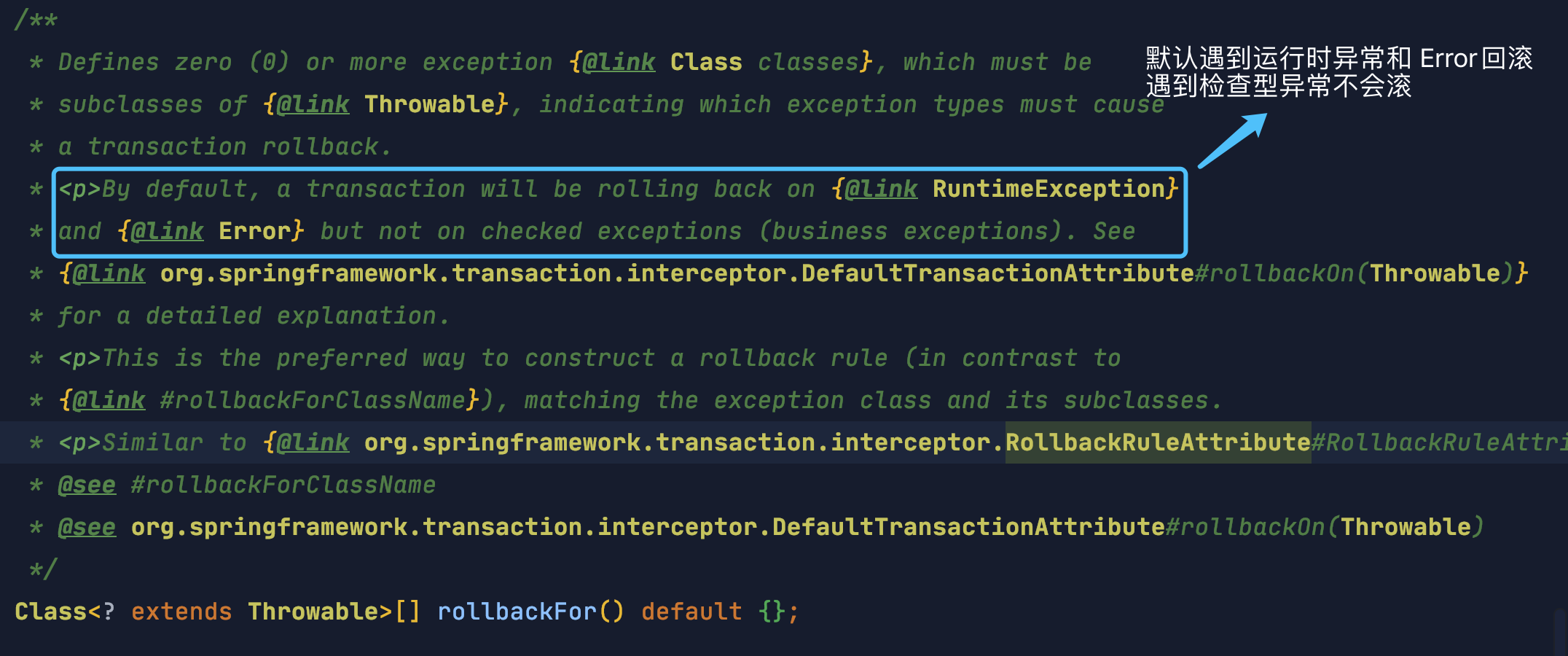
250.5 KB
{kind=link}
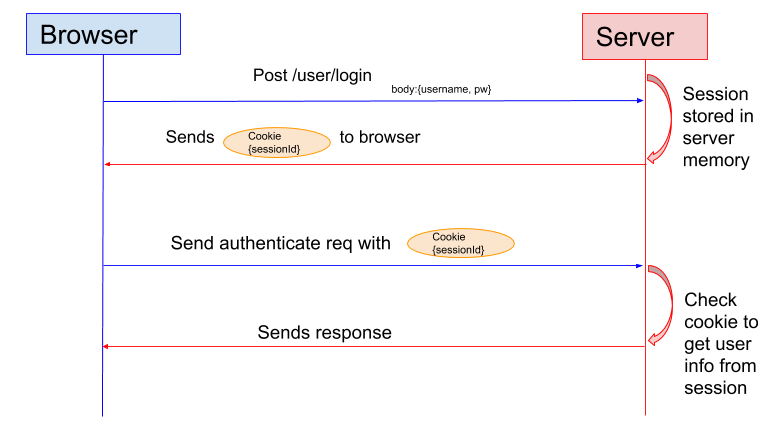
39.3 KB
{kind=link}
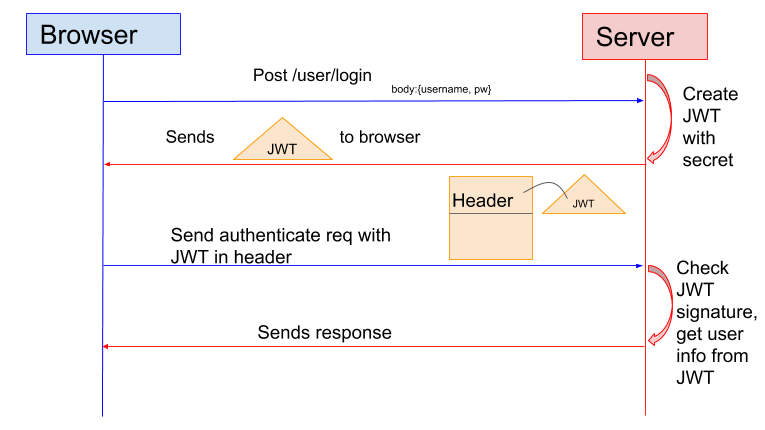
38.2 KB
{kind=link}
4.5 KB
{kind=link}
5.7 KB
{kind=link}
92.6 KB
{kind=link}
86.4 KB
{kind=link}
290.2 KB