Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
醒狮指南
JavaGuide
提交
c6402cde
J
JavaGuide
项目概览
醒狮指南
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
5
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
c6402cde
编写于
3月 10, 2020
作者:
S
shuang.kou
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[feat]目录和内容调整完善
上级
e734c459
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
132 addition
and
56 deletion
+132
-56
README.md
README.md
+14
-5
docs/system-design/micro-service/API网关.md
docs/system-design/micro-service/API网关.md
+46
-51
docs/system-design/micro-service/api-gateway-intro.md
docs/system-design/micro-service/api-gateway-intro.md
+37
-0
docs/system-design/micro-service/limit-request.md
docs/system-design/micro-service/limit-request.md
+35
-0
未找到文件。
README.md
浏览文件 @
c6402cde
...
...
@@ -61,9 +61,11 @@ Github用户如果访问速度缓慢的话,可以转移到[码云](https://git
-
[
RPC
](
#rpc
)
-
[
消息队列
](
#消息队列
)
-
[
API 网关
](
#api-网关
)
-
[
唯一 id 生成
](
#唯一-id-生成
)
-
[
ZooKeeper
](
#zookeeper
)
-
[
分布式id
](
#分布式id
)
-
[
分布式限流
](
#分布式限流
)
-
[
分布式接口幂等性
](
#分布式接口幂等性
)
-
[
数据库扩展
](
#数据库扩展
)
-
[
ZooKeeper
](
#zookeeper
)
-
[
大型网站架构
](
#大型网站架构
)
-
[
性能测试
](
#性能测试
)
-
[
高并发
](
#高并发
)
...
...
@@ -275,11 +277,18 @@ SSO(Single Sign On)即单点登录说的是用户登陆多个子系统的其中
网关主要用于请求转发、安全认证、协议转换、容灾。
-
[
浅析如何设计一个亿级网关(API Gateway)
](
docs/system-design/micro-service/API网关.md
)
1.
[
为什么要网关?你知道有哪些常见的网关系统?
](
docs/system-design/micro-service/api-gateway-intro.md
)
2.
[
如何设计一个亿级网关(API Gateway)?
](
docs/system-design/micro-service/API网关.md
)
#### 分布式id
1.
[
为什么要分布式 id ?分布式 id 生成方案有哪些?
](
docs/system-design/micro-service/分布式id生成方案总结.md
)
#### 分布式限流
#### 唯一 id 生成
1.
[
限流算法有哪些?
](
docs/system-design/micro-service/limit-request.md
)
-
[
分布式id生成方案总结
](
docs/system-design/micro-service/分布式id生成方案总结.md
)
#### 分布式接口幂等性
#### ZooKeeper
...
...
docs/system-design/micro-service/API网关.md
浏览文件 @
c6402cde
...
...
@@ -2,14 +2,11 @@
>
> 本文授权转载自:[https://github.com/javagrowing/JGrowing/blob/master/服务端开发/浅析如何设计一个亿级网关.md](https://github.com/javagrowing/JGrowing/blob/master/服务端开发/浅析如何设计一个亿级网关.md)。
## 1.背景
### 1.1 什么是API网关
# 1.背景
## 1.1 什么是API网关
API网关可以看做系统与外界联通的入口,我们可以在网关进行处理一些非业务逻辑的逻辑,比如权限验证,监控,缓存,请求路由等等。
### 1.2 为什么需要API网关
## 1.2 为什么需要API网关
-
RPC协议转成HTTP。
由于在内部开发中我们都是以RPC协议(thrift or dubbo)去做开发,暴露给内部服务,当外部服务需要使用这个接口的时候往往需要将RPC协议转换成HTTP协议。
...
...
@@ -31,9 +28,7 @@ API网关可以看做系统与外界联通的入口,我们可以在网关进
对于流量控制,熔断降级非业务逻辑可以统一放到网关层。
有很多业务都会自己去实现一层网关层,用来接入自己的服务,但是对于整个公司来说这还不够。
### 1.3 统一API网关
## 1.3 统一API网关
统一的API网关不仅有API网关的所有的特点,还有下面几个好处:
-
统一技术组件升级
...
...
@@ -48,10 +43,8 @@ API网关可以看做系统与外界联通的入口,我们可以在网关进
不同业务不同部门如果按照我们上面的做法应该会都自己搞一个网关层,用来做这个事,可以想象如果一个公司有100个这种业务,每个业务配备4台机器,那么就需要400台机器。并且每个业务的开发RD都需要去开发这个网关层,去随时去维护,增加人力。如果有了统一网关层,那么也许只需要50台机器就可以做这100个业务的网关层的事,并且业务RD不需要随时关注开发,上线的步骤。
## 2.统一网关的设计
### 2.1 异步化请求
# 2.统一网关的设计
## 2.1 异步化请求
对于我们自己实现的网关层,由于只有我们自己使用,对于吞吐量的要求并不高所以,我们一般同步请求调用即可。
对于我们统一的网关层,如何用少量的机器接入更多的服务,这就需要我们的异步,用来提高更多的吞吐量。对于异步化一般有下面两种策略:
...
...
@@ -67,86 +60,83 @@ Netty为高并发而生,目前唯品会的网关使用这个策略,在唯品
对于网关是HTTP请求场景比较多的情况可以采用Servlet,毕竟有更加成熟的处理HTTP协议。如果更加重视吞吐量那么可以采用Netty。
#### 2.1.1 全链路异步
对于来的请求我们已经使用异步了,为了达到全链路异步所以我们需要对去的请求也进行异步处理,对于去的请求我们可以利用我们rpc的异步支持进行异步请求所以基本可以达到下图:
[

](https://camo.githubusercontent.com/ea78c61029cee6487f3aa0cecf5443f18d102173/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633837373331356535353761663f773d3133303026683d34383026663d706e6726733d3639323735)
由在web容器中开启servlet异步,然后进入到网关的业务线程池中进行业务处理,然后进行rpc的异步调用并注册需要回调的业务,最后在回调线程池中进行回调处理。

### 2.2 链式处理
由在web容器中开启servlet异步,然后进入到网关的业务线程池中进行业务处理,然后进行rpc的异步调用并注册需要回调的业务,最后在回调线程池中进行回调处理。
## 2.2 链式处理
在设计模式中有一个模式叫责任链模式,他的作用是避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。通过这种模式将请求的发送者和请求的处理者解耦了。在我们的各个框架中对此模式都有实现,比如servlet里面的filter,springmvc里面的Interceptor。
在Netflix Zuul中也应用了这种模式,如下图所示:
[

](https://camo.githubusercontent.com/22d9288d6e9137b98aef563ff7a5a76a090a4609/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633837383234303735333733353f773d39363026683d37323026663d706e6726733d343933313
4)

这种模式在网关的设计中我们可以借鉴到自己的网关设计:
-
preFilters:前置过滤器,用来处理一些公共的业务,比如统一鉴权,统一限流,熔断降级,缓存处理等,并且提供业务方扩展。
-
routingFilters: 用来处理一些泛化调用,主要是做协议的转换,请求的路由工作。
-
postFilters: 后置过滤器,主要用来做结果的处理,日志打点,记录时间等等。
-
errorFilters: 错误过滤器,用来处理调用异常的情况。
这种设计在有赞的网关也有应用。
### 2.3 业务隔离
## 2.3 业务隔离
上面在全链路异步的情况下不同业务之间的影响很小,但是如果在提供的自定义FiIlter中进行了某些同步调用,一旦超时频繁那么就会对其他业务产生影响。所以我们需要采用隔离之术,降低业务之间的互相影响。
#### 2.3.1 信号量隔离
信号量隔离只是限制了总的并发数,服务还是主线程进行同步调用。这个隔离如果远程调用超时依然会影响主线程,从而会影响其他业务。因此,如果只是想限制某个服务的总并发调用量或者调用的服务不涉及远程调用的话,可以使用轻量级的信号量来实现。有赞的网关由于没有自定义filter所以选取的是信号量隔离。
#### 2.3.2 线程池隔离
最简单的就是不同业务之间通过不同的线程池进行隔离,就算业务接口出现了问题由于线程池已经进行了隔离那么也不会影响其他业务。在京东的网关实现之中就是采用的线程池隔离,比较重要的业务比如商品或者订单 都是单独的通过线程池去处理。但是由于是统一网关平台,如果业务线众多,大家都觉得自己的业务比较重要需要单独的线程池隔离,如果使用的是Java语言开发的话那么,在Java中线程是比较重的资源比较受限,如果需要隔离的线程池过多不是很适用。如果使用一些其他语言比如Golang进行开发网关的话,线程是比较轻的资源,所以比较适合使用线程池隔离。
#### 2.3.3 集群隔离
如果有某些业务就需要使用隔离但是统一网关又没有线程池隔离那么应该怎么办呢?那么可以使用集群隔离,如果你的某些业务真的很重要那么可以为这一系列业务单独申请一个集群或者多个集群,通过机器之间进行隔离。
### 2.4 请求限流
## 2.4 请求限流
流量控制可以采用很多开源的实现,比如阿里最近开源的Sentinel和比较成熟的Hystrix。
一般限流分为集群限流和单机限流:
-
利用统一存储保存当前流量的情况,一般可以采用Redis,这个一般会有一些性能损耗。
-
单机限流:限流每台机器我们可以直接利用Guava的令牌桶去做,由于没有远程调用性能消耗较小。
### 2.5 熔断降级
## 2.5 熔断降级
这一块也可以参照开源的实现Sentinel和Hystrix,这里不是重点就不多提了。
### 2.6 泛化调用
## 2.6 泛化调用
泛化调用指的是一些通信协议的转换,比如将HTTP转换成Thrift。在一些开源的网关中比如Zuul是没有实现的,因为各个公司的内部服务通信协议都不同。比如在唯品会中支持HTTP1,HTTP2,以及二进制的协议,然后转化成内部的协议,淘宝的支持HTTPS,HTTP1,HTTP2这些协议都可以转换成,HTTP,HSF,Dubbo等协议。
#### 2.6.1泛化调用
如何去实现泛化调用呢?由于协议很难自动转换,那么其实每个协议对应的接口需要提供一种映射。简单来说就是把两个协议都能转换成共同语言,从而互相转换。
[

](https://camo.githubusercontent.com/d680a88d0dd9063fe53df26705836c4b7a19c121/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633838306163386264623537353f773d3133333826683d39363326663d706e6726733d3830313730)一般来说共同语言有三种方式指定:

一般来说共同语言有三种方式指定:
-
json:json数据格式比较简单,解析速度快,较轻量级。在Dubbo的生态中有一个HTTP转Dubbo的项目是用JsonRpc做的,将HTTP转化成JsonRpc再转化成Dubbo。
比如可以将一个
[
www.baidu.com/id
](
http://www.baidu.com/id
)
= 1 GET 可以映射为json:
比如可以将一个
www.baidu.com/id
= 1 GET 可以映射为json:
代码块
```
{
“method”: "getBaidu"
"param" : {
"id" : 1
}
}
```
-
xml:xml数据比较重,解析比较困难,这里不过多讨论。
-
自定义描述语言:一般来说这个成本比较高需要自己定义语言来进行描述并进行解析,但是其扩展性,自定义个性化性都是最高。例:spring自定义了一套自己的SPEL表达式语言
对于泛化调用如果要自己设计的话JSON基本可以满足,如果对于个性化的需要特别多的话倒是可以自己定义一套语言。
### 2.7 管理平台
## 2.7 管理平台
上面介绍的都是如何实现一个网关的技术关键。这里需要介绍网关的一个业务关键。有了网关之后,需要一个管理平台如何去对我们上面所描述的技术关键进行配置,包括但不限于下面这些配置:
-
限流
...
...
@@ -156,29 +146,34 @@ Netty为高并发而生,目前唯品会的网关使用这个策略,在唯品
-
自定义filter
-
泛化调用
## 3.总结
# 3.总结
最后一个合理的标准网关应该按照如下去实现:
[

](https://camo.githubusercontent.com/16eef64bd42ee7b2eb08c36039316fadb4e4d6b3/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633838343136633463633232373f773d3230313326683d3130303726663d706e6726733d31353236393
0)

| --- | 京东 | 唯品会 | 有赞 | 阿里 | Zuul |
| -------- | ------------------------------ | ----------------------------- | ----------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 实现关键 | servlet3.0 | netty | servlet3.0 | servlet3.0 | servlet3.0 |
| 异步情况 | servlet异步,rpc是否异步不清楚 | 全链路异步 | 全链路异步 | 全链路异步 | Zuul1同步阻塞,Zuul2异步非阻塞 |
| 限流 | --- | --- | 平滑限流。最初是codis,后续换到每个单机的令牌桶限流。 | 1.基本流控:基于API的QPS做限流。2.运营流控:支持APP流量包,APP+API+USER的流控33.大促流控:APP访问API的权重流控。阿里开源:Sentinel | 提供了jar包:spring-cloud-zuul-ratelimit。1.对请求的目标URL进行限流(例如:某个URL每分钟只允许调用多少次)。2.对客户端的访问IP进行限流(例如:某个IP每分钟只允许请求多少次)3.对某些特定用户或者用户组进行限流(例如:非VIP用户限制每分钟只允许调用100次某个API等)4.多维度混合的限流。此时,就需要实现一些限流规则的编排机制。与、或、非等关系。支持四种存储方式ConcurrentHashMap,Consul,Redis,数据库。 |
| 熔断降级 | --- | --- | Hystrix | --- | 只支持服务级别熔断,不支持URL级别。 |
| 隔离 | 线程池隔离 | --- | 信号量隔离 | --- | 线程池隔离,信号量隔离 |
| 缓存 | redis | --- | 二级缓存,本地缓存+Codis | HDCC 本地缓存,远程缓存,数据库 | 需要自己开发 |
| 泛化调用 | --- | http,https,http1,http2,二进制 | dubbo,http,nova | hsf,dubbo,http,https,http2,http1 | 只支持http |
---| 京东| 唯品会| 有赞| 阿里| Zuul
---|---|---|---|---|---
实现关键|servlet3.0|netty|servlet3.0|servlet3.0|servlet3.0
异步情况|servlet异步,rpc是否异步不清楚|全链路异步|全链路异步|全链路异步|Zuul1同步阻塞,Zuul2异步非阻塞
限流 |---|---|平滑限流。最初是codis,后续换到每个单机的令牌桶限流。|1.基本流控:基于API的QPS做限流。2.运营流控:支持APP流量包,APP+API+USER的流控33.大促流控:APP访问API的权重流控。阿里开源:Sentinel|提供了jar包:spring-cloud-zuul-ratelimit。1.对请求的目标URL进行限流(例如:某个URL每分钟只允许调用多少次)。2.对客户端的访问IP进行限流(例如:某个IP每分钟只允许请求多少次)3.对某些特定用户或者用户组进行限流(例如:非VIP用户限制每分钟只允许调用100次某个API等)4.多维度混合的限流。此时,就需要实现一些限流规则的编排机制。与、或、非等关系。支持四种存储方式ConcurrentHashMap,Consul,Redis,数据库。
熔断降级|---|---|Hystrix|---|只支持服务级别熔断,不支持URL级别。
隔离|线程池隔离|---|信号量隔离|---|线程池隔离,信号量隔离
缓存|redis|---|二级缓存,本地缓存+Codis|HDCC 本地缓存,远程缓存,数据库|需要自己开发
泛化调用|---|http,https,http1,http2,二进制|dubbo,http,nova|hsf,dubbo,http,https,http2,http1|只支持http
## 4.参考
# 4.参考
-
京东:http://www.yunweipai.com/archives/23653.html
-
有赞网关:https://tech.youzan.com/api-gateway-in-practice/
-
唯品会:https://mp.weixin.qq.com/s/gREMe-G7nqNJJLzbZ3ed3A
-
Zuul:http://www.scienjus.com/api-gateway-and-netflix-zuul/
## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
...
...
docs/system-design/micro-service/api-gateway-intro.md
0 → 100644
浏览文件 @
c6402cde
### 为什么要网关?
微服务下一个系统被拆分为多个服务,但是像 安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
综上:
**一般情况下,网关一般都会提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、容灾、日志、监控这些功能。**
上面介绍了这么多功能实际上网关主要做了一件事情:
**请求过滤**
。权限校验、流量控制这些都可以通过过滤器实现,请求转也是通过过滤器实现的。
### 你知道有哪些常见的网关系统?
我所了解的目前经常用到的开源 API 网关系统有:
1.
Kong
2.
Netflix zuul
下图来源:https://www.stackshare.io/stackups/kong-vs-zuul 。
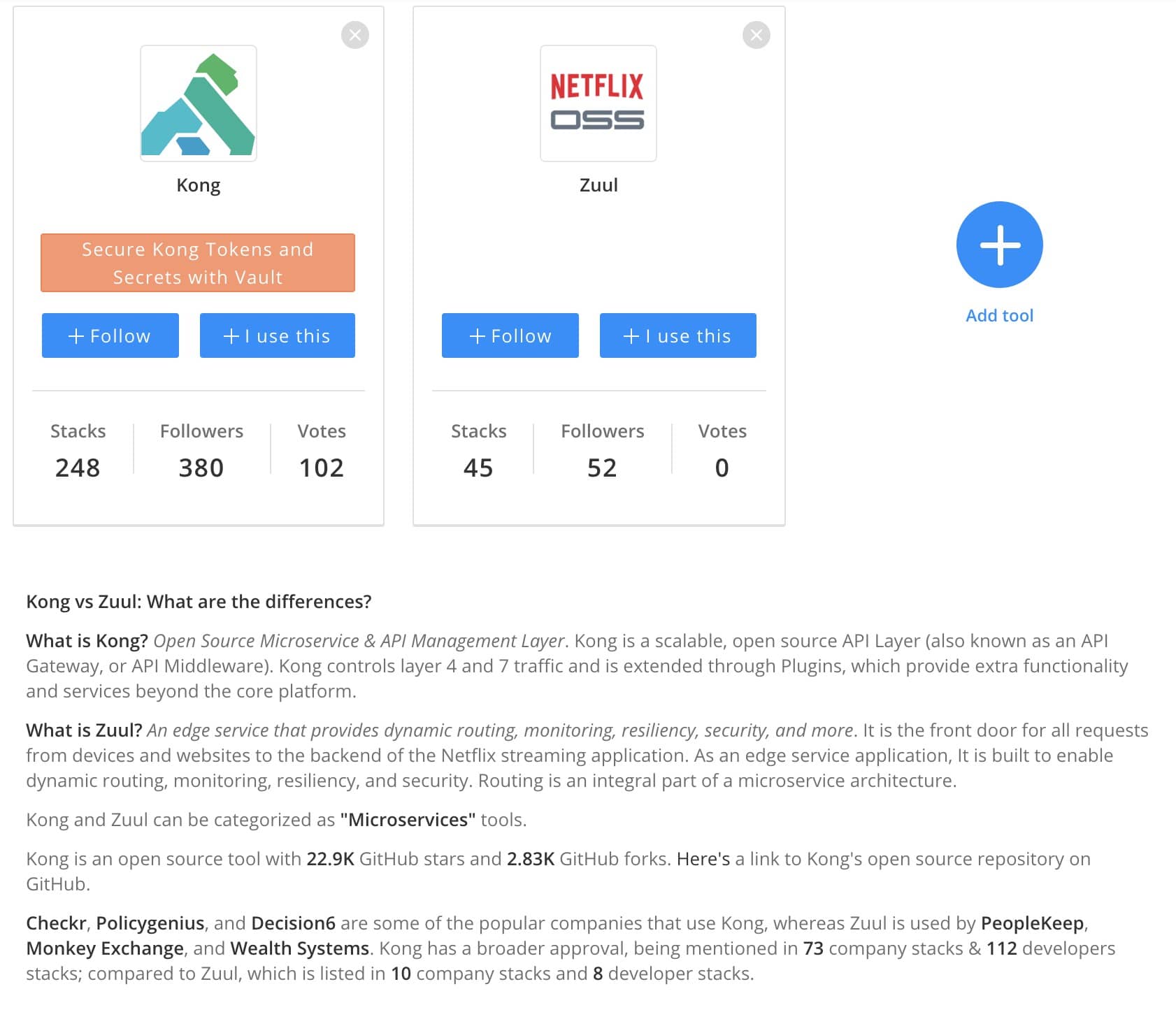
可以看出不论是社区活跃度还是 Star数, Kong 都是略胜一筹。总的来说,Kong 相比于 Zuul 更加强大并且简单易用。Kong 基于 Openresty ,Zuul 基于 Java。
> OpenResty(也称为 ngx_openresty)是一个全功能的 Web 应用服务器。它打包了标准的 Nginx 核心,很多的常用的第三方模块,以及它们的大多数依赖项。
>
> 通过揉和众多设计良好的 Nginx 模块,OpenResty 有效地把 Nginx 服务器转变为一个强大的 Web 应用服务器,基于它开发人员可以使用 Lua 编程语言对 Nginx 核心以及现有的各种 Nginx C 模块进行脚本编程,构建出可以处理一万以上并发请求的极端高性能的 Web 应用。——OpenResty
另外, Kong 还提供了插件机制来扩展其功能。
比如、在服务上启用 Zipkin 插件
```
shell
$
curl
-X
POST http://kong:8001/services/
{
service
}
/plugins
\
--data
"name=zipkin"
\
--data
"config.http_endpoint=http://your.zipkin.collector:9411/api/v2/spans"
\
--data
"config.sample_ratio=0.001"
```
ps:这里没有太深入去探讨,需要深入了解的话可以自行查阅相关资料。
\ No newline at end of file
docs/system-design/micro-service/limit-request.md
0 → 100644
浏览文件 @
c6402cde
### 限流的算法有哪些?
简单介绍 4 种非常好理解并且容易实现的限流算法!
下图的图片不是 Guide 哥自己画的哦!图片来源于 InfoQ 的一篇文章
[
《分布式服务限流实战,已经为你排好坑了》
](
https://www.infoq.cn/article/Qg2tX8fyw5Vt-f3HH673
)
。
#### 固定窗口计数器算法
规定我们单位时间处理的请求数量。比如我们规定我们的一个接口一分钟只能访问10次的话。使用固定窗口计数器算法的话可以这样实现:给定一个变量counter来记录处理的请求数量,当1分钟之内处理一个请求之后counter+1,1分钟之内的如果counter=100的话,后续的请求就会被全部拒绝。等到 1分钟结束后,将counter回归成0,重新开始计数(ps:只要过了一个周期就讲counter回归成0)。
这种限流算法无法保证限流速率,因而无法保证突然激增的流量。比如我们限制一个接口一分钟只能访问10次的话,前半分钟一个请求没有接收,后半分钟接收了10个请求。
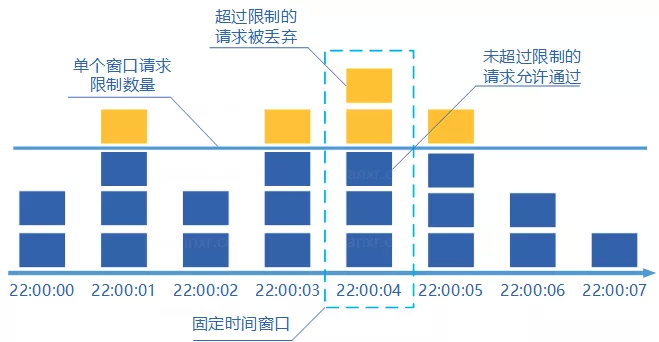
#### 滑动窗口计数器算法
算的上是固定窗口计数器算法的升级版。滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:它把时间以一定比例分片。例如我们的借口限流每分钟处理60个请求,我们可以把 1 分钟分为60个窗口。每隔1秒移动一次,每个窗口一秒只能处理 不大于 60(请求数)/60(窗口数) 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
很显然:当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
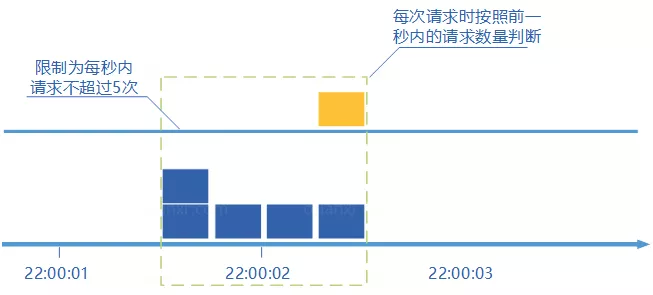
#### 漏桶算法
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了。
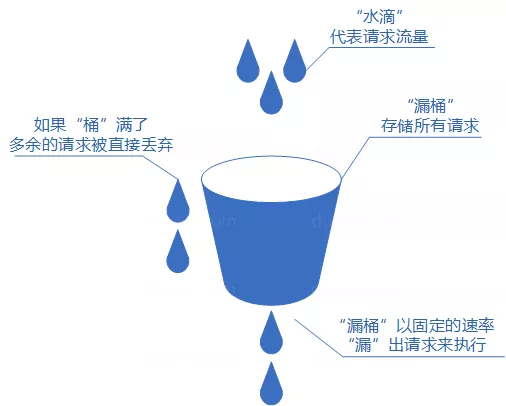
#### 令牌桶算法
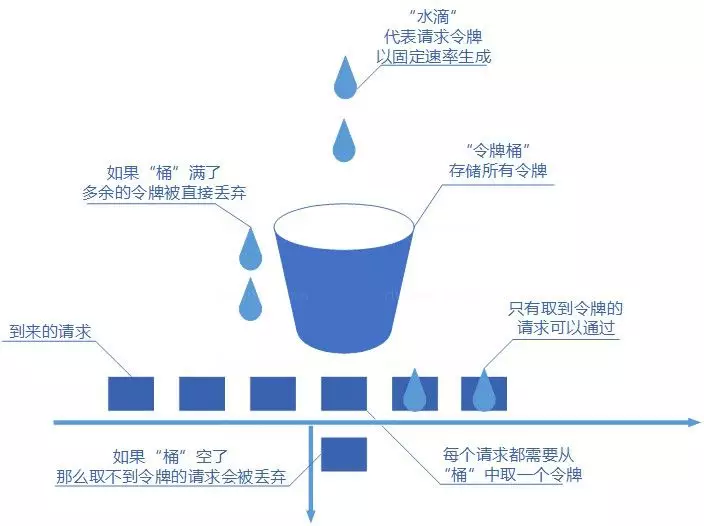
令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。
###
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录