Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
醒狮指南
JavaGuide
提交
dfc7c8d1
J
JavaGuide
项目概览
醒狮指南
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
5
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
dfc7c8d1
编写于
2月 05, 2021
作者:
N
nullptr
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
修改复制算法的描述为标记-复制算法
上级
9c1f032b
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
42 addition
and
37 deletion
+42
-37
docs/java/basis/代理模式详解.md
docs/java/basis/代理模式详解.md
+1
-1
docs/java/jvm/JVM垃圾回收.md
docs/java/jvm/JVM垃圾回收.md
+41
-36
未找到文件。
docs/java/basis/代理模式详解.md
浏览文件 @
dfc7c8d1
...
...
@@ -28,7 +28,7 @@
**代理模式的主要作用是扩展目标对象的功能,比如说在目标对象的某个方法执行前后你可以增加一些自定义的操作。**
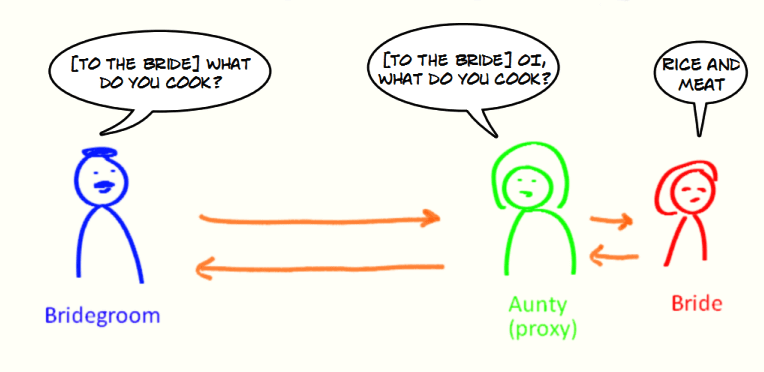
举个例子:你找了小红来帮你
文化
,小红就可以看作是代理你的代理对象,代理的行为(方法)是问话。
举个例子:你找了小红来帮你
问话
,小红就可以看作是代理你的代理对象,代理的行为(方法)是问话。
...
...
docs/java/jvm/JVM垃圾回收.md
浏览文件 @
dfc7c8d1
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
<!-- code_chunk_output -->
...
...
@@ -23,7 +21,7 @@
-
[
2.6 如何判断一个类是无用的类
](
#26-如何判断一个类是无用的类
)
-
[
3 垃圾收集算法
](
#3-垃圾收集算法
)
-
[
3.1 标记-清除算法
](
#31-标记-清除算法
)
-
[
3.2
复制算法
](
#32
-复制算法
)
-
[
3.2
标记-复制算法
](
#32-标记
-复制算法
)
-
[
3.3 标记-整理算法
](
#33-标记-整理算法
)
-
[
3.4 分代收集算法
](
#34-分代收集算法
)
-
[
4 垃圾收集器
](
#4-垃圾收集器
)
...
...
@@ -84,19 +82,22 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(G
>
> ```c++
> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
> //survivor_capacity是survivor空间的大小
> size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
> size_t total = 0;
> uint age = 1;
> while (age < table_size) {
> total += sizes[age];//sizes数组是每个年龄段对象大小
> if (total > desired_survivor_size) break;
> age++;
> }
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
> ...
> //survivor_capacity是survivor空间的大小
> size_t desired_survivor_size = (size_t)((((double)survivor_capacity)*TargetSurvivorRatio)/100);
> size_t total = 0;
> uint age = 1;
> while (age < table_size) {
> //sizes数组是每个年龄段对象大小
> total += sizes[age];
> if (total > desired_survivor_size) {
> break;
> }
> age++;
> }
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
> ...
> }
>
>
> ```
经过这次 GC 后,Eden 区和"From"区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的"To"就是上次 GC 前的“From”,新的"From"就是上次 GC 前的"To"。不管怎样,都会保证名为 To 的 Survivor 区域是空的。Minor GC 会一直重复这样的过程,直到“To”区被填满,"To"区被填满之后,会将所有对象移动到老年代中。
...
...
@@ -181,19 +182,22 @@ public class GCTest {
>
> ```c++
> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
> //survivor_capacity是survivor空间的大小
> size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
> size_t total = 0;
> uint age = 1;
> while (age < table_size) {
> total += sizes[age];//sizes数组是每个年龄段对象大小
> if (total > desired_survivor_size) break;
> age++;
> }
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
> ...
> //survivor_capacity是survivor空间的大小
> size_t desired_survivor_size = (size_t)((((double)survivor_capacity)*TargetSurvivorRatio)/100);
> size_t total = 0;
> uint age = 1;
> while (age < table_size) {
> //sizes数组是每个年龄段对象大小
> total += sizes[age];
> if (total > desired_survivor_size) {
> break;
> }
> age++;
> }
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
> ...
> }
>
>
> ```
>
> 额外补充说明([issue672](https://github.com/Snailclimb/JavaGuide/issues/672)):**关于默认的晋升年龄是 15,这个说法的来源大部分都是《深入理解 Java 虚拟机》这本书。**
...
...
@@ -225,7 +229,7 @@ public class GCTest {
## 2 对象已经死亡?
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断
那
些对象已经死亡(即不能再被任何途径使用的对象)。
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断
哪
些对象已经死亡(即不能再被任何途径使用的对象)。

...
...
@@ -262,6 +266,7 @@ public class ReferenceCountingGc {
-
本地方法栈(Native 方法)中引用的对象
-
方法区中类静态属性引用的对象
-
方法区中常量引用的对象
-
所有被同步锁持有的对象
### 2.3 再谈引用
...
...
@@ -342,9 +347,9 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引

### 3.2 复制算法
### 3.2
标记-
复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
为了解决效率问题,“
标记-
复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。

...
...
@@ -358,7 +363,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择
复制
算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择
”标记-复制“
算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
**延伸面试问题:**
HotSpot 为什么要分为新生代和老年代?
...
...
@@ -376,7 +381,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的
**“单线程”**
的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程(
**"Stop The World"**
),直到它收集结束。
**新生代采用复制算法,老年代采用标记-整理算法。**
**新生代采用
标记-
复制算法,老年代采用标记-整理算法。**

...
...
@@ -388,7 +393,7 @@ Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了
**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
**新生代采用复制算法,老年代采用标记-整理算法。**
**新生代采用
标记-
复制算法,老年代采用标记-整理算法。**

...
...
@@ -402,7 +407,7 @@ Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了
### 4.3 Parallel Scavenge 收集器
Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。
**那么它有什么特别之处呢?**
Parallel Scavenge 收集器也是使用
标记-
复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。
**那么它有什么特别之处呢?**
```
-XX:+UseParallelGC
...
...
@@ -417,7 +422,7 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。**
Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
**新生代采用复制算法,老年代采用标记-整理算法。**
**新生代采用
标记-
复制算法,老年代采用标记-整理算法。**

...
...
@@ -471,7 +476,7 @@ JDK1.8 默认使用的是 Parallel Scavenge + Parallel Old,如果指定了-XX:
-
**并行与并发**
:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
-
**分代收集**
:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
-
**空间整合**
:与 CMS 的“标记-
-清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“
复制”算法实现的。
-
**空间整合**
:与 CMS 的“标记-
清理”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器;从局部上来看是基于“标记-
复制”算法实现的。
-
**可预测的停顿**
:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
G1 收集器的运作大致分为以下几个步骤:
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录