Imported from upstream.
GitOrigin-RevId: 6da410412a6553831e89376f8d5a486edf768000
上级
Showing
.gitignore
0 → 100644
.vscode/settings.json
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
CONTRIBUTOR_LICENSE_AGREEMENT.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
gen_python_docs/gendoc.sh
0 → 100755
gen_python_docs/gendoc_zh.sh
0 → 100755
source/advanced/deployment.rst
0 → 100644
source/advanced/distributed.rst
0 → 100644
source/advanced/index.rst
0 → 100644
source/advanced/load_pytorch.rst
0 → 100644
source/advanced/sublinear.rst
0 → 100644
source/api.rst
0 → 100644
source/basic/basic_concepts.rst
0 → 100644
source/basic/data_load.rst
0 → 100644
source/basic/fig/back_prop.png
0 → 100644
{kind=link}
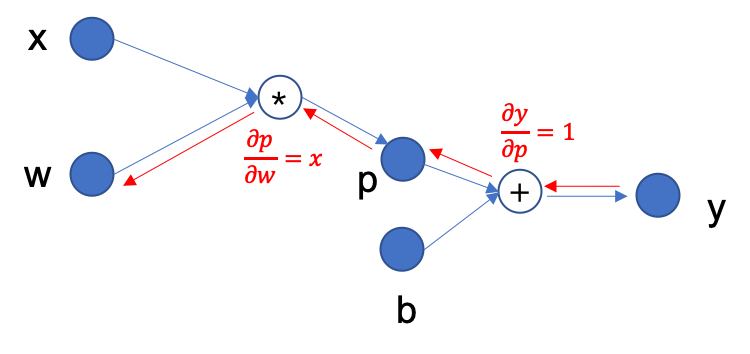
36.4 KB
{kind=link}
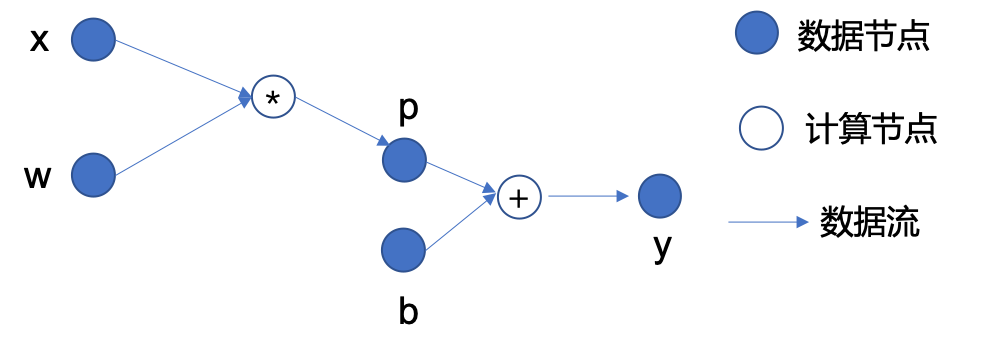
45.3 KB
source/basic/fig/dataset.png
0 → 100644
{kind=link}
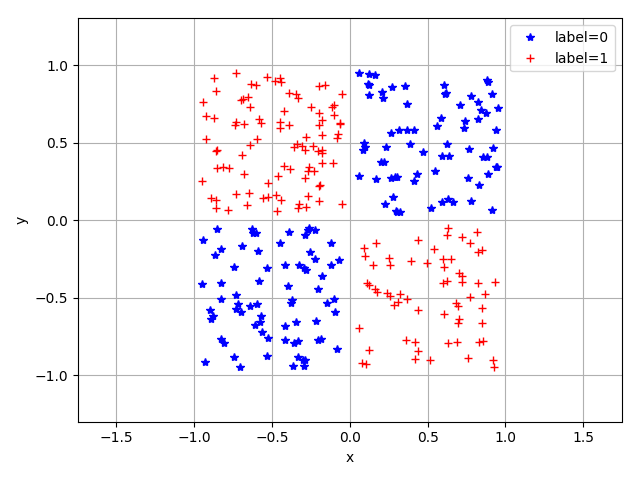
26.7 KB
source/basic/fig/lenet.jpg
0 → 100644
{kind=link}
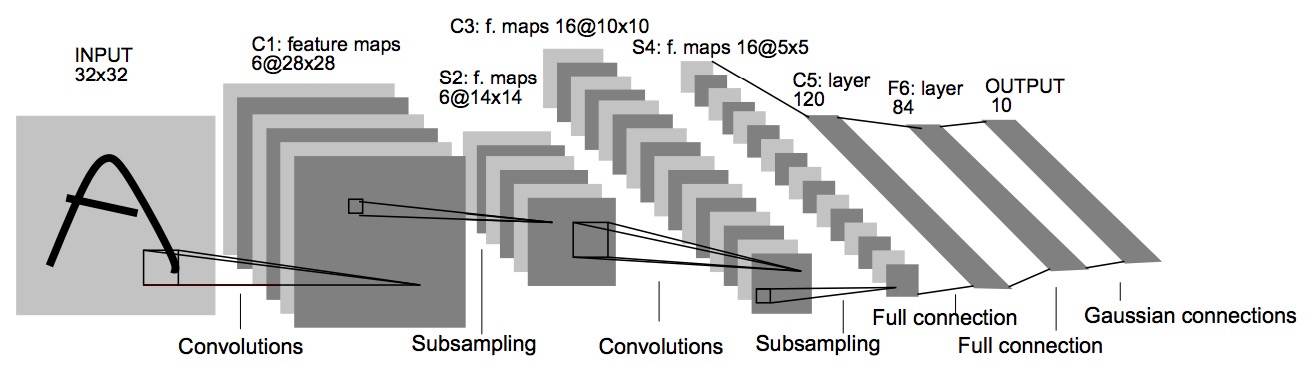
94.1 KB
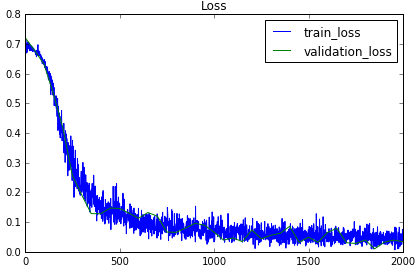
source/basic/fig/loss_curve.png
0 → 100644
{kind=link}
16.5 KB
source/basic/fig/mnist_aug.png
0 → 100644
{kind=link}

37.9 KB
source/basic/fig/mnist_batch.png
0 → 100644
{kind=link}
28.3 KB
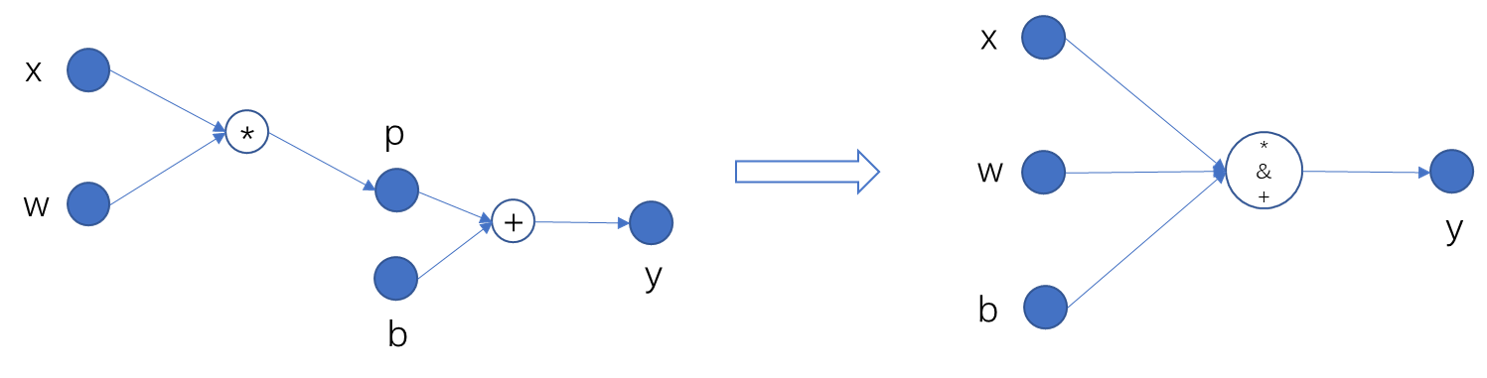
source/basic/fig/op_fuse.png
0 → 100755
{kind=link}
50.1 KB
source/basic/fig/plot_xor.jpg
0 → 100644
{kind=link}
16.0 KB
source/basic/fig/resnet-block.svg
0 → 100644
{kind=link}
此差异已折叠。
source/basic/fig/xor.png
0 → 100644
{kind=link}
39.6 KB
source/basic/index.rst
0 → 100644
source/basic/network_build.rst
0 → 100644
source/conf.py
0 → 100644
source/index.rst
0 → 100644