optimizater experiment
Showing
optimizer/README.md
0 → 100644
此差异已折叠。
optimizer/images/ada.png
0 → 100644
{kind=link}
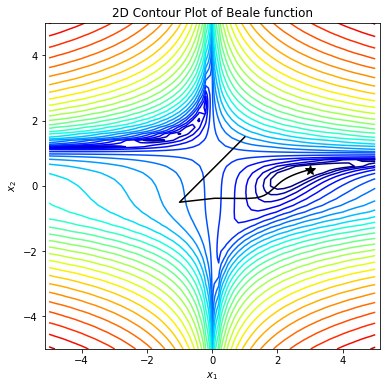
139.1 KB
optimizer/images/exp.png
0 → 100644
{kind=link}
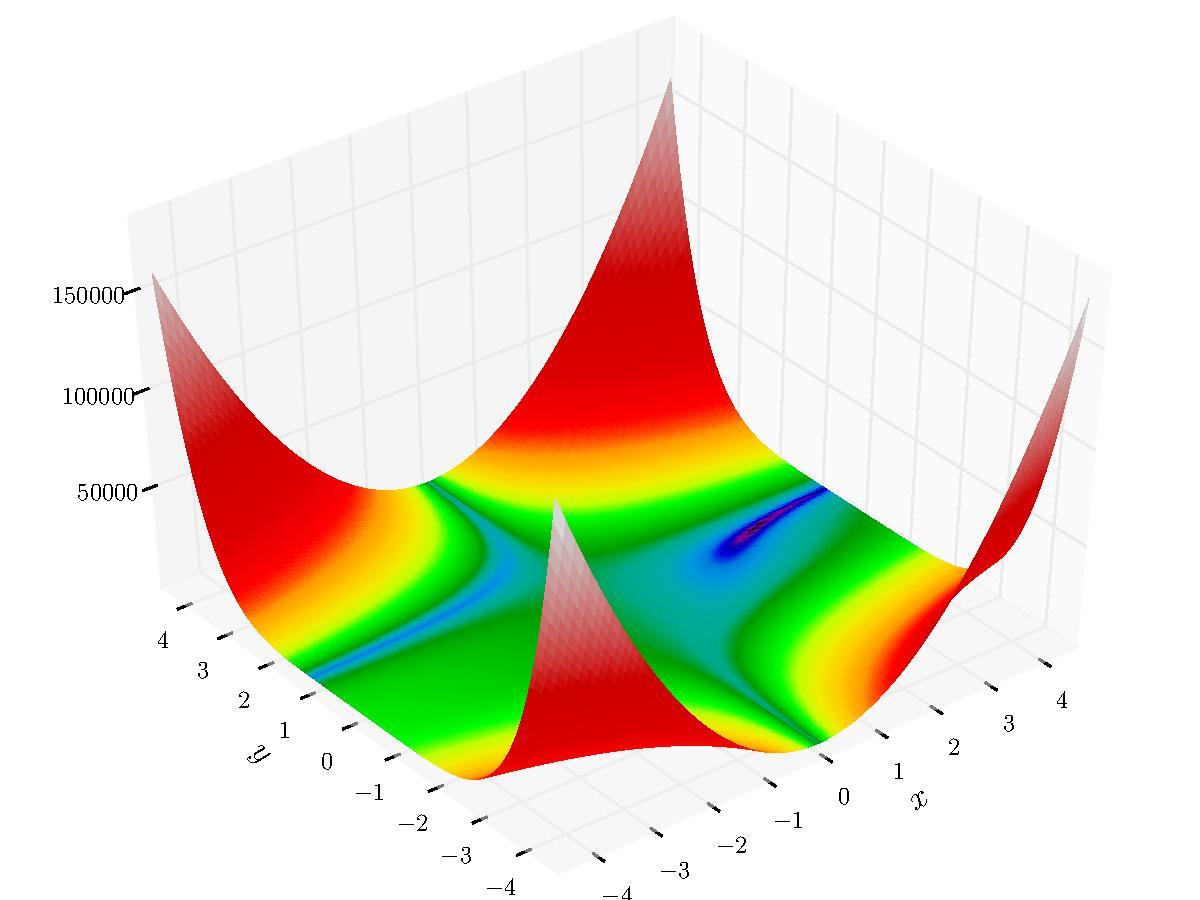
60.8 KB
optimizer/images/gold.png
0 → 100644
{kind=link}
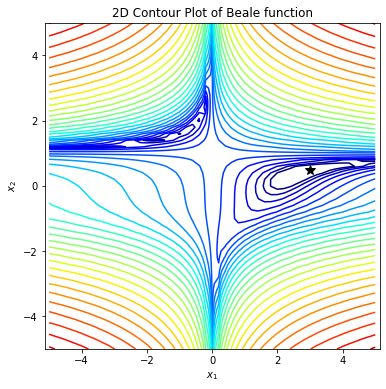
138.2 KB
optimizer/images/iris.png
0 → 100644
{kind=link}
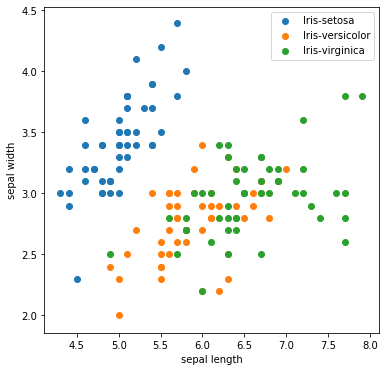
13.5 KB
optimizer/images/mom.png
0 → 100644
{kind=link}

141.2 KB
optimizer/images/sgd.png
0 → 100644
{kind=link}
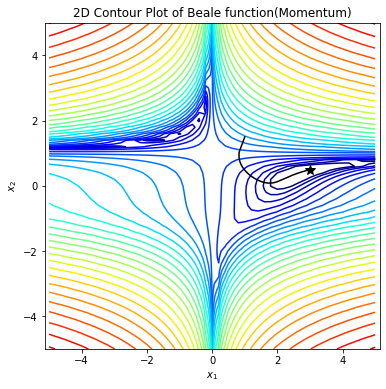
139.7 KB
optimizer/main1.py
0 → 100644
optimizer/main2.py
0 → 100644