Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
MindSpore
course
提交
d9198107
C
course
项目概览
MindSpore
/
course
通知
4
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
course
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
d9198107
编写于
5月 30, 2020
作者:
D
dyonghan
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
rm scripts in experiment_3, download instead; add pics
上级
90d94759
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
20 addition
and
271 deletion
+20
-271
experiment_3/3-Computer_Vision.md
experiment_3/3-Computer_Vision.md
+20
-13
experiment_3/dataset.py
experiment_3/dataset.py
+0
-86
experiment_3/images/resnet_archs.png
experiment_3/images/resnet_archs.png
+0
-0
experiment_3/images/resnet_block.png
experiment_3/images/resnet_block.png
+0
-0
experiment_3/resnet50_train.py
experiment_3/resnet50_train.py
+0
-172
未找到文件。
experiment_3/3-Computer_Vision.md
浏览文件 @
d9198107
...
...
@@ -2,7 +2,7 @@
## 实验介绍
本实验主要介绍使用MindSpore在CIFAR
10数据集上训练ResNet50。本实验建议使用MindSpore model_zoo中提供的ResNet50
。
本实验主要介绍使用MindSpore在CIFAR
-10数据集上训练ResNet50。本实验使用MindSpore model_zoo中提供的ResNet50模型定义,以及MindSpore官网教程
[
在云上使用MindSpore
](
https://www.mindspore.cn/tutorial/zh-CN/0.2.0-alpha/advanced_use/use_on_the_cloud.html
)
里的训练脚本
。
## 实验目的
...
...
@@ -42,7 +42,7 @@
### 数据集准备
CIFAR-10是一个图片分类数据集,包含60000张32x32的彩色物体图片,训练集50000张,测试集10000张,共10类,每类6000张。CIFAR-10数据集的官网:
[
T
HE MNIST DATABASE
](
http://www.cs.toronto.edu/~kriz/cifar.html
)
。
CIFAR-10是一个图片分类数据集,包含60000张32x32的彩色物体图片,训练集50000张,测试集10000张,共10类,每类6000张。CIFAR-10数据集的官网:
[
T
he CIFAR-10 and CIFAR-100 datasets
](
http://www.cs.toronto.edu/~kriz/cifar.html
)
。
从CIFAR-10官网下载“CIFAR-10 binary version (suitable for C programs)”到本地并解压。
...
...
@@ -56,7 +56,8 @@ CIFAR-10是一个图片分类数据集,包含60000张32x32的彩色物体图
```
experiment_3
├── 脚本等文件
├── dataset.py
├── resnet50_train.py
└── cifar10
├── batches.meta.txt
├── eval
...
...
@@ -71,8 +72,6 @@ experiment_3
## 实验步骤
参考MindSpore官网
[
在云上使用MindSpore
](
https://www.mindspore.cn/tutorial/zh-CN/0.2.0-alpha/advanced_use/use_on_the_cloud.html
)
。
### 代码梳理
-
resnet50_train.py:主脚本,包含性能测试
`PerformanceCallback`
、动态学习率
`get_lr`
、执行函数
`resnet50_train`
等函数;
...
...
@@ -154,7 +153,7 @@ def get_lr(global_step,
return
learning_rate
```
MindSpore支持直接读取
cifar
10数据集:
MindSpore支持直接读取
CIFAR-
10数据集:
```
python
if
device_num
==
1
or
not
do_train
:
...
...
@@ -221,7 +220,15 @@ class ResNet(nn.Cell):
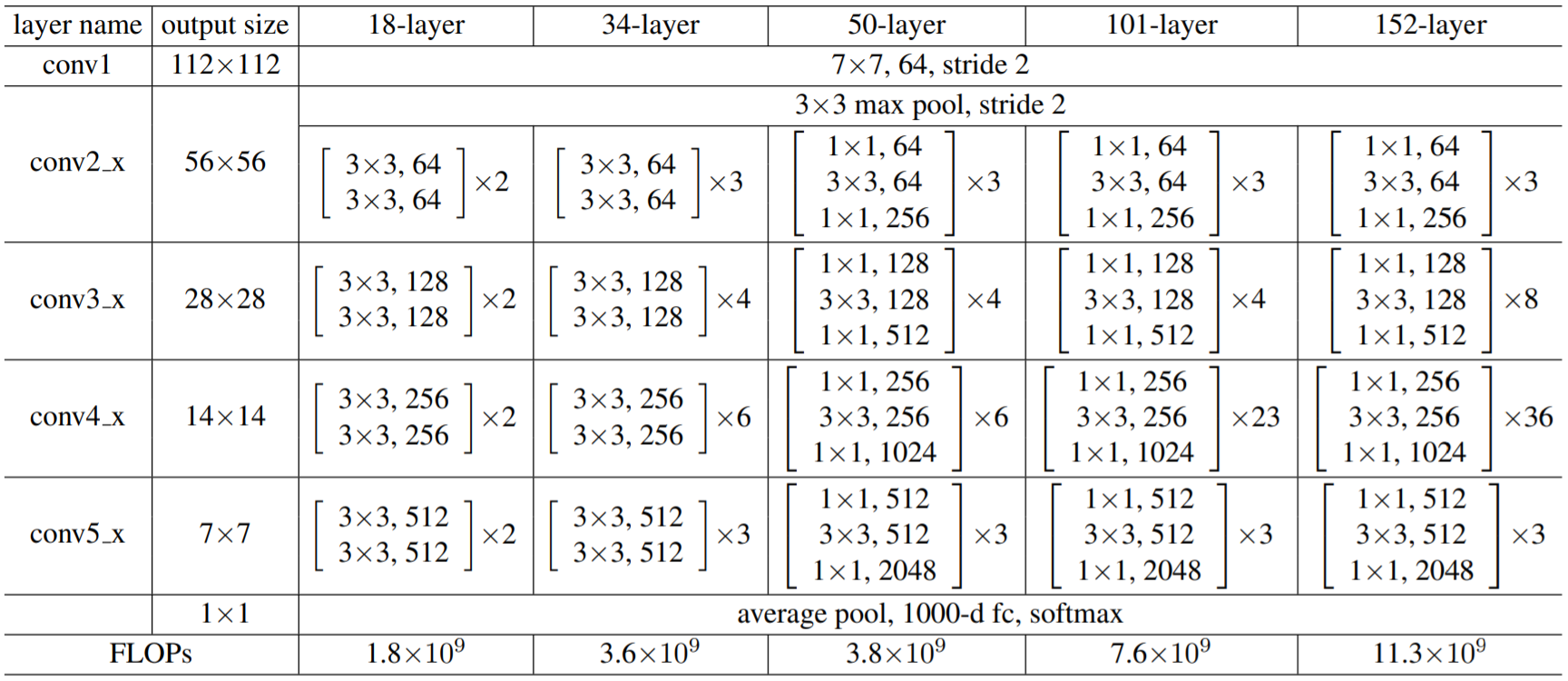
ResNet的不同版本均由5个阶段(stage)组成,其中ResNet50结构为Convx1 -> ResidualBlockx3 -> ResidualBlockx4 -> ResidualBlockx6 -> ResidualBlockx5 -> Pooling+FC。
`ResidualBlock`
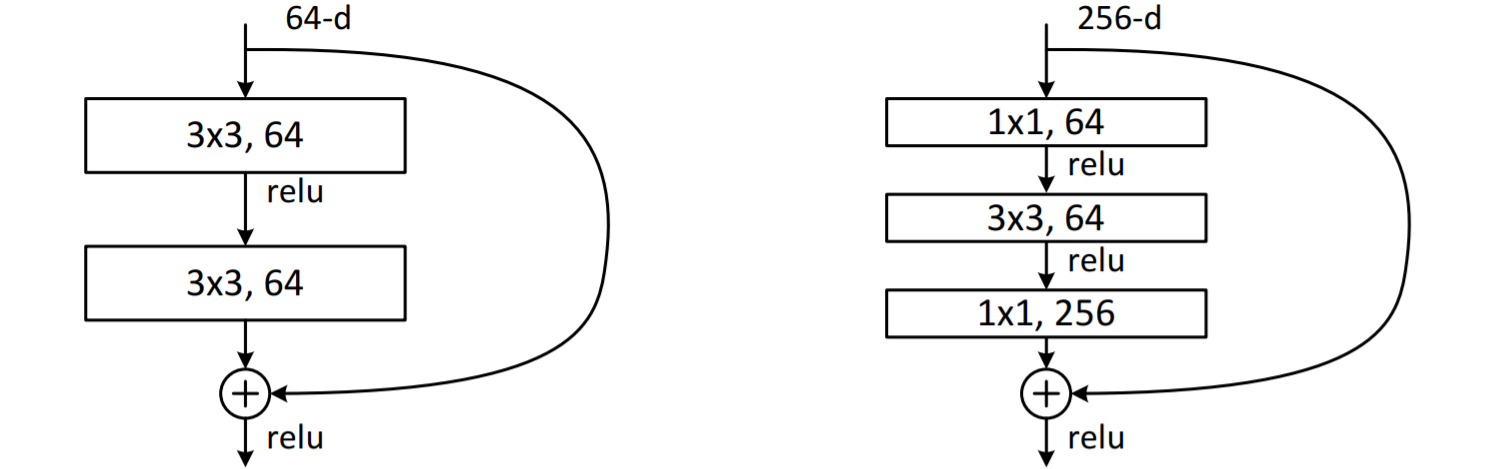
为残差模块,相比传统卷积多了一个short-cut支路,用于将浅层的信息直接传递到深层,使得网络可以很深,而不会出现训练时梯度消失/爆炸的问题:

[1] 图片来源于https://arxiv.org/pdf/1512.03385.pdf
`ResidualBlock`
为残差模块,相比传统卷积多了一个short-cut支路,用于将浅层的信息直接传递到深层,使得网络可以很深,而不会出现训练时梯度消失/爆炸的问题。ResNet50采用了下图右侧Bottleneck形式的残差模块:

[2] 图片来源于https://arxiv.org/pdf/1512.03385.pdf
```
python
class
ResidualBlock
(
nn
.
Cell
):
...
...
@@ -245,7 +252,6 @@ class ResidualBlock(nn.Cell):
self
.
relu
=
nn
.
ReLU
()
# 如果in
self
.
down_sample
=
False
if
stride
!=
1
or
in_channel
!=
out_channel
:
self
.
down_sample
=
True
...
...
@@ -269,6 +275,7 @@ class ResidualBlock(nn.Cell):
out
=
self
.
conv3
(
out
)
out
=
self
.
bn3
(
out
)
# ResNet50未使用带有下采样的残差支路
if
self
.
down_sample
:
identity
=
self
.
down_sample_layer
(
identity
)
...
...
@@ -330,9 +337,9 @@ mox.file.copy_parallel(src_url='output', dst_url='s3://OBS/PATH')
## 实验结论
本实验主要介绍使用MindSpore在CIFAR10数据集上训练ResNet50,了解了以下知识点:
本实验主要介绍使用MindSpore在CIFAR
-
10数据集上训练ResNet50,了解了以下知识点:
-
性能测试
-
动态学习率
-
model_zoo:resnet50
-
cifar10数据集、数据增强
-
使用自定义Callback实现性能监测;
-
使用动态学习率提升训练效果;
-
加载CIFAR-10数据集、数据增强;
-
ResNet50模型的结构及其MindSpore实现。
experiment_3/dataset.py
已删除
100644 → 0
浏览文件 @
90d94759
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
"""Create train or eval dataset."""
import
os
import
mindspore.common.dtype
as
mstype
import
mindspore.dataset.engine
as
de
import
mindspore.dataset.transforms.vision.c_transforms
as
C
import
mindspore.dataset.transforms.c_transforms
as
C2
device_id
=
int
(
os
.
getenv
(
'DEVICE_ID'
))
device_num
=
int
(
os
.
getenv
(
'RANK_SIZE'
))
def
create_dataset
(
dataset_path
,
do_train
,
repeat_num
=
1
,
batch_size
=
32
):
"""
Create a train or eval dataset.
Args:
dataset_path (str): The path of dataset.
do_train (bool): Whether dataset is used for train or eval.
repeat_num (int): The repeat times of dataset. Default: 1.
batch_size (int): The batch size of dataset. Default: 32.
Returns:
Dataset.
"""
if
do_train
:
dataset_path
=
os
.
path
.
join
(
dataset_path
,
'train'
)
do_shuffle
=
True
else
:
dataset_path
=
os
.
path
.
join
(
dataset_path
,
'eval'
)
do_shuffle
=
False
if
device_num
==
1
or
not
do_train
:
ds
=
de
.
Cifar10Dataset
(
dataset_path
,
num_parallel_workers
=
8
,
shuffle
=
do_shuffle
)
else
:
ds
=
de
.
Cifar10Dataset
(
dataset_path
,
num_parallel_workers
=
8
,
shuffle
=
do_shuffle
,
num_shards
=
device_num
,
shard_id
=
device_id
)
resize_height
=
224
resize_width
=
224
buffer_size
=
100
rescale
=
1.0
/
255.0
shift
=
0.0
# define map operations
random_crop_op
=
C
.
RandomCrop
((
32
,
32
),
(
4
,
4
,
4
,
4
))
random_horizontal_flip_op
=
C
.
RandomHorizontalFlip
(
device_id
/
(
device_id
+
1
))
resize_op
=
C
.
Resize
((
resize_height
,
resize_width
))
rescale_op
=
C
.
Rescale
(
rescale
,
shift
)
normalize_op
=
C
.
Normalize
([
0.4914
,
0.4822
,
0.4465
],
[
0.2023
,
0.1994
,
0.2010
])
change_swap_op
=
C
.
HWC2CHW
()
trans
=
[]
if
do_train
:
trans
+=
[
random_crop_op
,
random_horizontal_flip_op
]
trans
+=
[
resize_op
,
rescale_op
,
normalize_op
,
change_swap_op
]
type_cast_op
=
C2
.
TypeCast
(
mstype
.
int32
)
ds
=
ds
.
map
(
input_columns
=
"label"
,
num_parallel_workers
=
8
,
operations
=
type_cast_op
)
ds
=
ds
.
map
(
input_columns
=
"image"
,
num_parallel_workers
=
8
,
operations
=
trans
)
# apply batch operations
ds
=
ds
.
batch
(
batch_size
,
drop_remainder
=
True
)
# apply dataset repeat operation
ds
=
ds
.
repeat
(
repeat_num
)
return
ds
experiment_3/images/resnet_archs.png
0 → 100644
浏览文件 @
d9198107
357.2 KB
experiment_3/images/resnet_block.png
0 → 100644
浏览文件 @
d9198107
82.2 KB
experiment_3/resnet50_train.py
已删除
100644 → 0
浏览文件 @
90d94759
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
"""ResNet50 model train with MindSpore"""
import
os
import
argparse
import
random
import
time
import
numpy
as
np
import
moxing
as
mox
from
mindspore
import
context
from
mindspore
import
Tensor
from
mindspore.nn.optim.momentum
import
Momentum
from
mindspore.nn.loss
import
SoftmaxCrossEntropyWithLogits
from
mindspore.train.model
import
Model
,
ParallelMode
from
mindspore.train.callback
import
Callback
,
LossMonitor
from
mindspore.train.loss_scale_manager
import
FixedLossScaleManager
import
mindspore.dataset.engine
as
de
from
dataset
import
create_dataset
,
device_id
,
device_num
from
mindspore.model_zoo.resnet
import
resnet50
random
.
seed
(
1
)
np
.
random
.
seed
(
1
)
de
.
config
.
set_seed
(
1
)
class
PerformanceCallback
(
Callback
):
"""
Training performance callback.
Args:
batch_size (int): Batch number for one step.
"""
def
__init__
(
self
,
batch_size
):
super
(
PerformanceCallback
,
self
).
__init__
()
self
.
batch_size
=
batch_size
self
.
last_step
=
0
self
.
epoch_begin_time
=
0
def
step_begin
(
self
,
run_context
):
self
.
epoch_begin_time
=
time
.
time
()
def
step_end
(
self
,
run_context
):
params
=
run_context
.
original_args
()
cost_time
=
time
.
time
()
-
self
.
epoch_begin_time
train_steps
=
params
.
cur_step_num
-
self
.
last_step
print
(
f
'epoch
{
params
.
cur_epoch_num
}
cost time =
{
cost_time
}
, train step num:
{
train_steps
}
, '
f
'one step time:
{
1000
*
cost_time
/
train_steps
}
ms, '
f
'train samples per second of cluster:
{
device_num
*
train_steps
*
self
.
batch_size
/
cost_time
:.
1
f
}
\n
'
)
self
.
last_step
=
run_context
.
original_args
().
cur_step_num
def
get_lr
(
global_step
,
total_epochs
,
steps_per_epoch
,
lr_init
=
0.01
,
lr_max
=
0.1
,
warmup_epochs
=
5
):
"""
Generate learning rate array.
Args:
global_step (int): Initial step of training.
total_epochs (int): Total epoch of training.
steps_per_epoch (float): Steps of one epoch.
lr_init (float): Initial learning rate. Default: 0.01.
lr_max (float): Maximum learning rate. Default: 0.1.
warmup_epochs (int): The number of warming up epochs. Default: 5.
Returns:
np.array, learning rate array.
"""
lr_each_step
=
[]
total_steps
=
steps_per_epoch
*
total_epochs
warmup_steps
=
steps_per_epoch
*
warmup_epochs
if
warmup_steps
!=
0
:
inc_each_step
=
(
float
(
lr_max
)
-
float
(
lr_init
))
/
float
(
warmup_steps
)
else
:
inc_each_step
=
0
for
i
in
range
(
int
(
total_steps
)):
if
i
<
warmup_steps
:
lr
=
float
(
lr_init
)
+
inc_each_step
*
float
(
i
)
else
:
base
=
(
1.0
-
(
float
(
i
)
-
float
(
warmup_steps
))
/
(
float
(
total_steps
)
-
float
(
warmup_steps
))
)
lr
=
float
(
lr_max
)
*
base
*
base
if
lr
<
0.0
:
lr
=
0.0
lr_each_step
.
append
(
lr
)
current_step
=
global_step
lr_each_step
=
np
.
array
(
lr_each_step
).
astype
(
np
.
float32
)
learning_rate
=
lr_each_step
[
current_step
:]
return
learning_rate
def
resnet50_train
(
args_opt
):
epoch_size
=
args_opt
.
epoch_size
batch_size
=
32
class_num
=
10
loss_scale_num
=
1024
local_data_path
=
'/cache/data'
# set graph mode and parallel mode
context
.
set_context
(
mode
=
context
.
GRAPH_MODE
,
device_target
=
"Ascend"
,
save_graphs
=
False
)
context
.
set_context
(
enable_task_sink
=
True
,
device_id
=
device_id
)
context
.
set_context
(
enable_loop_sink
=
True
)
context
.
set_context
(
enable_mem_reuse
=
True
)
if
device_num
>
1
:
context
.
set_auto_parallel_context
(
device_num
=
device_num
,
parallel_mode
=
ParallelMode
.
DATA_PARALLEL
,
mirror_mean
=
True
)
local_data_path
=
os
.
path
.
join
(
local_data_path
,
str
(
device_id
))
# data download
print
(
'Download data.'
)
mox
.
file
.
copy_parallel
(
src_url
=
args_opt
.
data_url
,
dst_url
=
local_data_path
)
# create dataset
print
(
'Create train and evaluate dataset.'
)
train_dataset
=
create_dataset
(
dataset_path
=
local_data_path
,
do_train
=
True
,
repeat_num
=
epoch_size
,
batch_size
=
batch_size
)
eval_dataset
=
create_dataset
(
dataset_path
=
local_data_path
,
do_train
=
False
,
repeat_num
=
1
,
batch_size
=
batch_size
)
train_step_size
=
train_dataset
.
get_dataset_size
()
print
(
'Create dataset success.'
)
# create model
net
=
resnet50
(
class_num
=
class_num
)
loss
=
SoftmaxCrossEntropyWithLogits
(
sparse
=
True
)
lr
=
Tensor
(
get_lr
(
global_step
=
0
,
total_epochs
=
epoch_size
,
steps_per_epoch
=
train_step_size
))
opt
=
Momentum
(
net
.
trainable_params
(),
lr
,
momentum
=
0.9
,
weight_decay
=
1e-4
,
loss_scale
=
loss_scale_num
)
loss_scale
=
FixedLossScaleManager
(
loss_scale_num
,
False
)
model
=
Model
(
net
,
loss_fn
=
loss
,
optimizer
=
opt
,
loss_scale_manager
=
loss_scale
,
metrics
=
{
'acc'
})
# define performance callback to show ips and loss callback to show loss for every epoch
performance_cb
=
PerformanceCallback
(
batch_size
)
loss_cb
=
LossMonitor
()
cb
=
[
performance_cb
,
loss_cb
]
print
(
f
'Start run training, total epoch:
{
epoch_size
}
.'
)
model
.
train
(
epoch_size
,
train_dataset
,
callbacks
=
cb
)
if
device_num
==
1
or
device_id
==
0
:
print
(
f
'Start run evaluation.'
)
output
=
model
.
eval
(
eval_dataset
)
print
(
f
'Evaluation result:
{
output
}
.'
)
if
__name__
==
'__main__'
:
parser
=
argparse
.
ArgumentParser
(
description
=
'ResNet50 train.'
)
parser
.
add_argument
(
'--data_url'
,
required
=
True
,
default
=
None
,
help
=
'Location of data.'
)
parser
.
add_argument
(
'--train_url'
,
required
=
True
,
default
=
None
,
help
=
'Location of training outputs.'
)
parser
.
add_argument
(
'--epoch_size'
,
type
=
int
,
default
=
90
,
help
=
'Train epoch size.'
)
args_opt
,
unknown
=
parser
.
parse_known_args
()
resnet50_train
(
args_opt
)
print
(
'ResNet50 training success!'
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}